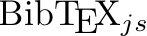Accueil
A propos
Missions
Membres
Fonctionnement
Services
Calcul et Stockage
Accompagnement
Formation
€
Tarification
galaxy.prabi.fr
virhostnet.prabi.fr
paraload
Projets
Projets réalisés
Equipes projets
Reproducible Science
Publications
Contact
Publications in peer reviewed journals acknowledging CC LBBE PRABI-AMSB and bioinformatics support
@article{Portanier2022a, abstract = {Understanding landscape impacts on gene flow is necessary to plan comprehensive management and conservation strategies of both the species of interest and its habitat. Nevertheless, only a few studies have focused on the landscape genetic connectivity of the European wildcat, an umbrella species whose conservation allows the preservation of numerous other species and habitat types. We applied population and landscape genetics approaches, using genotypes at 30 microsatellites from 232 genetically-identified wildcats to determine if, and how, landscape impacted gene flow throughout France. Analyses were performed independently within two population patches: the historical north-eastern patch and the central patch considered as the colonization front. Our results showed that gene flow occurred at large spatial scales but also revealed significant spatial genetic structures within population patches. In both population patches, arable areas, pastures and permanent grasslands and lowly fragmented forested areas were permeable to gene flow, suggesting that shelters and dietary resources are among the most important parameters for French wildcat landscape connectivity, while distance to forest had no detectable effect. Anthropized areas appeared highly resistant in the north-eastern patch but highly permeable in the central patch, suggesting that different behaviours can be observed according to the demographic context in which populations are found. In line with this hypothesis, spatial distribution of genetic variability seemed uneven in the north-eastern patch and more clinal in the central patch. Overall, our results highlighted that European wildcat might be a habitat generalist species and also the importance of performing spatial replication in landscape genetics studies.}, author = {Portanier, Elodie and L{\'{e}}ger, Fran{\c{c}}ois and Henry, Laurence and Gayet, Thibault and Queney, Guillaume and Ruette, Sandrine and Devillard, S{\'{e}}bastien}, doi = {10.1007/s10592-022-01443-9}, issn = {1566-0621}, journal = {Conservation Genetics}, keywords = {Animal Genetics and Genomics,Biodiversity,Conservation Biology/Ecology,Ecology,Evolutionary Biology,Plant Genetics and Genomics}, month = {mar}, pages = {1--16}, publisher = {Springer}, title = {{Landscape genetic connectivity in European wildcat (Felis silvestris silvestris): a matter of food, shelters and demographic status of populations}}, url = {https://link.springer.com/10.1007/s10592-022-01443-9}, year = {2022} } @article{Ratier2022, abstract = {1. ‘rbioacc' is an ‘R'-package dedicated to the analysis of experimental data collected from bioaccumulation tests during which organisms are exposed to a chemical (exposure phase) and then put into a clean media (depuration phase). Internal concentrations are regularly measured over time all along the experiment. 2. ‘rbioacc' provides ready-to-use functions to visualize and fully analyze such data. Under a Bayesian framework, this package fits a generic one-compartment toxicokinetic (TK) model automatically built from the data. It provides TK parameter estimates (appropriate uptake and elimination rates) and bioaccumulation metrics (e.g., BCF, BSAF, BMF). All parameter estimates, bioaccumulation metrics as well as predictions of internal concentrations into organisms are delivered with their uncertainty. 3. Bioaccumulation metrics are primarily provided in support of environmental risk assessment, in full compliance with regulatory requirements required to approve marketing applications of chemical substances. 4. This paper gives brief worked examples of the use of ‘rbioacc' from data collected through standard bioaccumulation tests, and publicly available within the scientific literature. These examples constitute step-by-step user-guides to analyze any new data set, uploaded in the right format. {\#}{\#}{\#} Competing Interest Statement The authors have declared no competing interest.}, author = {Ratier, A and Baudrot, V and Kaag, M and Siberchicot, A and Lopes, C and Charles, S}, doi = {10.1101/2021.09.08.459421}, file = {:Users/navratil/Documents/Mendeley Desktop/2022/Ratier et al/bioRxiv/bioRxiv{\_}Ratier et al.{\_}`rbioacc` an`R`-an`R`-package to analyze toxicokinetic data{\_}2022.pdf:pdf}, journal = {bioRxiv}, month = {jan}, pages = {2021.09.08.459421}, publisher = {Cold Spring Harbor Laboratory}, title = {{`rbioacc`: an`R`-an`R`-package to analyze toxicokinetic data}}, url = {https://doi.org/10.1101/2021.09.08.459421}, year = {2022} } @article{Rigoudy2022, author = {Rigoudy, Noa and Benyoub, Abdelbaki and Besnard, Aur{\'{e}}lien and Birck, Carole and Bollet, Yoann and Bunz, Yoann and {De Backer}, Nina and Caussimont, G{\'{e}}rard and Delestrade, Anne and Dispan, Lucie and Elder, Jean-Fran{\c{c}}ois and Fanjul, Jean-Baptiste and Fonderflick, Jocelyn and Garel, Mathieu and Gaudry, William and G{\'{e}}rard, Agathe and Gimenez, Olivier and Hemery, Arzhela and Hemon, Audrey and Jullien, Jean-Michel and {Le Barh}, Maden and Malafosse, Isabelle and Randon, Malory and Ribi{\`{e}}re, Romain and Ruette, Sandrine and Terpereau, Guillaume and Thuiller, Wilfried and Vautrain, Valentin and Spataro, Bruno and Miele, Vincent and Chamaill{\'{e}}-Jammes, Simon}, journal = {bioRxiv}, title = {{The DeepFaune initiative: a collaborative effort towards the automatic identification of the French fauna in camera-trap images}}, year = {2022} } @article{Laverre2022, abstract = {Gene expression is regulated through complex molecular interactions, involving cis-acting elements that can be situated far away from their target genes. Data on long-range contacts between promoters and regulatory elements are rapidly accumulating. However, it remains unclear how these regulatory relationships evolve and how they contribute to the establishment of robust gene expression profiles. Here, we address these questions by comparing genome-wide maps of promoter-centered chromatin contacts in mouse and human. We show that there is significant evolutionary conservation of cis-regulatory landscapes, indicating that selective pressures act to preserve not only regulatory element sequences but also their chromatin contacts with target genes. The extent of evolutionary conservation is remarkable for long-range promoter-enhancer contacts, illustrating how the structure of regulatory landscapes constrains large-scale genome evolution. We show that the evolution of cis-regulatory landscapes, measured in terms of distal element sequences, synteny, or contacts with target genes, is significantly associated with gene expression evolution.}, author = {Laverr{\'{e}}, Alexandre and Tannier, Eric and Necsulea, Anamaria}, doi = {10.1101/gr.275901.121}, issn = {15495469}, journal = {Genome research}, number = {2}, pages = {280--296}, pmid = {34930799}, title = {{Long-range promoter-enhancer contacts are conserved during evolution and contribute to gene expression robustness}}, url = {https://genome.cshlp.org/content/32/2/280.short}, volume = {32}, year = {2022} } @article{GalvaoFerrarini2022, abstract = {Motivation: The increasing availability of metabolomic data and their analysis are improving the understanding of cellular mechanisms and how biological systems respond to different perturbations. Currently, there is a need for novel computational methods that facilitate the analysis and integration of increasing volume of available data. Results: In this paper, we present TOTORO a new constraint-based approach that integrates quantitative non-targeted metabolomic data of two different metabolic states into genome-wide metabolic models and predicts reactions that were most likely active during the transient state. We applied TOTORO to real data of three different growth experiments (pulses of glucose, pyruvate, succinate) from Escherichia coli and we were able to predict known active pathways and gather new insights on the different metabolisms related to each substrate. We used both the E. coli core and the iJO1366 models to demonstrate that our approach is applicable to both smaller and larger networks. Availability: TOTORO is an open source method (available at https://gitlab.inria.fr/erable/ totoro) suitable for any organism with an available metabolic model. It is implemented in C++ and depends on IBM CPLEX which is freely available for academic purposes.}, author = {{Galv{\~{a}}o Ferrarini}, Mariana and Ziska, Irene and Andrade, Ricardo and Julien-Laferri{\`{e}}re, Alice and Duchemin, Louis and {Marcondes C{\'{e}}sar}, Roberto and Mary, Arnaud and Vinga, Susana and Sagot, Marie-France and {Marcondes C{\'{e}}sar Jr}, Roberto}, doi = {10.3389/fgene.2022.815476ï}, file = {:Users/navratil/Documents/Mendeley Desktop/2022/Galv{\~{a}}o Ferrarini et al/Frontiers in Genetics/Frontiers in Genetics{\_}Galv{\~{a}}o Ferrarini et al.{\_}Identifying Active Reactions During the Transient State for Metabolic Perturbations{\_}2022.pdf:pdf}, journal = {Frontiers in Genetics}, keywords = {DMC,DNA methylation,RRBS,epigenome,pig,testis}, pages = {1--12}, title = {{Identifying Active Reactions During the Transient State for Metabolic Perturbations}}, url = {www.frontiersin.org}, volume = {13}, year = {2022} } @article{Fablet2022, abstract = {Transposable elements (TEs) are parasite DNA sequences that are able to move and multiply along the chromosomes of all genomes. They are controlled by the host through the targeting of silencing epigenetic marks, which may affect the chromatin structure of neighboring sequences, including genes. In this study, we used transcriptomic and epigenomic high-throughput data produced from ovarian samples of Drosophila melanogaster and Drosophila simulans wild-type strains, in order to finely quantify the influence of TE insertions on gene RNA levels and histone marks (H3K4me3 and H3K9me3) enrichments. We find general, negative impacts of TE insertions on gene RNA levels and H3K4me3 enrichments, which intensity varies according to the localization of the TE insertion. We also uncover that TE insertions within exons are associated with a reduction in H3K9me3 enrichments, which we propose is associated with TE splicing out. Overall, we find that gene RNA and histone mark levels show contrasted dependencies on TE insertions regarding the species. The fold-decrease in TE-carrying gene proportions between extreme expression classes is 2.6 in D. melanogaster and 1.8 in D. simulans, while it is strongly contrasted between extreme classes of H3K4me3 enrichments: 4.4 in D. melanogaster and 19.2 in D. simulans. This provide a new light on the considerable natural variability provided by TEs, which may be associated with contrasted adaptive and evolutionary potentials.Competing Interest StatementThe authors have declared no competing interest.}, author = {Fablet, Marie and Salcez-Ortiz, Judit and Jacquet, Angelo and Menezes, Bianca F and Dechaud, Corentin and Veber, Philippe and No{\^{u}}s, Camille and Rebollo, Rita and Vieira, Cristina}, doi = {10.1101/2022.01.20.477049}, journal = {bioRxiv}, pages = {2022.01.20.477049}, title = {{A quantitative, genome-wide analysis in Drosophila reveals transposable elements' influence on gene expression is species-specific}}, url = {https://doi.org/10.1101/2022.01.20.477049 http://biorxiv.org/content/early/2022/01/22/2022.01.20.477049.abstract}, year = {2022} } @article{Latrille2022, abstract = {Phylogenetic codon models are routinely used to characterize selective regimes in coding sequences. Their parametric design, however, is still a matter of debate, in particular concerning the question of how to account for differing nucleotide frequencies and substitution rates. This problem relates to the fact that nucleotide composition in protein-coding sequences is the result of the interactions between mutation and selection. In particular, because of the structure of the genetic code, the nucleotide composition differs between the three coding positions, with the third position showing a more extreme composition. Yet, phylogenetic codon models do not correctly capture this phenomenon and instead predict that the nucleotide composition should be the same for all three positions. Alternatively, some models allow for different nucleotide rates at the three positions, an approach conflating the effects of mutation and selection on nucleotide composition. In practice, it results in inaccurate estimation of the strength of selection. Conceptually, the problem comes from the fact that phylogenetic codon models do not correctly capture the fixation bias acting against the mutational pressure at the mutation-selection equilibrium. To address this problem and to more accurately identify mutation rates and selection strength, we present an improved codon modeling approach where the fixation rate is not seen as a scalar, but as a tensor. This approach gives an accurate representation of how mutation and selection oppose each other at equilibrium and yields a reliable estimate of the mutational process, while disentangling the mean fixation probabilities prevailing in different mutational directions.}, author = {Latrille, Thibault and Lartillot, Nicolas}, doi = {10.1093/molbev/msac005}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {codon models,mutation-selection models,nucleotide bias,phylogenetics}, number = {2}, pmid = {35021218}, title = {{An Improved Codon Modeling Approach for Accurate Estimation of the Mutation Bias}}, url = {https://academic.oup.com/mbe/article-abstract/39/2/msac005/6503505}, volume = {39}, year = {2022} } @article{Thel2022, abstract = {Proposed in 1849 by Charles Morren to depict periodical phenomena governed by seasons, the term ‘phenology' has spread in many fields of biology. With the wide adoption of the concept of phenology flourished a large number of metrics with different meaning and interpretation. Here, we first a priori classified 52 previously published metrics used to characterise the phenology of births in large herbivores according to four biological characteristics of interest: timing, synchrony, rhythmicity and regularity of births. We then applied each metric retrieved on simulation data, considering normal and non-normal distributions of births, and varying distributions of births in time. We then evaluated the ability of each metric to capture the variation of the four phenology characteristics via a sensitivity analysis. Finally, we scored each metric according to eight criteria we considered important to describe phenology correctly. The high correlation we found among the many metrics we retrieved suggests that such diversity of metrics is unnecessary. We further show that the best metrics are not the most commonly used, and that simpler is often better. Circular statistics with the mean vector orientation and mean vector length seems, respectively, particularly suitable to describe the timing and synchrony of births in a wide range of phenology patterns. Tests designed to compare statistical distributions, like Mood and Kolmogorov–Smirnov tests, allow a first and easy quantification of rhythmicity and regularity of birth phenology respectively. By identifying the most relevant metrics our study should facilitate comparative studies of phenology of births or of any other life-history event. For instance, comparative studies of the phenology of mating or migration dates are particularly important in the context of climate change.}, author = {Thel, Lucie and Chamaill{\'{e}}-Jammes, Simon and Bonenfant, Christophe}, doi = {10.1111/oik.08917}, issn = {16000706}, journal = {Oikos}, title = {{How to describe and measure phenology? An investigation on the diversity of metrics using phenology of births in large herbivores}}, url = {https://hal.archives-ouvertes.fr/hal-03568554}, year = {2022} } @article{Touzot2022, abstract = {Artificial light at night (ALAN) affects numerous physiological and behavioural mechanisms in various species by potentially disturbing circadian timekeeping systems and modifying melatonin levels. However, given the multiple direct and indirect effects of ALAN on organisms, large-scale transcriptomic approaches are essential to assess the global effect of ALAN on biological processes. Moreover, although studies have focused mainly on variations in gene expression during the night in the presence of ALAN, it is necessary to investigate the effect of ALAN on gene expression during the day. In this study, we combined de novo transcriptome sequencing and assembly, and a controlled laboratory experiment to evaluate the transcriptome-wide gene expression response using high-throughput (RNA-seq) in Bufo bufo tadpoles exposed to ecologically relevant light levels. Here, we demonstrated for the first time that ALAN affected gene expression at night (3.5{\%} and 11{\%} of differentially expressed genes when exposed to 0.1 and 5 lx compared to controls, respectively), but also during the day (11.2{\%} of differentially expressed genes when exposed to 5 lx compared to controls) with a dose-dependent effect. ALAN globally induced a downregulation of genes (during the night, 58{\%} and 62{\%} of the genes were downregulated when exposed to 0.1 and 5 lx compared to controls, respectively, and during the day, 61.2{\%} of the genes were downregulated when exposed to 5 lx compared to controls). ALAN effects were detected at very low levels of illuminance (0.1 lx) and affected mainly genes related to the innate immune system and, to a lesser extend to lipid metabolism. These results provide new insights into understanding the effects of ALAN on organism. ALAN impacted the expression of genes linked to a broad range of physiological pathways at very low levels of ALAN during night-time and during daytime, potentially resulting in reduced immune capacity under environmental immune challenges.}, author = {Touzot, Morgane and Lefebure, Tristan and Lengagne, Thierry and Secondi, Jean and Dumet, Adeline and Konecny-Dupre, Lara and Veber, Philippe and Navratil, Vincent and Duchamp, Claude and Mondy, Nathalie}, doi = {10.1016/j.scitotenv.2021.151734}, issn = {18791026}, journal = {Science of the Total Environment}, keywords = {Amphibian,Immune system,Light pollution,Lipid metabolism,RNA-seq,Transcriptome}, pmid = {34808173}, title = {{Transcriptome-wide deregulation of gene expression by artificial light at night in tadpoles of common toads}}, url = {https://www.sciencedirect.com/science/article/pii/S0048969721068108}, volume = {818}, year = {2022} } @article{Portanier2022, abstract = {Human-mediated species dispersal across the Mediterranean stretches back at least 10,000 years and has left an indelible stamp on present-day biodiversity. Believed to be a descendant of the Asiatic mouflon (Ovis gmelini gmelinii), the Corsican mouflon (O. g. musimon) was translocated during the Neolithic as ancestral livestock by humans migrating from the Fertile Crescent to the Western Mediterranean. Today, two geographically limited and disconnected populations can be found in Corsica. Whether they originated from distinct founders or one ancestral population that later split remains unknown, although such information is pivotal for the species' management on the island. We genotyped 109 and 176 individuals at the Cytochrome-b gene and 16 loci of the microsatellite DNA, respectively, to gain insights into the natural history of the Corsican mouflon. We found evidence confirming that the Asiatic was the ancestor of the Corsican mouflon, which should thus be unvaryingly referred to as O. g. musimon, i.e. as a subspecies of the Asiatic mouflon. Haplotype divergence dating and the investigation of genetic structure highlighted a strong and ancient genetic differentiation between the two Corsican populations. Approximate Bayesian Computation pointed to the introduction of a single group of founders as the most reliable scenario for the origin of the entire Corsican population. Later, this ancestral stock would have decreased in number, facing genetic bottlenecks and eventually resulting in two divergent demes. Splitting most likely occurred several hundred years ago. Their shared past notwithstanding, we discuss whether the two relic Corsican mouflon populations should be now considered as distinct management units.}, author = {Portanier, Elodie and Chevret, Pascale and G{\'{e}}lin, Pauline and Benedetti, Pierre and Sanchis, Fr{\'{e}}d{\'{e}}ric and Barbanera, Filippo and Kaerle, C{\'{e}}cile and Queney, Guillaume and Bourgoin, Gilles and Devillard, S{\'{e}}bastien and Garel, Mathieu}, doi = {10.1007/s10592-021-01399-2}, isbn = {0123456789}, issn = {15729737}, journal = {Conservation Genetics}, keywords = {Approximate Bayesian computation,Historic faunal relocation,Human-mediated introduction,Management units,Phylogeography,Ungulates}, month = {feb}, number = {1}, pages = {91--107}, publisher = {Springer Science and Business Media B.V.}, title = {{New insights into the past and recent evolutionary history of the Corsican mouflon (Ovis gmelini musimon) to inform its conservation}}, url = {https://doi.org/10.1007/s10592-021-01399-2}, volume = {23}, year = {2022} } @article{Ratier2022a, author = {Ratier, Aude and Lopes, Christelle and Charles, Sandrine}, doi = {10.1101/2022.01.17.476613}, journal = {bioRxiv}, pages = {1--26}, title = {{Improvements in estimating bioaccumulation metrics in the light of toxicokinetics models and Bayesian inference}}, url = {https://doi.org/10.1101/2022.01.17.476613 https://www.biorxiv.org/content/10.1101/2022.01.17.476613v1}, year = {2022} } @article{Portanier2022a, abstract = {Understanding landscape impacts on gene flow is necessary to plan comprehensive management and conservation strategies of both the species of interest and its habitat. Nevertheless, only a few studies have focused on the landscape genetic connectivity of the European wildcat, an umbrella species whose conservation allows the preservation of numerous other species and habitat types. We applied population and landscape genetics approaches, using genotypes at 30 microsatellites from 232 genetically-identified wildcats to determine if, and how, landscape impacted gene flow throughout France. Analyses were performed independently within two population patches: the historical north-eastern patch and the central patch considered as the colonization front. Our results showed that gene flow occurred at large spatial scales but also revealed significant spatial genetic structures within population patches. In both population patches, arable areas, pastures and permanent grasslands and lowly fragmented forested areas were permeable to gene flow, suggesting that shelters and dietary resources are among the most important parameters for French wildcat landscape connectivity, while distance to forest had no detectable effect. Anthropized areas appeared highly resistant in the north-eastern patch but highly permeable in the central patch, suggesting that different behaviours can be observed according to the demographic context in which populations are found. In line with this hypothesis, spatial distribution of genetic variability seemed uneven in the north-eastern patch and more clinal in the central patch. Overall, our results highlighted that European wildcat might be a habitat generalist species and also the importance of performing spatial replication in landscape genetics studies.}, author = {Portanier, Elodie and L{\'{e}}ger, Fran{\c{c}}ois and Henry, Laurence and Gayet, Thibault and Queney, Guillaume and Ruette, Sandrine and Devillard, S{\'{e}}bastien}, doi = {10.1007/s10592-022-01443-9}, issn = {1566-0621}, journal = {Conservation Genetics}, keywords = {Animal Genetics and Genomics,Biodiversity,Conservation Biology/Ecology,Ecology,Evolutionary Biology,Plant Genetics and Genomics}, month = {mar}, pages = {1--16}, publisher = {Springer}, title = {{Landscape genetic connectivity in European wildcat (Felis silvestris silvestris): a matter of food, shelters and demographic status of populations}}, url = {https://link.springer.com/10.1007/s10592-022-01443-9}, year = {2022} } @article{Miele2021, abstract = {An increasing number of ecological monitoring programmes rely on photographic capture–recapture of individuals to study distribution, demography and abundance of species. Photo-identification of individuals can sometimes be done using idiosyncratic coat or skin patterns, instead of using tags or loggers. However, when performed manually, the task of going through photographs is tedious and rapidly becomes too time-consuming as the number of pictures grows. Computer vision techniques are an appealing and unavoidable help to tackle this apparently simple task in the big-data era. In this context, we propose to revisit animal re-identification using image similarity networks and metric learning with convolutional neural networks (CNNs), taking the giraffe as a working example. We first developed an end-to-end pipeline to retrieve a comprehensive set of re-identified giraffes from about 4,000 raw photographs. To do so, we combined CNN-based object detection, SIFT pattern matching and image similarity networks. We then quantified the performance of deep metric learning to retrieve the identity of known individuals, and to detect unknown individuals never seen in the previous years of monitoring. After a data augmentation procedure, the re-identification performance of the CNN reached a Top-1 accuracy of about 90{\%}, despite the very small number of images per individual in the training dataset. While the complete pipeline succeeded in re-identifying known individuals, it slightly under-performed with unknown individuals. Fully based on open-source software packages, our work paves the way for further attempts to build automatic pipelines for re-identification of individual animals, not only in giraffes but also in other species.}, author = {Miele, Vincent and Dussert, Gaspard and Spataro, Bruno and Chamaill{\'{e}}-Jammes, Simon and Allain{\'{e}}, Dominique and Bonenfant, Christophe}, doi = {10.1111/2041-210X.13577}, issn = {2041210X}, journal = {Methods in Ecology and Evolution}, keywords = {deep metric learning,image similarity networks,individual identification,open-source software}, number = {5}, pages = {863--873}, title = {{Revisiting animal photo-identification using deep metric learning and network analysis}}, url = {https://doi.org/10.1101/2020.03.25.007377}, volume = {12}, year = {2021} } @article{Lerat2021a, abstract = {Transposable elements (TEs) are middle-repeated DNA sequences that can move along chromosomes using internal coding and regulatory regions. By their ability to move and because they are repeated, TEs can promote mutations. Especially they can alter the expression pattern of neighboring genes and have been shown to be involved in the mammalian regulatory network evolution. Human and mouse share more than 95{\%} of their genomes and are affected by comparable diseases, which makes the mouse a perfect model in cancer research. However not much investigation concerning the mouse TE content has been made on this topics. In human cancer condition, a global activation of TEs can been observed which may ask the question of their impact on neighboring gene functioning. In this work, we used RNA sequences of highly aggressive pancreatic tumors from mouse to analyze the gene and TE deregulation happening in this condition compared to pancreas from healthy animals. Our results show that several TE families are deregulated and that the presence of TEs is associated with the expression divergence of genes in the tumor condition. These results illustrate the potential role of TEs in the global deregulation at work in the cancer cells.}, author = {Lerat, Emmanuelle and Burlet, Nelly and Navratil, Vincent and No{\^{u}}s, Camilles}, doi = {10.1101/2021.07.16.452652}, journal = {bioRxiv}, pages = {2021.07.16.452652}, title = {{Transposable element activity in the transcriptomic analysis of mouse pancreatic tumors}}, url = {https://doi.org/10.1101/2021.07.16.452652}, year = {2021} } @article{Gayet2021, abstract = {Intraspecific variations in mating systems have been reported in numerous species, especially when they live in varying ecological contexts. This leads to variability between populations with regard to the proportion of females engaging in multiple male mating, which depends on the number of males available. For hunted ungulate species, hunting is known to influence population structure, especially when males are preferentially targeted for trophy hunting. Here, we investigated how variations in hunting pressure and the yearly proportion of heavy males removed have impacted multiple paternity rates in five wild boar (Sus scrofa scrofa) populations located in similar ecological contexts. We found high rates of multiple paternity in all studied populations, confirming the recently reported promiscuous mating system of wild boar. However, variations in hunting pressure and removal of heavy males did not significantly influence multiple paternity rates, contrary to our expectation. Nonetheless, a slight tendency for a decreasing multiple paternity rate with increasing hunting pressure and for increasing multiple paternity rate with increasing removal of heavy males from the population was detected. Based on these results, we discuss an alternative hypothesis on the ecological processes sustaining the influence of hunting regimes on the mating system. Overall, hunting pressure and management rules might be sufficient to disrupt the mating system in any of the populations, so it is important to continue the sampling of wild boar populations at the European scale, especially in populations with little hunting pressure.}, author = {Gayet, Thibault and Say, Ludovic and Baubet, Eric and Devillard, S{\'{e}}bastien}, doi = {10.1007/s42991-020-00090-2}, issn = {16181476}, journal = {Mammalian Biology}, keywords = {Hunting,Mating plasticity,Multiple paternity,Sus scrofa}, number = {3}, pages = {321--327}, title = {{Consistently high multiple paternity rates in five wild boar populations despite varying hunting pressures}}, url = {https://link.springer.com/article/10.1007/s42991-020-00090-2}, volume = {101}, year = {2021} } @article{Ratier2021, abstract = {7 Regulatory bodies requires evaluation of bioaccumulation of chemicals within organisms with the objective to better assess risks linked to the toxicity of active substances. To this end, toxicokinetic (TK) data are particularly useful to relate the chemical exposure concentration to the accumulation and depuration processes happening within organisms. The bioaccumulative property of substances is quantified by bioaccumulation metrics obtained by fitting TK models to data collected from bioaccumulation tests. The internal concentrations of the studied substances are measured within organisms at regular time points during both accumulation and depuration phases, and their time course is captured by TK models thus providing bioaccumulation metrics. Still today, raw TK data remain difficult to access, as most of the time provided within papers in plots only. To increase accessibility to TK data, we present in this paper a wide collection of raw data sets extracted from the scientific literature in support of TK modelling to be performed with the MOSAIC bioacc web application (https://mosaic.univ-lyon1.fr/bioacc/). 8}, author = {Ratier, Aude and Charles, Sandrine}, doi = {10.1101/2021.04.15.439942}, journal = {Scientific Data, Nature}, number = {https://doi.org/10.1101/2021.04.15.439942}, title = {{Accumulation-depuration data collection in support of toxicokinetic modelling}}, url = {https://doi.org/10.1101/2021.04.15.439942}, volume = {accepted}, year = {2021} } @article{, doi = {10.1101/2021.03.24.436474}, journal = {Springer}, title = {{Taking full advantage of modelling to better assess environmental risk due to xenobiotics}}, url = {https://doi.org/10.1101/2021.03.24.436474}, year = {2021} } @article{Prentout2021, abstract = {We recently described, in Cannabis sativa, the oldest sex chromosome system documented so far in plants (12–28 Myr old). Based on the estimated age, we predicted that it should be shared by its sister genus Humulus, which is known also to possess XY chromosomes. Here, we used transcriptome sequencing of an F1 family of H. lupulus to identify and study the sex chromosomes in this species using the probabilistic method SEX-DETector. We identified 265 sex-linked genes in H. lupulus, which preferentially mapped to the C. sativa X chromosome. Using phylogenies of sex-linked genes, we showed that a region of the sex chromosomes had already stopped recombining in an ancestor of both species. Furthermore, as in C. sativa, Y-linked gene expression reduction is correlated to the position on the X chromosome, and highly Y degenerated genes showed dosage compensation. We report, for the first time in Angiosperms, a sex chromosome system that is shared by two different genera. Thus, recombination suppression started at least 21–25 Myr ago, and then (either gradually or step-wise) spread to a large part of the sex chromosomes (c. 70{\%}), leading to a degenerated Y chromosome.}, author = {Prentout, Djivan and Stajner, Natasa and Cerenak, Andreja and Tricou, Theo and Brochier-Armanet, Celine and Jakse, Jernej and K{\"{a}}fer, Jos and Marais, Gabriel A.B.}, doi = {10.1111/nph.17456}, issn = {14698137}, journal = {New Phytologist}, keywords = {Cannabaceae,Humulus lupulus,Y degeneration,dioecy,dosage compensation,sex chromosomes}, month = {aug}, number = {4}, pages = {1599--1611}, pmid = {33978992}, publisher = {John Wiley and Sons Inc}, title = {{Plant genera Cannabis and Humulus share the same pair of well-differentiated sex chromosomes}}, url = {www.newphytologist.com}, volume = {231}, year = {2021} } @article{Gayet2021a, abstract = {Intraspecific variations in mating systems have been reported in numerous species, especially when they live in varying ecological contexts. This leads to variability between populations with regard to the proportion of females engaging in multiple male mating, which depends on the number of males available. For hunted ungulate species, hunting is known to influence population structure, especially when males are preferentially targeted for trophy hunting. Here, we investigated how variations in hunting pressure and the yearly proportion of heavy males removed have impacted multiple paternity rates in five wild boar (Sus scrofa scrofa) populations located in similar ecological contexts. We found high rates of multiple paternity in all studied populations, confirming the recently reported promiscuous mating system of wild boar. However, variations in hunting pressure and removal of heavy males did not significantly influence multiple paternity rates, contrary to our expectation. Nonetheless, a slight tendency for a decreasing multiple paternity rate with increasing hunting pressure and for increasing multiple paternity rate with increasing removal of heavy males from the population was detected. Based on these results, we discuss an alternative hypothesis on the ecological processes sustaining the influence of hunting regimes on the mating system. Overall, hunting pressure and management rules might be sufficient to disrupt the mating system in any of the populations, so it is important to continue the sampling of wild boar populations at the European scale, especially in populations with little hunting pressure.}, author = {Gayet, Thibault and Say, Ludovic and Baubet, Eric and Devillard, S{\'{e}}bastien}, doi = {10.1007/s42991-020-00090-2}, issn = {16181476}, journal = {Mammalian Biology}, keywords = {Hunting,Mating plasticity,Multiple paternity,Sus scrofa}, month = {jun}, number = {3}, pages = {321--327}, publisher = {Springer Science and Business Media Deutschland GmbH}, title = {{Consistently high multiple paternity rates in five wild boar populations despite varying hunting pressures}}, volume = {101}, year = {2021} } @article{Charles2021, abstract = {In the European Union, more than 100,000 man-made chemical substances are awaiting an environmental risk assessment (ERA). Simultaneously, ERA of these chemicals has now entered a new era requiring determination of risks for physiologically diverse species exposed to several chemicals, often in mixtures. Additionally, recent recommendations from regulatory bodies underline a crucial need for the use of mechanistic effect models, allowing assessments that are not only ecologically relevant, but also more integrative, consistent and efficient. At the individual level, toxicokinetic-toxicodynamic (TKTD) models are particularly encouraged for the regulatory assessment of pesticide-related risks on aquatic organisms. In this paper, we first briefly present a classical dose-response model to showcase the on-line MOSAIC tool, which offers all necessary services in a turnkey web platform, whatever the type of data analyzed. Secondly, we focus on the necessity to account for the time-dimension of the exposure by illustrating how MOSAIC can support a robust calculation of bioaccumulation metrics. Finally, we show how MOSAIC can be of valuable help to fully complete the EFSA workflow regarding the use of TKTD models, especially with GUTS models, providing a user-friendly interface for calibrating, validating and predicting survival over time under any time-variable exposure scenario of interest. Our conclusion proposes a few lines of thought for an easier use of modelling in ERA. [Figure not available: see fulltext.].}, author = {Charles, Sandrine and Ratier, Aude and Baudrot, Virgile and Multari, Gauthier and Siberchicot, Aur{\'{e}}lie and Wu, Dan and Lopes, Christelle}, doi = {10.1007/s11356-021-15042-7}, issn = {16147499}, journal = {Environmental Science and Pollution Research}, keywords = {Accessibility,Bioaccumulation metrics,Dose-response models,Toxicokinetic-toxicodynamic model,Uncertainty}, publisher = {Springer Science and Business Media Deutschland GmbH}, title = {{Taking full advantage of modelling to better assess environmental risk due to xenobiotics—the all-in-one facility MOSAIC}}, year = {2021} } @incollection{Miele2021a, author = {Miele, Vincent and Louvet, Violaine}, booktitle = {Calcul parall{\`{e}}le avec R}, doi = {10.1051/978-2-7598-2068-9.c005}, month = {mar}, pages = {89--102}, publisher = {EDP Sciences}, title = {{5. Calculs et donn{\'{e}}es distribu{\'{e}}s avec R sur un cluster}}, year = {2021} } @article{Muyle2021, abstract = {About 15,000 angiosperm species (∼6{\%}) have separate sexes, a phenomenon known as dioecy. Why dioecious taxa are so rare is still an open question. Early work reported lower species richness in dioecious compared with nondioecious sister clades, raising the hypothesis that dioecy may be an evolutionary dead-end. This hypothesis has been recently challenged by macroevolutionary analyses that detected no or even positive effect of dioecy on diversification. However, the possible genetic consequences of dioecy at the population level, which could drive the long-term fate of dioecious lineages, have not been tested so far. Here, we used a population genomics approach in the Silene genus to look for possible effects of dioecy, especially for potential evidence of evolutionary handicaps of dioecy underlying the dead-end hypothesis. We collected individual-based RNA-seq data from several populations in 13 closely related species with different sexual systems: seven dioecious, three hermaphroditic, and three gynodioecious species. We show that dioecy is associated with increased genetic diversity, as well as higher selection efficacy both against deleterious mutations and for beneficial mutations. The results hold after controlling for phylogenetic inertia, differences in species census population sizes and geographic ranges. We conclude that dioecious Silene species neither show signs of increased mutational load nor genetic evidence for extinction risk. We discuss these observations in the light of the possible demographic differences between dioecious and self-compatible hermaphroditic species and how this could be related to alternatives to the dead-end hypothesis to explain the rarity of dioecy.}, author = {Muyle, Aline and Martin, H{\'{e}}l{\`{e}}ne and Zemp, Niklaus and Mollion, Ma{\'{e}}va and Gallina, Sophie and Tavares, Raquel and Silva, Alexandre and Bataillon, Thomas and Widmer, Alex and Gl{\'{e}}min, Sylvain and Touzet, Pascal and Marais, Gabriel A.B.}, doi = {10.1093/molbev/msaa229}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Allee effect,RNA-seq,angiosperms,population genetics,selection efficacy,sexual systems}, number = {3}, pages = {805--818}, pmid = {32926156}, title = {{Dioecy Is Associated with High Genetic Diversity and Adaptation Rates in the Plant Genus Silene}}, url = {https://academic.oup.com/mbe/article-abstract/38/3/805/5905496}, volume = {38}, year = {2021} } @article{Sellis2021, abstract = {a somatic genome in the same cytoplasm. The somatic macronucleus (MAC), responsible for gene expression, is not sexually transmitted but develops from a copy of the germline micronucleus (MIC) at each sexual generation. In the MIC genome of Paramecium tetraurelia, genes are interrupted by tens of thousands of unique intervening sequences called internal eliminated sequences (IESs), which have to be precisely excised during the development of the new MAC to restore functional genes. To understand the evolutionary origin of this peculiar genomic architecture, we sequenced the MIC genomes of 9 Paramecium species (from approximately 100 Mb in Paramecium aurelia species to {\textgreater}1.5 Gb in Paramecium caudatum). We detected several waves of IES gains, both in ancestral and in more recent lineages. While the vast majority of IESs are single copy in present-day genomes, we identified several families of mobile IESs, including nonautonomous elements acquired via horizontal transfer, which generated tens to thousands of new copies. These observations provide the first direct evidence that transposable elements can account for the massive proliferation of IESs in Paramecium. The comparison of IESs of different evolutionary ages indicates that, over time, IESs shorten and diverge rapidly in sequence while they acquire features that allow them to be more efficiently excised. We nevertheless identified rare cases of IESs that are under strong purifying selection across the aurelia clade. The cases examined contain or overlap cellular genes that are inactivated by excision during development, suggesting conserved regulatory mechanisms. Similar to the evolution of introns in eukaryotes, the evolution of Paramecium IESs highlights the major role played by selfish genetic elements in shaping the complexity of genome architecture and gene expression.}, author = {Sellis, Diamantis and Gu{\'{e}}rin, Fr{\'{e}}d{\'{e}}ric and Arnaiz, Olivier and Pett, Walker and Lerat, Emmanuelle and Boggetto, Nicole and Krenek, Sascha and Berendonk, Thomas and Couloux, Arnaud and Aury, Jean Marc and Labadie, Karine and Malinsky, Sophie and Bhullar, Simran and Meyer, Eric and Sperling, Linda and Duret, Laurent and Duharcourt, Sandra}, doi = {10.1371/journal.pbio.3001309}, issn = {15457885}, journal = {PLoS Biology}, number = {7}, pmid = {34324490}, title = {{Massive colonization of protein-coding exons by selfish genetic elements in Paramecium germline genomes}}, url = {https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3001309}, volume = {19}, year = {2021} } @techreport{Sessegolo2021, author = {Sessegolo, Camille}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Sessegolo/Unknown/Unknown{\_}Sessegolo{\_}D{\'{e}}veloppement de m{\'{e}}thodes bio-informatiques pour l'{\'{e}}tude de l'{\'{e}}pissage chez les esp{\`{e}}ces non mod{\`{e}}les {\'{E}}pissage co.pdf:pdf}, title = {{D{\'{e}}veloppement de m{\'{e}}thodes bio-informatiques pour l'{\'{e}}tude de l'{\'{e}}pissage chez les esp{\`{e}}ces non mod{\`{e}}les: {\'{E}}pissage complexe et apport des technologies de}}, url = {https://tel.archives-ouvertes.fr/tel-03520227/}, year = {2021} } @article{Mouneyrac2021, abstract = {The widespread use and release of nanomaterials (NMs) in aquatic ecosystems is a concerning issue as well as the fate and behavior of the NMs in relation to the aquatic organisms. In this work, the freshwater microcrustacean D. magna was exposed to 12 different and well-known NMs under the same conditions for 24h and then placed in clean media for 120h, in order to determine their different uptake and elimination behaviors. The results showed that most of the tested NMs displayed a fast uptake during the first hours arriving to a plateau by the end of the uptake phase. The elimination behavior was determined by a fast loss of NMs during the first hours in the clean media, mainly stimulated by the presence of food. Remaining NMs concentrations can still be found at the end of the elimination phase. Two NMs had a different profile i) ZnO-NM110 exhibited increase and loss during the uptake phase, and ii) SiO2-NM204 did not show any uptake. A toxicokinetic model was applied and the uptake and elimination rates were found along with the dynamic bioconcentration factors. These values allowed to compare the NMs, to cluster them by their similar rates, and to determine that the TiO2-NM102 is the one that has the fastest uptake and elimination behavior, SiO2-NM204 has the slowest uptake and CeO2{\textless}10nm has the slowest elimination. The present work represents a first attempt to compare different NMs based on their uptake and elimination behaviors from a perspective of the nano-bio interactions influence.}, author = {Mouneyrac, Catherine and Rivero, Andrea and Chatel, Am{\'{e}}lie and Manier, Nicolas}, doi = {10.1080/17435390.2021.1994668}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Mouneyrac et al/Article in Nanotoxicology/Article in Nanotoxicology{\_}Mouneyrac et al.{\_}Comparison of uptake and elimination kinetics of metallic oxide nanomaterials on the freshwat.pdf:pdf}, journal = {Article in Nanotoxicology}, keywords = {Daphnids,elimination,modelling 2,nanomaterials,toxicokinetics,uptake}, number = {9}, pages = {1168--1179}, publisher = {Taylor and Francis Ltd.}, title = {{Comparison of uptake and elimination kinetics of metallic oxide nanomaterials on the freshwater microcrustacean Daphnia magna}}, url = {https://www.tandfonline.com/doi/full/10.1080/17435390.2021.1994668}, volume = {15}, year = {2021} } @article{Borderes2021, abstract = {The human gut microbiota performs functions that are essential for the maintenance of the host physiology. However, characterizing the functioning of microbial communities in relation to the host remains challenging in reference-based metagenomic analyses. Indeed, as taxonomic and functional analyses are performed independently, the link between genes and species remains unclear. Although a first set of species-level bins was built by clustering co-abundant genes, no reference bin set is established on the most used gut microbiota catalog, the Integrated Gene Catalog (IGC). With the aim to identify the best suitable method to group the IGC genes, we benchmarked nine taxonomy-independent binners implementing abundance-based, hybrid and integrative approaches. To this purpose, we designed a simulated non-redundant gene catalog (SGC) and computed adapted assessment metrics. Overall, the best trade-off between the main metrics is reached by an integrative binner. For each approach, we then compared the results of the best-performing binner with our expected community structures and applied the method to the IGC. The three approaches are distinguished by specific advantages, and by inherent or scalability limitations. Hybrid and integrative binners show promising and potentially complementary results but require improvements to be used on the IGC to recover human gut microbial species.}, author = {Borderes, Marianne and Gasc, Cyrielle and Prestat, Emmanuel and {Galv{\~{a}}o Ferrarini}, Mariana and Vinga, Susana and Boucinha, Lilia and Sagot, Marie France}, doi = {10.1093/nargab/lqab009}, issn = {26319268}, journal = {NAR Genomics and Bioinformatics}, number = {1}, title = {{A comprehensive evaluation of binning methods to recover human gut microbial species from a non-redundant reference gene catalog}}, url = {https://academic.oup.com/nargab/article-abstract/3/1/lqab009/6155872}, volume = {3}, year = {2021} } @article{Sellis2021a, abstract = {a somatic genome in the same cytoplasm. The somatic macronucleus (MAC), responsible for gene expression, is not sexually transmitted but develops from a copy of the germline micronucleus (MIC) at each sexual generation. In the MIC genome of Paramecium tetraurelia, genes are interrupted by tens of thousands of unique intervening sequences called internal eliminated sequences (IESs), which have to be precisely excised during the development of the new MAC to restore functional genes. To understand the evolutionary origin of this peculiar genomic architecture, we sequenced the MIC genomes of 9 Paramecium species (from approximately 100 Mb in Paramecium aurelia species to {\textgreater}1.5 Gb in Paramecium caudatum). We detected several waves of IES gains, both in ancestral and in more recent lineages. While the vast majority of IESs are single copy in present-day genomes, we identified several families of mobile IESs, including nonautonomous elements acquired via horizontal transfer, which generated tens to thousands of new copies. These observations provide the first direct evidence that transposable elements can account for the massive proliferation of IESs in Paramecium. The comparison of IESs of different evolutionary ages indicates that, over time, IESs shorten and diverge rapidly in sequence while they acquire features that allow them to be more efficiently excised. We nevertheless identified rare cases of IESs that are under strong purifying selection across the aurelia clade. The cases examined contain or overlap cellular genes that are inactivated by excision during development, suggesting conserved regulatory mechanisms. Similar to the evolution of introns in eukaryotes, the evolution of Paramecium IESs highlights the major role played by selfish genetic elements in shaping the complexity of genome architecture and gene expression.}, author = {Sellis, Diamantis and Gu{\'{e}}rin, Fr{\'{e}}d{\'{e}}ric and Arnaiz, Olivier and Pett, Walker and Lerat, Emmanuelle and Boggetto, Nicole and Krenek, Sascha and Berendonk, Thomas and Couloux, Arnaud and Aury, Jean Marc and Labadie, Karine and Malinsky, Sophie and Bhullar, Simran and Meyer, Eric and Sperling, Linda and Duret, Laurent and Duharcourt, Sandra}, doi = {10.1371/journal.pbio.3001309}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Sellis et al/PLoS Biology/PLoS Biology{\_}Sellis et al.{\_}Massive colonization of protein-coding exons by selfish genetic elements in Paramecium germline genomes{\_}2021.pdf:pdf}, issn = {15457885}, journal = {PLoS Biology}, month = {jul}, number = {7}, pmid = {34324490}, publisher = {Public Library of Science}, title = {{Massive colonization of protein-coding exons by selfish genetic elements in Paramecium germline genomes}}, volume = {19}, year = {2021} } @article{RouxDeBezieux2021, abstract = {Genome wide association studies (GWAS), aiming to find genetic variants associated with a trait, have widely been used on bacteria to identify genetic determinants of drug resistance or hypervirulence. Recent bacterial GWAS methods usually rely on k-mers, whose presence in a genome can denote variants ranging from single nucleotide polymorphisms to mobile genetic elements. Since many bacterial species include genes that are not shared among all strains, this approach avoids the reliance on a common reference genome. However, the same gene can exist in slightly different versions across different strains, leading to diluted effects when trying to detect its association to a phenotype through k-mer based GWAS. Here we propose to overcome this by testing covariates built from closed connected subgraphs of the De Bruijn graph defined over genomic k-mers. These covariates are able to capture polymorphic genes as a single entity, improving k-mer based GWAS in terms of power and interpretability. As the number of subgraphs is exponential in the number of nodes in the DBG, a method naively testing all possible subgraphs would result in very low statistical power due to multiple testing corrections, and the mere exploration of these subgraphs would quickly become computationally intractable. The concept of testable hypothesis has successfully been used to address both problems in similar contexts. We leverage this concept to test all closed connected subgraphs by proposing a novel enumeration scheme for these objects which fully exploits the pruning opportunity offered by testability, resulting in drastic improvements in computational efficiency. We illustrate this on both real and simulated datasets and also demonstrate how considering subgraphs leads to a more powerful and interpretable method. Our method integrates with existing visual tools to facilitate interpretation. We also provide an implementation of our method, as well as code to reproduce all results at https://github.com/HectorRDB/Caldera{\_}Recomb.}, author = {{Roux De B{\'{e}}zieux}, Hector and Lima, Leandro and Perraudeau, Fanny and Mary, Arnaud and Dudoit, Sandrine and Jacob, Laurent}, doi = {10.1101/2021.11.05.467462}, journal = {biorxiv.org}, title = {{CALDERA: Finding all significant de Bruijn subgraphs for bacterial GWAS}}, url = {https://doi.org/10.1101/2021.11.05.467462}, year = {2021} } @article{Latrille2021, author = {Latrille, Thibault and Lanore, Vincent and Lartillot, Nicolas}, doi = {10.1093/molbev/msab160}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {codon models,life-history traits,mutation rate,mutation-selection models,phylogenetic,population genetic,population size}, number = {10}, pages = {4573--4587}, pmid = {34191010}, title = {{Inferring Long-Term Effective Population Size with Mutation-Selection Models}}, url = {https://academic.oup.com/mbe/article-abstract/38/10/4573/6311666}, volume = {38}, year = {2021} } @article{Marin2021, abstract = {Adaptation to rapid environmental changes must occur within a short-time scale. In this context, studies of invasive species may provide insights into the underlying mechanisms of rapid adaptation as these species have repeatedly encountered and adapted to novel environmental conditions. We investigated how invasive and noninvasive genotypes of Drosophila suzukii deal with oxidative stress at the phenotypic and molecular levels. We also studied the impact of transposable element (TE) insertions on the gene expression in response to stress. Our results show that flies from invasive areas (France and the United States) live longer in natural conditions than the ones from native Japanese areas. As expected, lifespan for all genotypes was significantly reduced following exposure to paraquat, but this reduction varied among genotypes (genotype-by-environment interaction) with invasive genotypes appearing more affected by exposure than noninvasive ones. A transcriptomic analysis of genotypes upon paraquat treatment detected many genes differentially expressed (DE). Although a small core set of genes were DE in all genotypes following paraquat exposure, much of the response of each genotype was unique. Moreover, we showed that TEs were not activated after oxidative stress and DE genes were significantly depleted of TEs. In conclusion, it is likely that transcriptomic changes are involved in the rapid adaptation to local environments. We provide new evidence that in the decade since the invasion from Asia, the sampled genotypes in Europe and the United States of D. suzukii diverged from the ones from the native area regarding their phenotypic and genomic response to oxidative stress.}, author = {Marin, Pierre and Jaquet, Angelo and Picarle, Justine and Fablet, Marie and Merel, Vincent and Delignette-Muller, Marie Laure and Ferrarini, Mariana Galv{\~{a}}o and Gibert, Patricia and Vieira, Cristina}, doi = {10.1093/gbe/evab208}, issn = {17596653}, journal = {Genome biology and evolution}, keywords = {D. suzukii,environmental changes,genotype-by-environment interaction,invasive species,oxidative stress,transposable elements}, number = {9}, pmid = {34505904}, title = {{Phenotypic and Transcriptomic Responses to Stress Differ According to Population Geography in an Invasive Species}}, url = {https://academic.oup.com/gbe/article-abstract/13/9/evab208/6368064}, volume = {13}, year = {2021} } @article{Kafer2021, abstract = {We propose a method, SDpop, able to infer sex-linkage caused by recombination suppression typical of sex chromosomes. The method is based on the modeling of the allele and genotype frequencies of individuals of known sex in natural populations. It is implemented in a hierarchical probabilistic framework, accounting for different sources of error. It allows statistical testing for the presence or absence of sex chromosomes, and detection of sex-linked genes based on the posterior probabilities in the model. Furthermore, for gametologous sequences, the haplotype and level of nucleotide polymorphism of each copy can be inferred, as well as the divergence between them. We test the method using simulated data, as well as data from both a relatively recent and an old sex chromosome system (the plant Silene latifolia and humans) and show that, for most cases, robust predictions are obtained with 5 to 10 individuals per sex.}, author = {K{\"{a}}fer, Jos and Lartillot, Nicolas and Marais, Gabriel A.B. and Picard, Franck}, doi = {10.1093/genetics/iyab053}, issn = {19432631}, journal = {Genetics}, keywords = {genetics of sex,hierarchical model,population genomics,probabilistic inference,sex chromosomes}, number = {2}, pmid = {33764439}, title = {{Detecting sex-linked genes using genotyped individuals sampled in natural populations}}, url = {https://hal.archives-ouvertes.fr/hal-02490340}, volume = {218}, year = {2021} } @article{Necsulea2021, abstract = {The search for new biomarkers and drug targets for hepatocellular carcinoma (HCC) has spurred an interest in long non-coding RNAs (lncRNAs), often proposed as oncogenes or tumor suppressors. Furthermore, lncRNA expression patterns can bring insights into the global de-regulation of cellular machineries in tumors. Here, we examine lncRNAs in a large HCC cohort, comprising RNA-seq data from paired tumor and adjacent tissue biopsies from 114 patients. We find that numerous lncRNAs are differentially expressed between tumors and adjacent tissues and between tumor progression stages. Although we find strong differential expression for most lncRNAs previously associated with HCC, the expression patterns of several prominent HCC-associated lncRNAs disagree with their previously proposed roles. We examine the genomic characteristics of HCC-expressed lncRNAs and reveal an enrichment for repetitive elements among the lncRNAs with the strongest expression increases in advanced-stage tumors. This enrichment is particularly striking for lncRNAs that overlap with satellite repeats, a major component of centromeres. Consistently, we find increased non-coding RNA transcription from centromeres in tumors, in the majority of patients, suggesting that aberrant centromere activation takes place in HCC.Competing Interest StatementThe authors have declared no competing interest.}, author = {Necsulea, Anamaria and Veber, Philippe and Boldanova, Tuyana and Ng, Charlotte K Y and Wieland, Stefan and Heim, Markus H}, doi = {10.1101/2021.03.03.433778}, journal = {bioRxiv}, pages = {2021.03.03.433778}, title = {{LncRNA analyses reveal increased levels of non-coding centromeric transcripts in hepatocellular carcinoma}}, url = {https://doi.org/10.1101/2021.03.03.433778 https://doi.org/10.1101/2021.03.03.433778{\%}0Ahttp://biorxiv.org/content/early/2021/03/04/2021.03.03.433778.abstract}, year = {2021} } @article{Lecocq2021, abstract = {Previous reports have shown that environmental temperature impacts proteome evolution in Bacteria and Archaea. However, it is unknown whether thermoadaptation mainly occurs via the sequential accumulation of substitutions, massive horizontal gene transfers, or both. Measuring the real contribution of amino acid substitution to thermoadaptation is challenging, because of confounding environmental and genetic factors (e.g., pH, salinity, genomic G + C content) that also affect proteome evolution. Here, using Methanococcales, a major archaeal lineage, as a study model, we show that optimal growth temperature is the major factor affecting variations in amino acid frequencies of proteomes. By combining phylogenomic and ancestral sequence reconstruction approaches, we disclose a sequential substitutional scheme in which lysine plays a central role by fine tuning the pool of arginine, serine, threonine, glutamine, and asparagine, whose frequencies are strongly correlated with optimal growth temperature. Finally, we show that colonization to new thermal niches is not associated with high amounts of horizontal gene transfers. Altogether, although the acquisition of a few key proteins through horizontal gene transfer may have favored thermoadaptation in Methanococcales, our findings support sequential amino acid substitutions as the main factor driving thermoadaptation.}, author = {Lecocq, Michel and Groussin, Mathieu and Gouy, Manolo and Brochier-Armanet, C{\'{e}}line}, doi = {10.1093/molbev/msaa312}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Methanococci,ancestral sequence reconstruction,evolutionary rates,extremophiles,horizontal gene transfer,prokaryotes,protein}, number = {5}, pages = {1761--1776}, pmid = {33450027}, title = {{The Molecular Determinants of Thermoadaptation: Methanococcales as a Case Study}}, url = {https://academic.oup.com/mbe/article-abstract/38/5/1761/6017176}, volume = {38}, year = {2021} } @article{Brevet2021, abstract = {The nearly neutral theory predicts specific relations between effective population size (Ne) and patterns of divergence and polymorphism, which depend on the shape of the distribution of fitness effects (DFE) of new mutations. However, testing these relations is not straightforward, owing to the difficulty in estimating Ne. Here, we introduce an integrative framework allowing for an explicit reconstruction of the phylogenetic history of Ne, thus leading to a quantitative test of the nearly neutral theory and an estimation of the allometric scaling of the ratios of nonsynonymous over synonymous polymorphism ($\pi$N/$\pi$S) and divergence (dN/dS) with respect to Ne. As an illustration, we applied our method to primates, for which the nearly neutral predictions were mostly verified. Under a purely nearly neutral model with a constant DFE across species, we find that the variation in $\pi$N/$\pi$S and dN/dS as a function of Ne is too large to be compatible with current estimates of the DFE based on site frequency spectra. The reconstructed history of Ne shows a 10-fold variation across primates. The mutation rate per generation u, also reconstructed over the tree by the method, varies over a 3-fold range and is negatively correlated with Ne. As a result of these opposing trends for Ne and u, variation in $\pi$S is intermediate, primarily driven by Ne but substantially influenced by u. Altogether, our integrative framework provides a quantitative assessment of the role of Ne and u in modulating patterns of genetic variation, while giving a synthetic picture of their history over the clade.}, author = {Brevet, Mathieu and Lartillot, Nicolas}, doi = {10.1093/gbe/evab150}, issn = {17596653}, journal = {Genome biology and evolution}, keywords = {codon model,effective population size,nearly neutral evolution,phylogeny}, number = {8}, pmid = {34190972}, title = {{Reconstructing the History of Variation in Effective Population Size along Phylogenies}}, url = {https://academic.oup.com/gbe/article-abstract/13/8/evab150/6311658}, volume = {13}, year = {2021} } @article{Garcia2021, abstract = {The cell cycle is a fundamental process that has been extensively studied in bacteria. However, many of its components and their interactions with machineries involved in other cellular processes are poorly understood. Furthermore, most knowledge relies on the study of a few models, but the real diversity of the cell division apparatus and its evolution are largely unknown. Here, we present a massive in-silico analysis of cell division and associated processes in around 1,000 genomes of the Firmicutes, a major bacterial phylum encompassing models (i.e. Bacillus subtilis, Streptococcus pneumoniae, and Staphylococcus aureus), as well as many important pathogens. We analyzed over 160 proteins by using an original approach combining phylogenetic reconciliation, phylogenetic profiles, and gene cluster survey. Our results reveal the presence of substantial differences among clades and pinpoints a number of evolutionary hotspots. In particular, the emergence of Bacilli coincides with an expansion of the gene repertoires involved in cell wall synthesis and remodeling. We also highlight major genomic rearrangements at the emergence of Streptococcaceae. We establish a functional network in Firmicutes that allows identifying new functional links inside one same process such as between FtsW (peptidoglycan polymerase) and a previously undescribed Penicilin-Binding Protein or between different processes, such as replication and cell wall synthesis. Finally, we identify new candidates involved in sporulation and cell wall synthesis. Our results provide a previously undescribed view on the diversity of the bacterial cell cycle, testable hypotheses for further experimental studies, and a methodological framework for the analysis of any other biological system.}, author = {Garcia, Pierre S. and Duchemin, Wandrille and Flandrois, Jean Pierre and Gribaldo, Simonetta and Grangeasse, Christophe and Brochier-Armanet, C{\'{e}}line}, doi = {10.1093/molbev/msab034}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Bacteria,Firmicutes,cell cycle,cell division,evolution,evolutionary scenario,functional link,phylogenomics,phylogeny}, number = {6}, pages = {2396--2412}, pmid = {33533884}, title = {{A Comprehensive Evolutionary Scenario of Cell Division and Associated Processes in the Firmicutes}}, url = {https://academic.oup.com/mbe/article-abstract/38/6/2396/6127179}, volume = {38}, year = {2021} } @article{Brochier-Armanet2021, abstract = {The NAD(P)-dependent malate dehydrogenases (MDH) (EC 1.1.1.37) and NAD-dependent lactate dehydrogenases (LDH) (EC. 1.1.1.27) form a large superfamily that has been characterized in organisms belonging to the three Domains of Life. MDH catalyzes the reversible conversion of the oxaloacetate into malate, while LDH operates at the late stage of glycolysis by converting pyruvate into lactate. Phylogenetic studies proposed that the LDH/MDH superfamily encompasses five main groups of enzymes. Here, starting from 16,052 reference proteomes, we reinvestigated the relationships between MDH and LDH. We showed that the LDH/MDH superfamily encompasses three main families: MDH1, MDH2, and a large family encompassing MDH3, LDH, and L-2-hydroxyisocaproate dehydrogenases (HicDH) sequences. An in-depth analysis of the phylogeny of the MDH3/LDH/HicDH family and of the nature of three important amino acids, located within the catalytic site and involved in binding and substrate discrimination, revealed a large group of sequences displaying unexpected combinations of amino acids at these three critical positions. This group branched in-between canonical MDH3 and LDH sequences. The functional characterization of several enzymes from this intermediate group disclosed a mix of functional properties, indicating that the MDH3/LDH/HicDH family is much more diverse than previously thought, and blurred the frontier between MDH3 and LDH enzymes. Present-days enzymes of the intermediate group are a valuable material to study the evolutionary steps that led to functional diversity and emergence of allosteric regulation within the LDH/MDH superfamily.}, author = {Brochier-Armanet, C{\'{e}}line and Madern, Dominique}, doi = {10.1016/j.biochi.2021.08.004}, issn = {61831638}, journal = {Biochimie}, keywords = {Allosteric regulation,Archaea,Lactate dehydrogenase,Malate dehydrogenase,Molecular evolution,Neofunctionalization}, pages = {140--153}, pmid = {34418486}, title = {{Phylogenetics and biochemistry elucidate the evolutionary link between L-malate and L-lactate dehydrogenases and disclose an intermediate group of sequences with mix functional properties}}, url = {https://www.sciencedirect.com/science/article/pii/S0300908421001966}, volume = {191}, year = {2021} } @article{Latrille2021a, abstract = {Molecular sequences are shaped by selection, where the strength of selection relative to drift 1 is determined by effective population size (N e). Populations with high N e are expected to 2 undergo stronger purifying selection, and consequently to show a lower substitution rate 3 for selected mutations relative to the substitution rate for neutral mutations ($\omega$). However, 4 computational models based on biophysics of protein stability have suggested that $\omega$ can also 5 be independent of N e , a result proven under general conditions. Together, the response of $\omega$ 6 to changes in N e depends on the specific mapping from sequence to fitness. Importantly, an 7 increase in protein expression level has been found empirically to result in decrease of $\omega$, an 8 observation predicted by theoretical models assuming selection for protein stability. Here, we 9 derive a theoretical approximation for the response of $\omega$ to changes in N e and expression level, 10 under an explicit genotype-phenotype-fitness map. The method is generally valid for additive 11 traits and log-concave fitness functions. We applied these results to protein undergoing 12 selection for their conformational stability and corroborate out findings with simulations 13 under more complex models. We predict a weak response of $\omega$ to changes in either N e or 14 expression level, which are interchangeable. Based on empirical data, we propose that fitness 15 based on the conformational stability may not be a sufficient mechanism to explain the 16 empirically observed variation in $\omega$ across species. Other aspects of protein biophysics might 17 be explored, such as protein-protein interactions, which can lead to a stronger response of $\omega$ 18 to changes in N e. A theoretical approach for quantifying the impact of changes in effective population size and expression level on the rate of coding sequence evolution.}, author = {Latrille, T and Lartillot, N}, doi = {10.1101/2021.01.13.426437}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Latrille, Lartillot/biorxiv.org/biorxiv.org{\_}Latrille, Lartillot{\_}A theoretical approach for quantifying the impact of changes in effective population size and expression.pdf:pdf}, journal = {biorxiv.org}, title = {{A theoretical approach for quantifying the impact of changes in effective population size and expression level on the rate of coding sequence evolution}}, url = {https://doi.org/10.1101/2021.01.13.426437}, year = {2021} } @article{Periquet2021, abstract = {Dynamic interactions between apex predators reveal contrasting seasonal attraction patterns.}, author = {P{\'{e}}riquet, S and Fritz, H and Revilla, E and Macdonald, D and Loveridge, A and Mtare, G}, doi = {10.1007/s00442-020-04802-wï}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/P{\'{e}}riquet et al/Oecologia/Oecologia{\_}P{\'{e}}riquet et al.{\_}Dynamic interactions between apex predators reveal contrasting seasonal attraction patterns{\_}2021.pdf:pdf}, journal = {Oecologia}, number = {1}, pages = {51--63}, publisher = {Springer Verlag}, title = {{Dynamic interactions between apex predators reveal contrasting seasonal attraction patterns}}, url = {https://hal.archives-ouvertes.fr/hal-03425858}, volume = {195}, year = {2021} } @article{Merel2021, abstract = {Transposable elements (TEs) are ubiquitous and mobile repeated sequences. They are major determinants of host fitness. Here, we characterized the TE content of the spotted wing fly Drosophila suzukii. Using a recently improved genome assembly, we reconstructed TE sequences de novo and found that TEs occupy 47{\%} of the genome and are mostly located in gene-poor regions. The majority of TE insertions segregate at low frequencies, indicating a recent and probably ongoing TE activity. To explore TE dynamics in the context of biological invasions, we studied the variation of TE abundance in genomic data from 16 invasive and six native populations of D. suzukii. We found a large increase of the TE load in invasive populations correlated with a reduced Watterson estimate of genetic diversity $\theta$w{\^{}} a proxy of effective population size. We did not find any correlation between TE contents and bioclimatic variables, indicating a minor effect of environmentally induced TE activity. A genome-wide association study revealed that ca. 2,000 genomic regions are associated with TE abundance. We did not find, however, any evidence in such regions of an enrichment for genes known to interact with TE activity (e.g., transcription factor encoding genes or genes of the piRNA pathway). Finally, the study of TE insertion frequencies revealed 15 putatively adaptive TE insertions, six of them being likely associated with the recent invasion history of the species.}, author = {M{\'{e}}rel, Vincent and Gibert, Patricia and Buch, Inessa and {Rodriguez Rada}, Valentina and Estoup, Arnaud and Gautier, Mathieu and Fablet, Marie and Boulesteix, Matthieu and Vieira, Cristina}, doi = {10.1093/molbev/msab155}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Drosophila suzukii,PoolSeq,adaptation,biological invasion,populations,transposable elements}, number = {10}, pages = {4252--4267}, pmid = {34021759}, title = {{The Worldwide Invasion of Drosophila suzukii Is Accompanied by a Large Increase of Transposable Element Load and a Small Number of Putatively Adaptive Insertions}}, url = {https://academic.oup.com/mbe/article-abstract/38/10/4252/6281075}, volume = {38}, year = {2021} } @article{Latrille2021b, abstract = {Molecular sequences are shaped by selection, where the strength of selection relative to drift is determined by effective population size (Ne). Populations with high Ne are expected to undergo stronger purifying selection, and consequently to show a lower substitution rate for selected mutations relative to the substitution rate for neutral mutations ($\omega$). However, computational models based on biophysics of protein stability have suggested that $\omega$ can also be independent of Ne. Together, the response of $\omega$ to changes in Ne depends on the specific mapping from sequence to fitness. Importantly, an increase in protein expression level has been found empirically to result in decrease of $\omega$, an observation predicted by theoretical models assuming selection for protein stability. Here, we derive a theoretical approximation for the response of $\omega$ to changes in Ne and expression level, under an explicit genotype-phenotype-fitness map. The method is generally valid for additive traits and log-concave fitness functions. We applied these results to protein undergoing selection for their conformational stability and corroborate out findings with simulations under more complex models. We predict a weak response of $\omega$ to changes in either Ne or expression level, which are interchangeable. Based on empirical data, we propose that fitness based on the conformational stability may not be a sufficient mechanism to explain the empirically observed variation in $\omega$ across species. Other aspects of protein biophysics might be explored, such as protein–protein interactions, which can lead to a stronger response of $\omega$ to changes in Ne.}, author = {Latrille, T and Lartillot, N.}, doi = {10.1016/j.tpb.2021.09.005}, issn = {10960325}, journal = {Theoretical Population Biology}, keywords = {Drift,Expression level,Population-genetics,Protein stability,Substitution rate}, pages = {57--66}, pmid = {34563555}, title = {{Quantifying the impact of changes in effective population size and expression level on the rate of coding sequence evolution}}, url = {https://www.sciencedirect.com/science/article/pii/S0040580921000678}, volume = {142}, year = {2021} } @article{Roy2021, abstract = {Transposable elements (TEs) are genomic parasites, which activity is tightly controlled in germline cells. Using Sindbis virus, it was recently demonstrated that viral infections affect TE transcript amounts in somatic tissues. However, the strongest evolutionary impacts are expected in gonads, because that is where the genomes of the next generations lie. Here, we investigated this aspect using the Drosophila melanogaster Sigma virus. It is particularly relevant in the genome/TE interaction given its tropism to ovaries, which is the organ displaying the more sophisticated TE control pathways. Our results in Drosophila simulans flies allowed us to confirm the existence of a strong homeostasis of the TE transcriptome in ovaries upon infection, which, however, rely on TE-derived small RNA modulations. In addition, we performed a meta-analysis of RNA-seq data and propose that the immune pathway that is triggered upon viral infection determines the direction of TE transcript modulation in somatic tissues.}, author = {Roy, Marl{\`{e}}ne and Viginier, Barbara and Mayeux, Camille A. and Ratinier, Maxime and Fablet, Marie}, doi = {10.1093/gbe/evab207}, issn = {17596653}, journal = {Genome biology and evolution}, keywords = {RNA interference,genomic parasites,piRNAs,siRNAs,sigma virus,transcription regulation}, number = {9}, pmid = {34498066}, title = {{Infections by Transovarially Transmitted DMelSV in Drosophila Have No Impact on Ovarian Transposable Element Transcripts but Increase Their Amounts in the Soma}}, url = {https://academic.oup.com/gbe/article-abstract/13/9/evab207/6366551}, volume = {13}, year = {2021} } @article{Thel2021, abstract = {Ecologists increasingly rely on camera-Trap data to estimate biological parameters such as population abundance. Because of the huge amount of data camera trap can generate, the assistance of non-scientists is often sought after, but an assessment of the data quality is necessary. We tested whether volunteers data from one of the largest citizen science projects-Snapshot Serengeti-could be used to study breeding phenology. We tested whether the presence of juveniles (less than one or 12 months old) of species of large herbivores in the Serengeti: Topi, kongoni, Grant's gazelle, could be reliably detected by the {\^{a}}{\~{n}}aive' volunteers versus trained observers. We expected a positive correlation between the proportion of volunteers identifying juveniles and their effective presence within photographs, assessed by the trained observers. The agreement between the trained observers was good (Fleiss' $\kappa$ {\textgreater} 0.61 for juveniles of less than one and 12 month(s) old), suggesting that morphological criteria can be used to determine age of juveniles. The relationship between the proportion of volunteers detecting juveniles less than a month old and their actual presence plateaued at 0.45 for Grant's gazelle, reached 0.70 for topi and 0.56 for kongoni. The same relationships were much stronger for juveniles younger than 12 months, reaching 1 for topi and kongoni. The absence of individuals {\textless} one month and the presence of juveniles {\textless} 12 months could be reliably assumed, respectively, when no volunteer and when all volunteers reported a presence of a young. In contrast, the presence of very young individuals and the absence of juveniles appeared more difficult to ascertain from volunteers' classification, given how the classification task was presented to them. Volunteers' classification allows a moderately accurate but quick sorting of photograph with/without juveniles. We discuss the limitations of using citizen science camera-Traps data to study breeding phenology, and the options to improve the detection of juveniles.}, author = {Thel, Lucie and Chamaill{\'{e}}-Jammes, Simon and Keurinck, L{\'{e}}a and Catala, Maxime and Packer, Craig and Huebner, Sarah E and Bonenfant, Christophe}, doi = {10.2981/wlb.00833}, issn = {09096396}, journal = {Wildlife Biology}, keywords = {African ungulates,Alcelaphus cokii,Damaliscus jimela,Nanger granti,age determination}, number = {2}, title = {{Can citizen science analysis of camera trap data be used to study reproduction? Lessons from Snapshot Serengeti program}}, url = {https://orcid.org/0000-0002-3939-8162}, volume = {2021}, year = {2021} } @article{Chevret2021, abstract = {Following human occupation, the house mouse has colonised numerous islands, exposing the species to a wide variety of environments. Such a colonisation process, involving successive founder events and bottlenecks, may either promote random evolution or facilitate adaptation, making the relative importance of adaptive and stochastic processes in insular evolution difficult to assess. Here, we jointly analyse genetic and morphometric variation in the house mice (Mus musculus domesticus) from the Orkney archipelago. Genetic analyses, based on mitochondrial DNA and microsatellites, revealed considerable genetic structure within the archipelago, suggestive of a high degree of isolation and long-lasting stability of the insular populations. Morphometric analyses, based on a quantification of the shape of the first upper molar, revealed considerable differentiation compared to Western European populations, and significant geographic structure in Orkney, largely congruent with the pattern of genetic divergence. Morphological diversification in Orkney followed a Brownian motion model of evolution, suggesting a primary role for random drift over adaptation to local environments. Substantial structuring of human populations in Orkney has recently been demonstrated, mirroring the situation found here in house mice. This synanthropic species may thus constitute a bioproxy of human structure and practices even at a very local scale.}, author = {Chevret, Pascale and Hautier, Lionel and Ganem, Guila and Herman, Jeremy and Agret, Sylvie and Auffray, Jean Christophe and Renaud, Sabrina}, doi = {10.1038/s41437-020-00368-8}, issn = {13652540}, journal = {Heredity}, number = {2}, pages = {266--278}, pmid = {32980864}, title = {{Genetic structure in Orkney island mice: isolation promotes morphological diversification}}, url = {https://www.nature.com/articles/s41437-020-00368-8}, volume = {126}, year = {2021} } @inproceedings{Fraisse2021, abstract = {We present DILS, a deployable statistical analysis platform for conducting demographic inferences with linked selection from population genomic data using an Approximate Bayesian Computation framework. DILS takes as input single-population or two-population data sets (multilocus fasta sequences) and performs three types of analyses in a hierarchical manner, identifying: (a) the best demographic model to study the importance of gene flow and population size change on the genetic patterns of polymorphism and divergence, (b) the best genomic model to determine whether the effective size Ne and migration rate N, m are heterogeneously distributed along the genome (implying linked selection) and (c) loci in genomic regions most associated with barriers to gene flow. Also available via a Web interface, an objective of DILS is to facilitate collaborative research in speciation genomics. Here, we show the performance and limitations of DILS by using simulations and finally apply the method to published data on a divergence continuum composed by 28 pairs of Mytilus mussel populations/species.}, author = {Fra{\"{i}}sse, Christelle and Popovic, Iva and Mazoyer, Cl{\'{e}}ment and Spataro, Bruno and Delmotte, St{\'{e}}phane and Romiguier, Jonathan and Loire, {\'{E}}tienne and Simon, Alexis and Galtier, Nicolas and Duret, Laurent and Bierne, Nicolas and Vekemans, Xavier and Roux, Camille}, booktitle = {Molecular Ecology Resources}, doi = {10.1111/1755-0998.13323}, issn = {17550998}, month = {nov}, number = {8}, pages = {2629--2644}, pmid = {33448666}, publisher = {John Wiley and Sons Inc}, title = {{DILS: Demographic inferences with linked selection by using ABC}}, volume = {21}, year = {2021} } @article{Sellis2021b, abstract = {a somatic genome in the same cytoplasm. The somatic macronucleus (MAC), responsible for gene expression, is not sexually transmitted but develops from a copy of the germline micronucleus (MIC) at each sexual generation. In the MIC genome of Paramecium tetraurelia, genes are interrupted by tens of thousands of unique intervening sequences called internal eliminated sequences (IESs), which have to be precisely excised during the development of the new MAC to restore functional genes. To understand the evolutionary origin of this peculiar genomic architecture, we sequenced the MIC genomes of 9 Paramecium species (from approximately 100 Mb in Paramecium aurelia species to {\textgreater}1.5 Gb in Paramecium caudatum). We detected several waves of IES gains, both in ancestral and in more recent lineages. While the vast majority of IESs are single copy in present-day genomes, we identified several families of mobile IESs, including nonautonomous elements acquired via horizontal transfer, which generated tens to thousands of new copies. These observations provide the first direct evidence that transposable elements can account for the massive proliferation of IESs in Paramecium. The comparison of IESs of different evolutionary ages indicates that, over time, IESs shorten and diverge rapidly in sequence while they acquire features that allow them to be more efficiently excised. We nevertheless identified rare cases of IESs that are under strong purifying selection across the aurelia clade. The cases examined contain or overlap cellular genes that are inactivated by excision during development, suggesting conserved regulatory mechanisms. Similar to the evolution of introns in eukaryotes, the evolution of Paramecium IESs highlights the major role played by selfish genetic elements in shaping the complexity of genome architecture and gene expression.}, author = {Sellis, Diamantis and Gu{\'{e}}rin, Fr{\'{e}}d{\'{e}}ric and Arnaiz, Olivier and Pett, Walker and Lerat, Emmanuelle and Boggetto, Nicole and Krenek, Sascha and Berendonk, Thomas and Couloux, Arnaud and Aury, Jean Marc and Labadie, Karine and Malinsky, Sophie and Bhullar, Simran and Meyer, Eric and Sperling, Linda and Duret, Laurent and Duharcourt, Sandra}, doi = {10.1371/journal.pbio.3001309}, issn = {15457885}, journal = {PLoS Biology}, number = {7}, pmid = {34324490}, title = {{Massive colonization of protein-coding exons by selfish genetic elements in Paramecium germline genomes}}, url = {https://journals.plos.org/plosbiology/article?id=10.1371/journal.pbio.3001309}, volume = {19}, year = {2021} } @article{Lambert2021, abstract = {The management of infectious diseases in wildlife reservoirs is challenging and faces several limitations. However, detailed knowledge of host-pathogen systems often reveal heterogeneity among the hosts' contribution to transmission. Management strategies targeting specific classes of individuals and/or areas, having a particular role in transmission, could be more effective and more acceptable than population-wide interventions. In the wild population of Alpine ibex (Capra ibex-a protected species) of the Bargy massif (French Alps), females transmit brucellosis (Brucella melitensis) infection in {\~{}}90{\%} of cases, and most transmissions occur in the central spatial units ("core area"). Therefore, we expanded an individual-based model, developed in a previous study, to test whether strategies targeting females or the core area, or both, would be more effective. We simulated the relative efficacy of realistic strategies for the studied population, combining test-and-remove (euthanasia of captured animals with seropositive test results) and partial culling of unmarked animals. Targeting females or the core area was more effective than untargeted management options, and strategies targeting both were even more effective. Interestingly, the number of ibex euthanized and culled in targeted strategies were lower than in untargeted ones, thus decreasing the conservation costs while increasing the sanitary benefits. Although there was no silver bullet for the management of brucellosis in the studied population, targeted strategies offered a wide range of promising refinements to classical sanitary measures. We therefore encourage to look for heterogeneity in other wildlife diseases and to evaluate potential strategies for improving management in terms of efficacy but also acceptability.}, author = {Lambert, S{\'{e}}bastien and Th{\'{e}}bault, Anne and Rossi, Sophie and Marchand, Pascal and Petit, Elodie and To{\"{i}}go, Carole and Gilot-Fromont, Emmanuelle}, doi = {10.1186/s13567-021-00984-0}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Lambert et al/Veterinary research/Veterinary research{\_}Lambert et al.{\_}Targeted strategies for the management of wildlife diseases the case of brucellosis in Alpine ibex{\_}20.pdf:pdf}, issn = {12979716}, journal = {Veterinary research}, keywords = {Wildlife disease,capture,culling,disease management,heterogeneity,mathematical modelling,metapopulation,targeting,test-and-remove,vaccination}, month = {sep}, number = {1}, pages = {116}, pmid = {34521471}, publisher = {NLM (Medline)}, title = {{Targeted strategies for the management of wildlife diseases: the case of brucellosis in Alpine ibex}}, volume = {52}, year = {2021} } @article{Lerat2021, abstract = {Transposable elements (TEs) are middle-repeated DNA sequences that can move along chromosomes using internal coding and regulatory regions. By their ability to move and because they are repeated, TEs can promote mutations. Especially they can alter the expression pattern of neighboring genes and have been shown to be involved in the mammalian regulatory network evolution. Human and mouse share more than 95{\%} of their genomes and are affected by comparable diseases, which makes the mouse a perfect model in cancer research. However not much investigation concerning the mouse TE content has been made on this topics. In human cancer condition, a global activation of TEs can been observed which may ask the question of their impact on neighboring gene functioning. In this work, we used RNA sequences of highly aggressive pancreatic tumors from mouse to analyze the gene and TE deregulation happening in this condition compared to pancreas from healthy animals. Our results show that several TE families are deregulated and that the presence of TEs is associated with the expression divergence of genes in the tumor condition. These results illustrate the potential role of TEs in the global deregulation at work in the cancer cells.}, author = {Lerat, Emmanuelle and Burlet, Nelly and Navratil, Vincent and No{\^{u}}s, Camilles}, doi = {10.1101/2021.07.16.452652}, journal = {bioRxiv}, month = {jul}, pages = {2021.07.16.452652}, publisher = {Cold Spring Harbor Laboratory}, title = {{Transposable element activity in the transcriptomic analysis of mouse pancreatic tumors}}, url = {https://doi.org/10.1101/2021.07.16.452652}, year = {2021} } @article{Oger-Desfeux2021, abstract = {We report the complete genome sequence of Bradyrhizobium sp. strain BDV5040, representative of Bradyrhizobium genospecies B, which symbiotically associates with legume hosts belonging to all three Fabaceae subfamilies across the Australian continent. The complete genome sequence provides a genetic reference for this Australian genospecies.}, author = {Oger-Desfeux, Christine and Briolay, J{\'{e}}r{\^{o}}me and Oger, Philippe M and Lafay, B{\'{e}}n{\'{e}}dicte}, doi = {10.1128/MRA.01326-20}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Oger-Desfeux et al/Microbiology resource announcements/Microbiology resource announcements{\_}Oger-Desfeux et al.{\_}Complete Genome Sequence of Bradyrhizobium sp. Strain BDV5040, Representative of.pdf:pdf}, issn = {2576-098X}, journal = {Microbiology resource announcements}, month = {jan}, number = {3}, pmid = {33479000}, publisher = {American Society for Microbiology}, title = {{Complete Genome Sequence of Bradyrhizobium sp. Strain BDV5040, Representative of Widespread Genospecies B in Australia.}}, url = {http://www.ncbi.nlm.nih.gov/pubmed/33479000 http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC8407762}, volume = {10}, year = {2021} } @article{Oger-Desfeux2021a, abstract = {We report the complete genome sequence of Bradyrhizobium sp. strain BDV5419, representative of Bradyrhizobium genospecies L, which symbiotically associates with the Australian native legume Hardenbergia violaceae and is expected to represent a novel Bradyrhizobium species. The complete genome sequence provides a genetic reference for this Australian genospecies.}, author = {Oger-Desfeux, Christine and Briolay, J{\'{e}}r{\^{o}}me and Oger, Philippe M and Lafay, B{\'{e}}n{\'{e}}dicte}, doi = {10.1128/MRA.00042-21}, file = {:Users/navratil/Documents/Mendeley Desktop/2021/Oger-Desfeux et al/Microbiology resource announcements/Microbiology resource announcements{\_}Oger-Desfeux et al.{\_}Complete Genome Sequence of Bradyrhizobium sp. Strain BDV5419, Representative of.pdf:pdf}, issn = {2576-098X}, journal = {Microbiology resource announcements}, month = {feb}, number = {8}, pmid = {33632854}, publisher = {American Society for Microbiology}, title = {{Complete Genome Sequence of Bradyrhizobium sp. Strain BDV5419, Representative of Australian Genospecies L.}}, url = {http://www.ncbi.nlm.nih.gov/pubmed/33632854 http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC7909079}, volume = {10}, year = {2021} } @article{Touzot2021, author = {Touzot, Morgane and Lefebure, Tristan and Lengagne, Thierry and Secondi, Jean and Dumet, Adeline and Konecny-Dupre, Lara and Veber, Philippe and Navratil, Vincent and Duchamp, Claude and Mondy, Nathalie}, doi = {10.1016/j.scitotenv.2021.151734}, issn = {00489697}, journal = {Science of The Total Environment}, keywords = {MEDLINE,Morgane Touzot,NCBI,NIH,NLM,Nathalie Mondy,National Center for Biotechnology Information,National Institutes of Health,National Library of Medicine,PubMed Abstract,Tristan Lefebure,doi:10.1016/j.scitotenv.2021.151734,pmid:34808173}, month = {nov}, pages = {151734}, publisher = {Sci Total Environ}, title = {{Transcriptome-wide deregulation of gene expression by artificial light at night in tadpoles of common toads}}, url = {https://linkinghub.elsevier.com/retrieve/pii/S0048969721068108}, year = {2021} } @misc{Hufsky2021, abstract = {SARS-CoV-2 (severe acute respiratory syndrome coronavirus 2) is a novel virus of the family Coronaviridae. The virus causes the infectious disease COVID-19. The biology of coronaviruses has been studied for many years. However, bioinformatics tools designed explicitly for SARS-CoV-2 have only recently been developed as a rapid reaction to the need for fast detection, understanding and treatment of COVID-19. To control the ongoing COVID-19 pandemic, it is of utmost importance to get insight into the evolution and pathogenesis of the virus. In this review, we cover bioinformatics workflows and tools for the routine detection of SARS-CoV-2 infection, the reliable analysis of sequencing data, the tracking of the COVID-19 pandemic and evaluation of containment measures, the study of coronavirus evolution, the discovery of potential drug targets and development of therapeutic strategies. For each tool, we briefly describe its use case and how it advances research specifically for SARS-CoV-2. All tools are free to use and available online, either through web applications or public code repositories. Contact:evbc@unj-jena.de}, author = {Hufsky, Franziska and Lamkiewicz, Kevin and Almeida, Alexandre and Aouacheria, Abdel and Arighi, Cecilia and Bateman, Alex and Baumbach, Jan and Beerenwinkel, Niko and Brandt, Christian and Cacciabue, Marco and Chuguransky, Sara and Drechsel, Oliver and Finn, Robert D. and Fritz, Adrian and Fuchs, Stephan and Hattab, Georges and Hauschild, Anne Christin and Heider, Dominik and Hoffmann, Marie and H{\"{o}}lzer, Martin and Hoops, Stefan and Kaderali, Lars and Kalvari, Ioanna and {Von Kleist}, Max and Kmiecinski, Ren{\'{o}} and K{\"{u}}hnert, Denise and Lasso, Gorka and Libin, Pieter and List, Markus and L{\"{o}}chel, Hannah F. and Martin, Maria J. and Martin, Roman and Matschinske, Julian and McHardy, Alice C. and Mendes, Pedro and Mistry, Jaina and Navratil, Vincent and Nawrocki, Eric P. and O'Toole, A{\'{i}}ne Niamh and Ontiveros-Palacios, Nancy and Petrov, Anton I. and Rangel-Pineros, Guillermo and Redaschi, Nicole and Reimering, Susanne and Reinert, Knut and Reyes, Alejandro and Richardson, Lorna and Robertson, David L. and Sadegh, Sepideh and Singer, Joshua B. and Theys, Kristof and Upton, Chris and Welzel, Marius and Williams, Lowri and Marz, Manja}, booktitle = {Briefings in Bioinformatics}, doi = {10.1093/bib/bbaa232}, issn = {14774054}, keywords = {SARS-CoV-2,drug design,epidemiology,sequencing,tools,virus bioinformatics}, month = {mar}, number = {2}, pages = {642--663}, pmid = {33147627}, publisher = {Oxford University Press}, title = {{Computational strategies to combat COVID-19: Useful tools to accelerate SARS-CoV-2 and coronavirus research}}, url = {https://pubmed.ncbi.nlm.nih.gov/33147627/}, volume = {22}, year = {2021} } @article{DiGiovanni2020, abstract = {Some species of parasitic wasps have domesticated viral machineries to deliver immunosuppressive factors to their hosts. Up to now, all described cases fall into the Ichneumonoidea superfamily, which only represents around 10{\%} of hymenoptera diversity, raising the question of whether such domestication occurred outside this clade. Furthermore, the biology of the ancestral donor viruses is completely unknown. Since the 1980s, we know that Drosophila parasitoids belonging to the Leptopilina genus, which diverged from the Ichneumonoidea superfamily 225 Ma, do produce immunosuppressive virus-like structure in their reproductive apparatus. However, the viral origin of these structures has been the subject of debate. In this article, we provide genomic and experimental evidence that those structures do derive from an ancestral virus endogenization event. Interestingly, its close relatives induce a behavior manipulation in present-day wasps. Thus, we conclude that virus domestication is more prevalent than previously thought and that behavior manipulation may have been instrumental in the birth of such associations.}, author = {{Di Giovanni}, Deborah and Lepetit, David and Guinet, Benjamin and Bennetot, Bastien and Boulesteix, Matthieu and Cout{\'{e}}, Yohann and Bouchez, Olivier and Ravallec, Marc and Varaldi, Julien}, doi = {10.1093/molbev/msaa030}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Domestication,Horizontal gene transfer,Parasitoid,Superparasitism,Symbiosis,Virus,Wasps}, number = {10}, pages = {2791--2807}, pmid = {32080746}, title = {{A behavior-manipulating virus relative as a source of adaptive genes for drosophila parasitoids}}, url = {https://academic.oup.com/mbe/article-abstract/37/10/2791/5733738}, volume = {37}, year = {2020} } @article{Mucha2020, abstract = {Mycoplasma hyopneumoniae is the most costly pathogen for swine production. Although several studies have focused on the host-bacterium association, little is known about the changes in gene expression of swine cells upon infection. To improve our understanding of this interaction, we infected swine epithelial NPTr cells with M. hyopneumoniae strain J to identify differentially expressed mRNAs and miRNAs. The levels of 1,268 genes and 170 miRNAs were significantly modified post-infection. Up-regulated mRNAs were enriched in genes related to redox homeostasis and antioxidant defense, known to be regulated by the transcription factor NRF2 in related species. Down-regulated mRNAs were enriched in genes associated with cytoskeleton and ciliary functions. Bioinformatic analyses suggested a correlation between changes in miRNA and mRNA levels, since we detected down-regulation of miRNAs predicted to target antioxidant genes and up-regulation of miRNAs targeting ciliary and cytoskeleton genes. Interestingly, most down-regulated miRNAs were detected in exosome-like vesicles suggesting that M. hyopneumoniae infection induced a modification of the composition of NPTr-released vesicles. Taken together, our data indicate that M. hyopneumoniae elicits an antioxidant response induced by NRF2 in infected cells. In addition, we propose that ciliostasis caused by this pathogen is partially explained by the down-regulation of ciliary genes.}, author = {Mucha, Scheila G. and Ferrarini, Mariana G. and Moraga, Carol and {Di Genova}, Alex and Guyon, Laurent and Tardy, Florence and Rome, Sophie and Sagot, Marie France and Zaha, Arnaldo}, doi = {10.1038/s41598-020-70040-y}, issn = {20452322}, journal = {Scientific Reports}, number = {1}, pmid = {32792522}, title = {{Mycoplasma hyopneumoniae J elicits an antioxidant response and decreases the expression of ciliary genes in infected swine epithelial cells}}, url = {https://www.nature.com/articles/s41598-020-70040-y}, volume = {10}, year = {2020} } @article{Schrempf2020, abstract = {Biochemical demands constrain the range of amino acids acceptable at specific sites resulting in across-site compositional heterogeneity of the amino acid replacement process. Phylogenetic models that disregard this heterogeneity are prone to systematic errors, which can lead to severe long-branch attraction artifacts. State-of-the-art models accounting for across-site compositional heterogeneity include the CAT model, which is computationally expensive, and empirical distribution mixture models estimated via maximum likelihood (C10–C60 models). Here, we present a new, scalable method EDCluster for finding empirical distribution mixture models involving a simple cluster analysis. The cluster analysis utilizes specific coordinate transformations which allow the detection of specialized amino acid distributions either from curated databases or from the alignment at hand. We apply EDCluster to the HOGENOM and HSSP databases in order to provide universal distribution mixture (UDM) models comprising up to 4,096 components. Detailed analyses of the UDM models demonstrate the removal of various long-branch attraction artifacts and improved performance compared with the C10–C60 models. Ready-to-use implementations of the UDM models are provided for three established software packages (IQ-TREE, Phylobayes, and RevBayes).}, author = {Schrempf, Dominik and Lartillot, Nicolas and Sz{\"{o}}llosi, Gergely}, doi = {10.1093/molbev/msaa145}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Empirical distribution mixture models,Empirical profile mixture models,Long-branch attraction,Microsporidia,Phylogenetics}, number = {12}, pages = {3616--3631}, pmid = {32877529}, title = {{Scalable empirical mixture models that account for across-site compositional heterogeneity}}, url = {https://academic.oup.com/mbe/article-abstract/37/12/3616/5900673}, volume = {37}, year = {2020} } @article{Darbellay2020, abstract = {The functionality of long noncoding RNAs (lncRNAs) is disputed. In general, lncRNAs are under weak selective pressures, suggesting that the majority of lncRNAs may be nonfunctional. However, although some surveys showed negligible phenotypic effects upon lncRNA perturbation, key biological roles were demonstrated for individual lncRNAs. Most lncRNAs with proven functions were implicated in gene expression regulation, in pathways related to cellular pluripotency, differentiation, and organ morphogenesis, suggesting that functional lncRNAs may be more abundant in embryonic development, rather than in adult organs. To test this hypothesis, we perform a multidimensional comparative transcriptomics analysis, across five developmental time points (two embryonic stages, newborn, adult, and aged individuals), four organs (brain, kidney, liver, and testes), and three species (mouse, rat, and chicken). We find that, overwhelmingly, lncRNAs are preferentially expressed in adult and aged testes, consistent with the presence of permissive transcription during spermatogenesis. LncRNAs are often differentially expressed among developmental stages and are less abundant in embryos and newborns compared with adult individuals, in agreement with a requirement for tighter expression control and less tolerance for noisy transcription early in development. For differentially expressed lncRNAs, we find that the patterns of expression variation among developmental stages are generally conserved between mouse and rat. Moreover, lncRNAs expressed above noise levels in somatic organs and during development show higher evolutionary conservation, in particular, at their promoter regions. Thus, we show that functionally constrained lncRNA loci are enriched in developing organs, and we suggest that many of these loci may function in an RNA-independent manner.}, author = {Darbellay, Fabrice and Necsulea, Anamaria}, doi = {10.1093/molbev/msz212}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {comparative transcriptomics,development,evolution,long noncoding RNAs}, number = {1}, pages = {240--259}, pmid = {31539080}, title = {{Comparative Transcriptomics Analyses across Species, Organs, and Developmental Stages Reveal Functionally Constrained lncRNAs}}, url = {https://academic.oup.com/mbe/article-abstract/37/1/240/5572125}, volume = {37}, year = {2020} } @techreport{Ziska2020, author = {Ziska, Irene}, title = {{Models and algorithms for investigating and exploiting the metabolism of microorganisms}}, url = {https://tel.archives-ouvertes.fr/tel-03131655}, year = {2020} } @techreport{Picard2020, author = {Picard, Lea}, title = {{Identification of Novel Viral Interacting Proteins through the Detection of Genetic INNovations (DGINN) combined with functional assays}}, url = {https://tel.archives-ouvertes.fr/tel-03510332}, year = {2020} } @article{Abby2020, abstract = {We present a computational method to identify conjugative systems in plasmids and chromosomes using the CONJscan module of MacSyFinder. The method relies on the identification of the protein components of the system using hidden Markov model profiles and then checking that the composition and genetic organization of the system is consistent with that expected from a conjugative system. The method can be assessed online using the Galaxy workflow or locally using a standalone software. The latter version allows to modify the models of the module (i.e., to change the expected components, their number, and their organization). CONJscan identifies conjugative systems, but when the mobile genetic element is integrative (ICE), one often also wants to delimit it from the chromosome. We present a method, with a script, to use the results of CONJscan and comparative genomics to delimit ICE in chromosomes. The method provides a visual representation of the ICE location. Together, these methods facilitate the identification of conjugative elements in bacterial genomes.}, author = {Abby, Sophie S and Doppelt-Azeroual, Olivia and Cury, Jean and N{\'{e}}, Bertrand and Rocha, Eduardo P C}, doi = {10.1007/978-1-4939-9877-7_19}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Abby et al/Springer/Springer{\_}Abby et al.{\_}Identifying Conjugative Plasmids and Integrative Conjugative Elements with CONJscan{\_}2020.pdf:pdf}, journal = {Springer}, keywords = {Comparative genomics,Conjugation,Genomic islands,Integrase,Integrative conjugative element,MacSyFinder,Plasmid,Protein profiles}, pages = {265--283}, publisher = {Humana Press Inc.}, title = {{Identifying Conjugative Plasmids and Integrative Conjugative Elements with CONJscan}}, url = {https://doi.org/10.1007/978-1-4939-9877-7{\_}19,}, volume = {2075}, year = {2020} } @article{Pusa2020, abstract = {Motivation: Analysis of differential expression of genes is often performed to understand how the metabolic activity of an organism is impacted by a perturbation. However, because the system of metabolic regulation is complex and all changes are not directly reflected in the expression levels, interpreting these data can be difficult. Results: In this work, we present a new algorithm and computational tool that uses a genome-scale metabolic reconstruction to infer metabolic changes from differential expression data. Using the framework of constraint-based analysis, our method produces a qualitative hypothesis of a change in metabolic activity. In other words, each reaction of the network is inferred to have increased, decreased, or remained unchanged in flux. In contrast to similar previous approaches, our method does not require a biological objective function and does not assign on/off activity states to genes. An implementation is provided and it is available online. We apply the method to three published datasets to show that it successfully accomplishes its two main goals: confirming or rejecting metabolic changes suggested by differentially expressed genes based on how well they fit in as parts of a coordinated metabolic change, as well as inferring changes in reactions whose genes did not undergo differential expression.}, author = {Pusa, Taneli and Ferrarini, Mariana Galv{\~{a}}o and Andrade, Ricardo and Mary, Arnaud and Marchetti-Spaccamela, Alberto and Stougie, Leen and Sagot, Marie France}, doi = {10.1093/bioinformatics/btz584}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Pusa et al/Bioinformatics/Bioinformatics{\_}Pusa et al.{\_}MOOMIN - Mathematical explOration of 'Omics data on a MetabolIc Network{\_}2020.pdf:pdf}, issn = {14602059}, journal = {Bioinformatics}, month = {jan}, number = {2}, pages = {514--523}, pmid = {31504164}, publisher = {Oxford University Press}, title = {{MOOMIN - Mathematical explOration of 'Omics data on a MetabolIc Network}}, url = {https://academic.oup.com/bioinformatics/article/36/2/514/5553096}, volume = {36}, year = {2020} } @article{Gallot2020, abstract = {Sib mating increases homozygosity, which therefore increases the risk of inbreeding depression. Selective pressures have favoured the evolution of kin recognition and avoidance of sib mating in numerous species, including the parasitoid wasp Venturia canescens. We studied the female neurogenomic response associated with sib mating avoidance after females were exposed to courtship displays by i) unrelated males or ii) related males or iii) no courtship (controls). First, by comparing the transcriptional responses of females exposed to courtship displays to those exposed to controls, we saw a rapid and extensive transcriptional shift consistent with social environment. Second, by comparing the transcriptional responses of females exposed to courtship by related to those exposed to unrelated males, we characterized distinct and repeatable transcriptomic patterns that correlated with the relatedness of the courting male. Network analysis revealed 3 modules of specific 'sibresponsive' genes that were distinct from other 'courtship-responsive' modules. Therefore, specific neurogenomic states with characteristic brain transcriptomes associated with different behavioural responses affect sib mating avoidance behaviour.}, author = {Gallot, Aurore and Sauzet, Sandrine and Desouhant, Emmanuel}, doi = {10.1371/journal.pone.0241128}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Gallot, Sauzet, Desouhant/PLoS ONE/PLoS ONE{\_}Gallot, Sauzet, Desouhant{\_}Kin recognition Neurogenomic response to mate choice and sib mating avoidance in a parasitic wasp{\_}202.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, month = {oct}, number = {10 October}, pmid = {33104752}, publisher = {Public Library of Science}, title = {{Kin recognition: Neurogenomic response to mate choice and sib mating avoidance in a parasitic wasp}}, volume = {15}, year = {2020} } @article{Carvalho2020, abstract = {Horizontal gene transfer (HGT) promotes the spread of genes within bacterial communities. Among the HGT mechanisms, natural transformation stands out as being encoded by the bacterial core genome. Natural transformation is often viewed as a way to acquire new genes and to generate genetic mixing within bacterial populations. Another recently proposed function is the curing of bacterial genomes of their infectious parasitic mobile genetic elements (MGEs). Here, we propose that these seemingly opposing theoretical points of view can be unified. Although costly for bacterial cells, MGEs can carry functions that are at points in time beneficial to bacteria under stressful conditions (e.g., antibiotic resistance genes). Using computational modeling, we show that, in stochastic environments, an intermediate transformation rate maximizes bacterial fitness by allowing the reversible integration of MGEs carrying resistance genes, although these MGEs are costly for host cell replication. Based on this dual function (MGE acquisition and removal), transformation would be a key mechanism for stabilizing the bacterial genome in the long term, and this would explain its striking conservation. IMPORTANCE Natural transformation is the acquisition, controlled by bacteria, of extracellular DNA and is one of the most common mechanisms of horizontal gene transfer, promoting the spread of resistance genes. However, its evolutionary function remains elusive, and two main roles have been proposed: (i) the new gene acquisition and genetic mixing within bacterial populations and (ii) the removal of infectious parasitic mobile genetic elements (MGEs). While the first one promotes genetic diversification, the other one promotes the removal of foreign DNA and thus genome stability, making these two functions apparently antagonistic. Using a computational model, we show that intermediate transformation rates, commonly observed in bacteria, allow the acquisition then removal of MGEs. The transient acquisition of costly MGEs with resistance genes maximizes bacterial fitness in environments with stochastic stress exposure. Thus, transformation would ensure both a strong dynamic of the bacterial genome in the short term and its long-term stabilization.}, author = {Carvalho, Gabriel and Fouchet, David and Danesh, Gonch{\'{e}} and Godeux, Anne Sophie and Laaberki, Maria Halima and Pontier, Dominique and Charpentier, Xavier and Venner, Samuel}, doi = {10.1128/mBio.02443-19}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Carvalho et al/mBio/mBio{\_}Carvalho et al.{\_}Bacterial transformation buffers environmental fluctuations through the reversible integration of mobile genetic el.pdf:pdf}, issn = {21507511}, journal = {mBio}, keywords = {Horizontal gene transfer,Mobile genetic elements,Natural transformation,Resistance genes,Stochastic environment}, month = {mar}, number = {2}, pmid = {32127449}, publisher = {American Society for Microbiology}, title = {{Bacterial transformation buffers environmental fluctuations through the reversible integration of mobile genetic elements}}, volume = {11}, year = {2020} } @article{Beugin2020, abstract = {European wildcat (Felis silvestris silvestris) populations are fragmented throughout most of the whole range of the subspecies and may be threatened by hybridization with the domestic cat F.s. catus. The underlying ecological processes promoting hy-bridization remain largely unknown. In France, wildcats are mainly present in the northeast and signs of their presence in the Pyrenees have been recently provided. However, no studies have been carried out in the French Pyrenees to assess their exposure to hybridization. We compared two local populations of wildcats, one living in a continuous forest habitat in the French Pyrenees, the other living in a highly fragmented forest-agricultural landscape in northeastern France to get insights into the variability of hybridization rates. Strong evidence of hybridization was detected in northeastern France and not in the Pyrenees. Close kin in the Pyrenees were not found in the same geographic location contrary to what was previously reported for females in the northeastern wildcat population. The two wildcat populations were significantly differentiated (F ST = 0.072) to an extent close to what has been reported (F ST = 0.103) between the Iberian population, from which the Pyrenean population may originate, and the German population, which is connected to the northeastern population. The genetic diversity of the Pyrenean wildcats was lower than that of northeastern wildcat populations in France and in other parts of Europe. The lower hybridization in the Pyrenees may result from the continuity of natural forest habitats. Further investigations should focus on linking landscape features to hybridiza-tion rates working on local populations.}, author = {Beugin, Marie-Pauline and Salvador, Olivier and Leblanc, Guillaume and Queney, Guillaume and Natoli, Eugenia and Pontier, Dominique and Sovrazonale, Canile and Rome, Asl and {Correspondence Dominique Pontier}, Italy}, doi = {10.1002/ece3.5892}, journal = {Ecology and Evolution}, keywords = {Felis silvestris silvestris,K E Y W O R D S F s catus,hybridization,microsatellites,noninvasive sampling,relatedness}, month = {jan}, number = {1}, pages = {263--276}, publisher = {John Wiley and Sons Ltd}, title = {{Hybridization between Felis silvestris silvestris and Felis silvestris catus in two contrasted environments in France Funding information R{\'{e}}serves naturelles catalanes; FIV-VAX Lyon-Biop{\^{o}}le project; CNRS}}, url = {www.ecolevol.org}, volume = {10}, year = {2020} } @article{Fruchard2020, abstract = {About 15,000 angiosperms are dioecious, but the mechanisms of sex determination in plants remain poorly understood. In particular, how Y chromosomes evolve and degenerate, and whether dosage compensation evolves as a response, are matters of debate. Here, we focus on Coccinia grandis, a dioecious cucurbit with the highest level of X/Y heteromorphy recorded so far. We identified sex‐linked genes using RNA sequences from a cross and a model‐based method termed SEX‐DETector. Parents and F1 individuals were genotyped, and the transmission patterns of SNPs were then analyzed. In the {\textgreater}1300 sex‐linked genes studied, maximum X‐Y divergence was 0.13–0.17, and substantial Y degeneration is implied by an average Y/X expression ratio of 0.63 and an inferred gene loss on the Y of {\~{}}40{\%}. We also found reduced Y gene expression being compensated by elevated expression of corresponding genes on the X and an excess of sex‐biased genes on the sex chromosomes. Molecular evolution of sex‐linked genes in C. grandis is thus comparable to that in Silene latifolia, another dioecious plant with a strongly heteromorphic XY system, and cucurbits are the fourth plant family in which dosage compensation is described, suggesting it might be common in plants.}, author = {Fruchard, C{\'{e}}cile and Badouin, H{\'{e}}l{\`{e}}ne and Latrasse, David and Devani, Ravi S. and Muyle, Aline and Rhon{\'{e}}, B{\'{e}}n{\'{e}}dicte and Renner, Susanne S. and Banerjee, Anjan K. and Bendahmane, Abdelhafid and Marais, Gabriel A.B.}, doi = {10.3390/genes11070787}, issn = {20734425}, journal = {Genes}, keywords = {Cucurbits,Dioecy,Sex chromosomes,Sex‐biased genes,Y degeneration}, number = {7}, pages = {1--18}, pmid = {32668777}, title = {{Evidence for dosage compensation in coccinia grandis, a plant with a highly heteromorphic xy system}}, url = {https://www.mdpi.com/767944}, volume = {11}, year = {2020} } @article{Miele2020, abstract = {Reliable identification of species is a key step to assess biodiversity. In fossil and archaeological contexts, genetic identifications remain often difficult or even impossible and morphological criteria are the only window on past biodiversity. Methods of numerical taxonomy based on geometric morphometric provide reliable identifications at the specific and even intraspecific levels, but they remain relatively time consuming and require expertise on the group under study. Here, we explore an alternative based on computer vision and machine learning. The identification of three rodent species based on pictures of their molar tooth row constituted the case study. We focused on the first upper molar in order to transfer the model elaborated on modern, genetically identified specimens to isolated fossil teeth. A pipeline based on deep neural network automatically cropped the first molar from the pictures, and returned a prediction regarding species identification. The deep-learning approach performed equally good as geometric morphometrics and, provided an extensive reference dataset including fossil teeth, it was able to successfully identify teeth from an archaeological deposit that was not included in the training dataset. This is a proof-of-concept that such methods could allow fast and reliable identification of extensive amounts of fossil remains, often left unstudied in archaeological deposits for lack of time and expertise. Deep-learning methods may thus allow new insights on the biodiversity dynamics across the last 10.000 years, including the role of humans in extinction or recent evolution.}, author = {Miele, Vincent and Dussert, Gaspard and Cucchi, Thomas and Renaud, Sabrina}, issn = {26928205}, journal = {bioRxiv}, pages = {1--27}, title = {{Deep learning for species identification of modern and fossil rodent molars}}, url = {https://hal.archives-ouvertes.fr/hal-03024134}, year = {2020} } @article{Lambert2020, abstract = {Heterogeneity of infectious disease transmission can be generated by individual differences in the frequency of contacts with susceptible individuals, in the ability to transmit the infectious agent or in the duration of infection, and by spatial variation in the distribution, density or movements of hosts. Identifying spatial and individual heterogeneity can help improving management strategies to eradicate or mitigate infectious diseases, by targeting the individuals or areas that are responsible for most transmissions. Individual-based models allow quantifying the respective role of these sources of heterogeneity by integrating potential mechanisms that generate heterogeneity and then by tracking transmissions caused by each infected individual. In this study, we provide an individual-based model of endemic brucellosis Brucella melitensis transmission in the population of Alpine ibex (Capra ibex) of the Bargy massif (France) by taking advantage of detailed information available on ibex population dynamics, behaviour, and habitat use, and on epidemiological surveys. This host-pathogen system is expected to be subject of both individual and spatial heterogeneity. We first estimated the transmission probabilities, hitherto unknown, of the two main transmission routes of the infection (i.e., exposure to infectious births/abortions and venereal transmission). Then, we quantified heterogeneity at both individual and spatial levels. We found that both transmission routes are not negligible to explain the data, and that there is a high amount of heterogeneity of the host-pathogen system at the individual level, with females generating around 90{\%} of the new cases of brucellosis infection. Males transmit infection at a lesser extent but still play a non-negligible role because they move between subpopulations and thereby create opportunities for spreading the infection spatially by venereal transmission. Two particular socio-spatial units are hotspots of transmission, and act as sources of transmission for the other units. These results may have important implications for disease management strategies.}, author = {Lambert, S{\'{e}}bastien and Gilot-Fromont, Emmanuelle and To{\"{i}}go, Carole and Marchand, Pascal and Petit, Elodie and Garin-Bastuji, Bruno and Gauthier, Dominique and Gaillard, Jean Michel and Rossi, Sophie and Th{\'{e}}bault, Anne}, doi = {10.1016/j.ecolmodel.2020.109009}, issn = {03043800}, journal = {Ecological Modelling}, keywords = {Disease ecology,Epidemiology,Metapopulation,Superspreading,Transmission routes,Wildlife disease}, title = {{An individual-based model to assess the spatial and individual heterogeneity of Brucella melitensis transmission in Alpine ibex}}, url = {https://www.sciencedirect.com/science/article/pii/S0304380020300818}, volume = {425}, year = {2020} } @article{Roy2020, abstract = {Transposable elements (TEs) are genomic parasites that are found in all genomes, some of which display sequence similarity to certain viruses. In insects, TEs are controlled by the Piwi-interacting small interfering RNA (piRNA) pathway in gonads, while the small interfering RNA (siRNA) pathway is dedicated to TE somatic control and defense against viruses. So far, these two small interfering RNA pathways are considered to involve distinct molecular effectors and are described as independent. Using Sindbis virus (SINV) in Drosophila, here we show that viral infections affect TE transcript amounts via modulations of the piRNA and siRNA repertoires, with the clearest effects in somatic tissues. These results suggest that viral acute or chronic infections may impact TE activity and, thus, the tempo of genetic diversification. In addition, these results deserve further evolutionary considerations regarding potential benefits to the host, the virus, or the TEs.}, author = {Roy, Marl{\`{e}}ne and Viginier, Barbara and Saint-Michel, {\'{E}}douard and Arnaud, Fr{\'{e}}d{\'{e}}rick and Ratinier, Maxime and Fablet, Marie}, doi = {10.1073/pnas.2006106117}, issn = {10916490}, journal = {Proceedings of the National Academy of Sciences of the United States of America}, keywords = {Insect,SINV,SiRNA,Transposon,piRNA}, number = {22}, pmid = {32434916}, title = {{Viral infection impacts transposable element transcript amounts in Drosophila}}, url = {https://www.pnas.org/content/117/22/12249.short}, volume = {117}, year = {2020} } @article{Schermer2020, abstract = {Many perennial plants display masting, that is, fruiting with strong interannual variations, irregular and synchronized between trees within the population. Here, we tested the hypothesis that the early flower phenology in temperate oak species promotes stochasticity into their fruiting dynamics, which could play a major role in tree reproductive success. From a large field monitoring network, we compared the pollen phenology between temperate and Mediterranean oak species. Then, focusing on temperate oak species, we explored the influence of the weather around the time of budburst and flowering on seed production, and simulated with a mechanistic model the consequences that an evolutionary shifting of flower phenology would have on fruiting dynamics. Temperate oak species release pollen earlier in the season than do Mediterranean oak species. Such early flowering in temperate oak species results in pollen often being released during unfavorable weather conditions and frequently results in reproductive failure. If pollen release were delayed as a result of natural selection, fruiting dynamics would exhibit much reduced stochastic variation. We propose that early flower phenology might be adaptive by making mast-seeding years rare and unpredictable, which would greatly help in controlling the dynamics of seed consumers.}, author = {Schermer, {\'{E}}liane and Bel-Venner, Marie Claude and Gaillard, Jean Michel and Dray, St{\'{e}}phane and Boulanger, Vincent and {Le Ronc{\'{e}}}, Iris and Oliver, Gilles and Chuine, Isabelle and Delzon, Sylvain and Venner, Samuel}, doi = {10.1111/nph.16224}, issn = {14698137}, journal = {New Phytologist}, keywords = {masting,oak species,pollen phenology,resource budget model,stochastic mast seeding}, number = {3}, pages = {1181--1192}, pmid = {31569273}, title = {{Flower phenology as a disruptor of the fruiting dynamics in temperate oak species}}, url = {https://nph.onlinelibrary.wiley.com/doi/abs/10.1111/nph.16224}, volume = {225}, year = {2020} } @article{Shearn2020, abstract = {Sex chromosomes are typically comprised of a non-recombining region and a recombining pseudoautosomal region. Accurately quantifying the relative size of these regions is critical for sex-chromosome biology both from a functional and evolutionary perspective. The evolution of the pseudoautosomal boundary (PAB) is well documented in haplorrhines (apes and monkeys) but not in strepsirrhines (lemurs and lorises). Here, we studied the PAB of seven species representing the main strepsirrhine lineages by sequencing a male and a female genome in each species and using sex differences in coverage to identify the PAB. We found that during primate evolution, the PAB has remained unchanged in strepsirrhines whereas several recombination suppression events moved the PAB and shortened the pseudoautosomal region in haplorrhines. Strepsirrhines are well known to have much lower sexual dimorphism than haplorrhines. We suggest that mutations with antagonistic effects between males and females have driven recombination suppression and PAB evolution in haplorrhines.}, author = {Shearn, Rylan and Wright, Alison E. and Mousset, Sylvain and R{\'{e}}gis, Corinne and Penel, Simon and Lemaitre, Jean Fran{\c{c}}ois and Douay, Guillaume and Crouau-Roy, Brigitte and Lecompte, Emilie and Marais, Gabriel A.B.}, doi = {10.7554/eLife.63650}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Shearn et al/eLife/eLife{\_}Shearn et al.{\_}Evolutionary stasis of the pseudoautosomal boundary in strepsirrhine primates{\_}2020.pdf:pdf}, issn = {2050084X}, journal = {eLife}, pages = {1--16}, pmid = {33205751}, title = {{Evolutionary stasis of the pseudoautosomal boundary in strepsirrhine primates}}, url = {https://www.researchgate.net/profile/Gabriel-Marais/publication/328323151{\_}Contrasted{\_}sex{\_}chromosome{\_}evolution{\_}in{\_}primates{\_}with{\_}and{\_}without{\_}sexual{\_}dimorphism/links/60476d184585154e8c87e6f4/Contrasted-sex-chromosome-evolution-in-primates-with-and-without-se}, volume = {9}, year = {2020} } @article{Prentout2020, abstract = {Cannabis sativa-derived tetrahydrocannabinol (THC) production is increasing very fast worldwide. C. sativa is a dioecious plant with XY Chromosomes, and only females (XX) are useful for THC production. Identifying the sex chromosome sequence would improve early sexing and better management of this crop; however, the C. sativa genome projects have failed to do so. Moreover, as dioecy in the Cannabaceae family is ancestral, C. sativa sex chromosomes are potentially old and thus very interesting to study, as little is known about old plant sex chromosomes. Here, we RNA-sequenced a C. sativa family (two parents and 10 male and female offspring, 576 million reads) and performed a segregation analysis for all C. sativa genes using the probabilistic method SEX-DETector. We identified {\textgreater}500 sex-linked genes. Mapping of these sex-linked genes to a C. sativa genome assembly identified the largest chromosome pair being the sex chromosomes. We found that the X-specific region (not recombining between X and Y) is large compared to other plant systems. Further analysis of the sex-linked genes revealed that C. sativa has a strongly degenerated Y Chromosome and may represent the oldest plant sex chromosome system documented so far. Our study revealed that old plant sex chromosomes can have large, highly divergent nonrecombining regions, yet still be roughly homomorphic.}, author = {Prentout, Djivan and Razumova, Olga and Rhon{\'{e}}, B{\'{e}}n{\'{e}}dicte and Badouin, H{\'{e}}l{\`{e}}ne and Henri, H{\'{e}}l{\`{e}}ne and Feng, Cong and K{\"{a}}fer, Jos and Karlov, Gennady and Marais, Gabriel A.B.}, doi = {10.1101/gr.251207.119}, issn = {15495469}, journal = {Genome Research}, number = {2}, pages = {164--172}, pmid = {32033943}, title = {{An efficient RNA-seq-based segregation analysis identifies the sex chromosomes of Cannabis sativa}}, url = {http://www.genome.org/cgi/doi/10.1101/gr.251207.119.}, volume = {30}, year = {2020} } @article{Chevret2020, abstract = {Water voles from the genus Arvicola display an amazing ecological versatility, with aquatic and fossorial populations. The Southern water vole (Arvicola sapidus) is largely accepted as a valid species, as well as the newly described Arvicola persicus. In contrast, the taxonomic status and evolutionary relationships within Arvicola amphibius sensu lato had caused a long-standing debate. The phylogenetic relationships among Arvicola were reconstructed using the mitochondrial cytochrome b gene. Four lineages within A. amphibius s.l. were identified with good support: Western European, Eurasiatic, Italian, and Turkish lineages. Fossorial and aquatic forms were found together in all well-sampled lineages, evidencing that ecotypes do not correspond to distinct species. However, the Western European lineage mostly includes fossorial forms whereas the Eurasiatic lineage tends to include mostly aquatic forms. A morphometric analysis of skull shape evidenced a convergence of aquatic forms of the Eurasiatic lineage toward the typically aquatic shape of A. sapidus. The fossorial form of the Western European lineage, in contrast, displayed morphological adaptation to tooth-digging behavior, with expanded zygomatic arches and proodont incisors. Fossorial Eurasiatic forms displayed intermediate morphologies. This suggests a plastic component of skull shape variation, combined with a genetic component selected by the dominant ecology in each lineage. Integrating genetic distances and other biological data suggest that the Italian lineage may correspond to an incipient species (Arvicola italicus). The three other lineages most probably correspond to phylogeographic variations of a single species (A. amphibius), encompassing the former A. amphibius, Arvicola terrestris, Arvicola scherman, and Arvicola monticola.}, author = {Chevret, Pascale and Renaud, Sabrina and Helvaci, Zeycan and Ulrich, Rainer G. and Qu{\'{e}}r{\'{e}}, Jean Pierre and Michaux, Johan R.}, doi = {10.1111/jzs.12384}, issn = {14390469}, journal = {Journal of Zoological Systematics and Evolutionary Research}, keywords = {Arvicola amphibius,cytochrome b,geometric morphometrics,phylogeography,plasticity}, number = {4}, pages = {1323--1334}, title = {{Genetic structure, ecological versatility, and skull shape differentiation in Arvicola water voles (Rodentia, Cricetidae)}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/jzs.12384}, volume = {58}, year = {2020} } @article{Cariou2020, abstract = {Promoted by the barcoding approach, mitochondrial DNA is more than ever used as a molecular marker to identify species boundaries. Yet, it has been repeatedly argued that it may be poorly suited for this purpose, especially in insects where mitochondria are often associated with invasive intracellular bacteria that may promote their introgression. Here, we inform this debate by assessing how divergent nuclear genomes can be when mitochondrial barcodes indicate very high proximity. To this end, we obtained RAD-seq data from 92 barcode-based species-like units (operational taxonomic units [OTUs]) spanning four insect orders. In 100{\%} of the cases, the observed median nuclear divergence was lower than 2{\%}, a value that was recently estimated as one below which nuclear gene flow is not uncommon. These results suggest that although mitochondria may occasionally leak between species, this process is rare enough in insects to make DNA barcoding a reliable tool for clustering specimens into species-like units.}, author = {Cariou, Marie and Henri, H{\'{e}}l{\`{e}}ne and Martinez, Sonia and Duret, Laurent and Charlat, Sylvain}, doi = {10.1111/1755-0998.13178}, issn = {17550998}, journal = {Molecular Ecology Resources}, keywords = {RAD-seq,barcode,divergence,mitochondria}, number = {5}, pages = {1294--1298}, pmid = {32340081}, title = {{How consistent is RAD-seq divergence with DNA-barcode based clustering in insects?}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/1755-0998.13178}, volume = {20}, year = {2020} } @article{Shearn2020a, abstract = {Sex chromosomes are typically comprised of a non-recombining region and a recombining pseudoautosomal region. Accurately quantifying the relative size of these regions is critical for sex-chromosome biology both from a functional and evolutionary perspective. The evolution of the pseudoautosomal boundary (PAB) is well documented in haplorrhines (apes and monkeys) but not in strepsirrhines (lemurs and lorises). Here, we studied the PAB of seven species representing the main strepsirrhine lineages by sequencing a male and a female genome in each species and using sex differences in coverage to identify the PAB. We found that during primate evolution, the PAB has remained unchanged in strepsirrhines whereas several recombination suppression events moved the PAB and shortened the pseudoautosomal region in haplorrhines. Strepsirrhines are well known to have much lower sexual dimorphism than haplorrhines. We suggest that mutations with antagonistic effects between males and females have driven recombination suppression and PAB evolution in haplorrhines.}, author = {Shearn, Rylan and Wright, Alison E. and Mousset, Sylvain and R{\'{e}}gis, Corinne and Penel, Simon and Lemaitre, Jean Fran{\c{c}}ois and Douay, Guillaume and Crouau-Roy, Brigitte and Lecompte, Emilie and Marais, Gabriel A.B.}, doi = {10.7554/eLife.63650}, issn = {2050084X}, journal = {eLife}, pages = {1--16}, pmid = {33205751}, title = {{Evolutionary stasis of the pseudoautosomal boundary in strepsirrhine primates}}, url = {https://elifesciences.org/articles/63650}, volume = {9}, year = {2020} } @article{Chevret2020a, abstract = {Water voles from the genus Arvicola display an amazing ecological versatility, with aquatic and fossorial populations. The Southern water vole (Arvicola sapidus) is largely accepted as a valid species, as well as the newly described Arvicola persicus. In contrast, the taxonomic status and evolutionary relationships within Arvicola amphibius sensu lato had caused a long-standing debate. The phylogenetic relationships among Arvicola were reconstructed using the mitochondrial cytochrome b gene. Four lineages within A. amphibius s.l. were identified with good support: Western European, Eurasiatic, Italian, and Turkish lineages. Fossorial and aquatic forms were found together in all well-sampled lineages, evidencing that ecotypes do not correspond to distinct species. However, the Western European lineage mostly includes fossorial forms whereas the Eurasiatic lineage tends to include mostly aquatic forms. A morphometric analysis of skull shape evidenced a convergence of aquatic forms of the Eurasiatic lineage toward the typically aquatic shape of A. sapidus. The fossorial form of the Western European lineage, in contrast, displayed morphological adaptation to tooth-digging behavior, with expanded zygomatic arches and proodont incisors. Fossorial Eurasiatic forms displayed intermediate morphologies. This suggests a plastic component of skull shape variation, combined with a genetic component selected by the dominant ecology in each lineage. Integrating genetic distances and other biological data suggest that the Italian lineage may correspond to an incipient species (Arvicola italicus). The three other lineages most probably correspond to phylogeographic variations of a single species (A. amphibius), encompassing the former A. amphibius, Arvicola terrestris, Arvicola scherman, and Arvicola monticola.}, author = {Chevret, Pascale and Renaud, Sabrina and Helvaci, Zeycan and Ulrich, Rainer G. and Qu{\'{e}}r{\'{e}}, Jean Pierre and Michaux, Johan R.}, doi = {10.1111/jzs.12384}, issn = {14390469}, journal = {Journal of Zoological Systematics and Evolutionary Research}, keywords = {Arvicola amphibius,cytochrome b,geometric morphometrics,phylogeography,plasticity}, month = {nov}, number = {4}, pages = {1323--1334}, publisher = {Blackwell Publishing Ltd}, title = {{Genetic structure, ecological versatility, and skull shape differentiation in Arvicola water voles (Rodentia, Cricetidae)}}, volume = {58}, year = {2020} } @article{Fraisse2020, abstract = {W e present DILS, an online statistical analysis platform for conducting demographic inferences with linked selection from population genomic data using an Approximate Bayesian Computation framework. DILS takes as input single-population or two-population datasets and performs three types of analyses in a hierarchical manner, identifying: 1) the best demographic model to study the importance of gene flow and population size change on the genetic patterns of polymorphism and divergence, 2) the best genomic model to determine whether the effective size N e and migration rate N.m are heterogeneously distributed along the genome and 3) loci in genomic regions most associated with barriers to gene flow. Available via a web interface, an objective of DILS is to facilitate collaborative research in speciation genomics. Here, we show the performance and limitations of DILS by using simulations , and finally apply the method to published data on a divergence continuum composed by 28 pairs of M ytilus mussel populations/species.}, author = {Fra{\"{i}}sse, Christelle and Popovic, Iva and Mazoyer, Cl{\'{e}}ment and Spataro, Bruno and Delmotte, Stephane and Romiguier, Jonathan and Loire, Etienne and Simon, Alexis and Galtier, Nicolas and Duret, Laurent and Fra, Christelle and ement Mazoyer, C{\'{i}} and Bierne, Nicolas and Vekemans, Xavier and Roux, Camille}, doi = {10.1111/1755-0998.13323ï}, journal = {Wiley Online Library}, title = {{DILS: Demographic inferences with linked selection by using ABC DILS : Demographic Inferences with Linked Selection}}, url = {https://hal.inrae.fr/hal-03156998}, year = {2020} } @article{Ashraf2020, abstract = {{\textless}p{\textgreater}Influenza A viruses (IAVs) use diverse mechanisms to interfere with cellular gene expression. Although many RNA-seq studies have documented IAV-induced changes in host mRNA abundance, few were designed to allow an accurate quantification of changes in host mRNA splicing. Here, we show that IAV infection of human lung cells induces widespread alterations of cellular splicing, with an overall increase in exon inclusion and decrease in intron retention. Over half of the mRNAs that show differential splicing undergo no significant changes in abundance or in their 3′ end termination site, suggesting that IAVs can specifically manipulate cellular splicing. Among a randomly selected subset of 21 IAV-sensitive alternative splicing events, most are specific to IAV infection as they are not observed upon infection with VSV, induction of interferon expression or induction of an osmotic stress. Finally, the analysis of splicing changes in RED-depleted cells reveals a limited but significant overlap with the splicing changes in IAV-infected cells. This observation suggests that hijacking of RED by IAVs to promote splicing of the abundant viral NS1 mRNAs could partially divert RED from its target mRNAs. All our RNA-seq datasets and analyses are made accessible for browsing through a user-friendly Shiny interface (http://virhostnet.prabi.fr:3838/shinyapps/flu-splicing or https://github.com/cbenoitp/flu-splicing).{\textless}/p{\textgreater}}, author = {Ashraf, Usama and Benoit-Pilven, Clara and Navratil, Vincent and Ligneau, C{\'{e}}cile and Fournier, Guillaume and Munier, Sandie and Sismeiro, Odile and Copp{\'{e}}e, Jean-Yves and Lacroix, Vincent and Naffakh, Nadia}, doi = {10.1093/nargab/lqaa095}, issn = {2631-9268}, journal = {NAR Genomics and Bioinformatics}, month = {nov}, number = {4}, publisher = {Oxford Academic}, title = {{Influenza virus infection induces widespread alterations of host cell splicing}}, url = {https://academic.oup.com/nargab/article/doi/10.1093/nargab/lqaa095/5998301}, volume = {2}, year = {2020} } @article{Sabatier2020, abstract = {{\textless}p{\textgreater}Viral metagenomics next-generation sequencing (mNGS) is increasingly being used to characterize the human virome. The impact of viral nucleic extraction on virome profiling has been poorly studied. Here, we aimed to compare the sensitivity and sample and reagent contamination of three extraction methods used for viral mNGS: two automated platforms (eMAG; MagNA Pure 24, MP24) and the manual QIAamp Viral RNA Mini Kit (QIAamp). Clinical respiratory samples (positive for Respiratory Syncytial Virus or Herpes Simplex Virus), one mock sample (including five viruses isolated from respiratory samples), and a no-template control (NTC) were extracted and processed through an mNGS workflow. QIAamp yielded a lower proportion of viral reads for both clinical and mock samples. The sample cross-contamination was higher when using MP24, with up to 36.09{\%} of the viral reads mapping to mock viruses in the NTC (vs. 1.53{\%} and 1.45{\%} for eMAG and QIAamp, respectively). The highest number of viral reads mapping to bacteriophages in the NTC was found with QIAamp, suggesting reagent contamination. Our results highlight the importance of the extraction method choice for accurate virome characterization.{\textless}/p{\textgreater}}, author = {Sabatier, Marina and Bal, Antonin and Destras, Gr{\'{e}}gory and Regue, Hadrien and Qu{\'{e}}rom{\`{e}}s, Gr{\'{e}}gory and Cheynet, Val{\'{e}}rie and Lina, Bruno and Bardel, Claire and Brengel-Pesce, Karen and Navratil, Vincent and Josset, Laurence}, doi = {10.3390/microorganisms8101539}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Sabatier et al/Microorganisms/Microorganisms{\_}Sabatier et al.{\_}Comparison of Nucleic Acid Extraction Methods for a Viral Metagenomics Analysis of Respiratory Viruses{\_}20.pdf:pdf}, issn = {2076-2607}, journal = {Microorganisms}, keywords = {acid nucleic extraction,kitome,next-generation sequencing,sample cross-contamination,viral metagenomics}, month = {oct}, number = {10}, pages = {1539}, publisher = {Multidisciplinary Digital Publishing Institute}, title = {{Comparison of Nucleic Acid Extraction Methods for a Viral Metagenomics Analysis of Respiratory Viruses}}, url = {https://www.mdpi.com/2076-2607/8/10/1539}, volume = {8}, year = {2020} } @article{Navratil2020, abstract = {Following the Severe Acute Respiratory Syndrome coronavirus (SARS-CoV) in 2002 and Middle East Respiratory Syndrome coronavirus (MERS-CoV) in 2012, the novel coronavirus SARS-CoV-2 emerged at the end of 2019 as a highly pathogenic infectious agent that rapidly spread around the world. SARS-CoV-2 shares high sequence homology with SARS-CoV and causes acute, highly lethal pneumonia coronavirus disease 2019 (COVID-19) with clinical symptoms similar to those reported for SARS-CoV. Like other betacoronaviruses, SARS-CoV-2 encode four major structural proteins: Spike (S), Membrane (M), Nucleocapsid (N) and Envelope (E). SARS-CoV E protein is abundant in infected cells and plays a crucial role in viral particle assembly. Moreover, SARS coronaviruses lacking E are attenuated in vivo, suggesting that CoV E may act as a critical virulence factor not only in SARS-CoV but also in the case of the new coronavirus SARS-CoV-2. Ectopic expression of SARS-CoV E was previously shown to trigger apoptosis (cell suicide) of T lymphocytes, lymphopenia being a common feature observed in fatal cases following viral infections. Importantly, T-cell apoptosis was shown to involve interaction between the C-terminal region of SARS-CoV E and the Bcl-2 family member Bcl-xL, which acts as a potent anti-apoptotic protein. Here we provide the first observation that the SARS-CoV E and SARS-CoV-2 E proteins share a conserved Bcl-2 Homology 3 (BH3)-like motif in their C-terminal region, a well-studied motif shown to be necessary for SARS-CoV E binding to Bcl-xL. We used available sequence data for SARS-CoV-2 and related coronaviruses, in combination with structural information, to study the structure to biological activity relationships of SARS-CoV-2 E in relation with its BH3-like motif. Our analysis of the SARS-CoV E interactome further revealed that the predicted SARS-CoV-2 network is extensively wired to the Bcl-2 apoptotic switch. Research is therefore needed to establish if SARS-CoV-2 E targets prosurvival Bcl-2 homologs to modulate cell viability, as part of a coronavirus strategy to interfere with apoptosis. The identification of small molecules (or the repurposing of existing drugs) able to disrupt SARS-CoV-2 E BH3-mediated interactions might provide a targeted therapeutic approach for COVID-19 treatment. Recombinant SARS-CoV-2 expressing an E protein with a deleted or mutated BH3-like motif might also be of interest for the design of a live, attenuated vaccine. {\#}{\#}{\#} Competing Interest Statement The authors have declared no competing interest.}, author = {Navratil, Vincent and Lionnard, Loic and Longhi, Sonia and Combet, Christophe and Aouacheria, Abdel}, doi = {10.1101/2020.04.09.033522}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Navratil et al/bioRxiv/bioRxiv{\_}Navratil et al.{\_}The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) envelope (E) protein harbors a conserved BH3-li.pdf:pdf}, journal = {bioRxiv}, month = {jun}, pages = {2020.04.09.033522}, publisher = {Cold Spring Harbor Laboratory}, title = {{The severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) envelope (E) protein harbors a conserved BH3-like motif}}, url = {https://doi.org/10.1101/2020.04.09.033522}, year = {2020} } @article{Durand2020, abstract = {Osteoarthritis (OA) is a degenerative disease of the joints which is associated with an impaired production of the cartilage matrix by the chondrocytes. Here, we investigated the role of Lysine-Specific Demethylase-1 (LSD1), a chromatin remodeling enzyme whose role in articular chondrocytes was previously associated with a catabolic activity and which is potentially involved during OA. Following a loss of function strategy and RNA sequencing analysis, we detail the genes which are targeted by LSD1 in human articular chondrocytes and identify COL9A1, a gene encoding the $\alpha$1 chain of the cartilage-specific type IX collagen, as negatively regulated by LSD1. We show that LSD1 interacts with the transcription factor SOX9 and is recruited to the promoter of COL9A1. Interestingly, we observe that OA cartilage displays stronger LSD1 immunostaining compared with normal, and we demonstrate that the depletion of LSD1 in OA chondrocytes prevents the decrease in COL9A1 following Il-1$\beta$ treatment. These results suggest LSD1 is a new regulator of the anabolic activity of articular chondrocytes potentially destabilizing the cartilage matrix, since it negatively regulates COL9A1, a gene encoding a crucial anchoring collagen molecule. This newly identified role played by LSD1 may thus participate in the alteration of the cartilage matrix during OA.}, author = {Durand, Anne Laure and Dufour, Alexandre and Aubert-Foucher, Elisabeth and Oger-Desfeux, Christine and Pasdeloup, Marielle and Lustig, Sebastien and Servien, Elvire and Vaz, Gualter and Perrier-Groult, Emeline and Mallein-Gerin, Frederic and Lafont, Jerome E.}, doi = {10.3390/ijms21176322}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Durand et al/International Journal of Molecular Sciences/International Journal of Molecular Sciences{\_}Durand et al.{\_}The lysine specific demethylase-1 negatively regulates the COL9A1 gene in huma.pdf:pdf}, issn = {14220067}, journal = {International Journal of Molecular Sciences}, keywords = {Articular chondrocytes,Lysine demethylase,Osteoarthritis,Type IX collagen}, month = {sep}, number = {17}, pages = {1--16}, pmid = {32878268}, publisher = {MDPI AG}, title = {{The lysine specific demethylase-1 negatively regulates the COL9A1 gene in human articular chondrocytes}}, volume = {21}, year = {2020} } @article{Badouin2020, abstract = {BACKGROUND: A key step in domestication of the grapevine was the transition from separate sexes (dioecy) in wild Vitis vinifera ssp. sylvestris (V. sylvestris) to hermaphroditism in cultivated Vitis vinifera ssp. sativa (V. vinifera). It is known that V. sylvestris has an XY system and V. vinifera a modified Y haplotype (Yh) and that the sex locus is small, but it has not previously been precisely characterized. RESULTS: We generate a high-quality de novo reference genome for V. sylvestris, onto which we map whole-genome re-sequencing data of a cross to locate the sex locus. Assembly of the full X, Y, and Yh haplotypes of V. sylvestris and V. vinifera sex locus and examining their gene content and expression profiles during flower development in wild and cultivated accessions show that truncation and deletion of tapetum and pollen development genes on the X haplotype likely causes male sterility, while the upregulation of a Y allele of a cytokinin regulator (APRT3) may cause female sterility. The downregulation of this cytokinin regulator in the Yh haplotype may be sufficient to trigger reversal to hermaphroditism. Molecular dating of X and Y haplotypes is consistent with the sex locus being as old as the Vitis genus, but the mechanism by which recombination was suppressed remains undetermined. CONCLUSIONS: We describe the genomic and evolutionary characterization of the sex locus of cultivated and wild grapevine, providing a coherent model of sex determination in the latter and for transition from dioecy to hermaphroditism during domestication.}, author = {Badouin, H{\'{e}}l{\`{e}}ne and Velt, Amandine and Gindraud, Fran{\c{c}}ois and Flutre, Timoth{\'{e}}e and Dumas, Vincent and Vautrin, Sonia and Marande, William and Corbi, Jonathan and Sallet, Erika and Ganofsky, J{\'{e}}r{\'{e}}my and Santoni, Sylvain and Guyot, Dominique and Ricciardelli, Eugenia and Jepsen, Kristen and K{\"{a}}fer, Jos and Berges, H{\'{e}}l{\`{e}}ne and Duch{\^{e}}ne, Eric and Picard, Franck and Hugueney, Philippe and Tavares, Raquel and Bacilieri, Roberto and Rustenholz, Camille and Marais, Gabriel A.B.}, doi = {10.1186/s13059-020-02131-y}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Badouin et al/Genome biology/Genome biology{\_}Badouin et al.{\_}The wild grape genome sequence provides insights into the transition from dioecy to hermaphroditism during.pdf:pdf}, issn = {1474760X}, journal = {Genome biology}, keywords = {Dioecy,Grapevine,Sex chromosomes,Sex-determining genes}, month = {sep}, number = {1}, pages = {223}, pmid = {32892750}, publisher = {NLM (Medline)}, title = {{The wild grape genome sequence provides insights into the transition from dioecy to hermaphroditism during grape domestication}}, volume = {21}, year = {2020} } @phdthesis{Cury2019, author = {Cury, Jean}, keywords = {Bioinformaticsbio,structural biology and genomics}, title = {{Evolutionary genomics of conjugative elements and integrons}}, url = {https://tel.archives-ouvertes.fr/tel-02130756/document https://tel.archives-ouvertes.fr/tel-02130756}, year = {2019} } @article{Cologne2019, author = {Cologne, A}, file = {:Users/navratil/Documents/Mendeley Desktop/2019/Cologne/Unknown/Unknown{\_}Cologne{\_}Exploration du r{\^{o}}le de l'{\'{e}}pissage mineur dans le d{\'{e}}veloppement embryonnaire mod{\`{e}}le du syndrome de Taybi-Linder)(TALS.pdf:pdf}, title = {{Exploration du r{\^{o}}le de l'{\'{e}}pissage mineur dans le d{\'{e}}veloppement embryonnaire: mod{\`{e}}le du syndrome de Taybi-Linder)(TALS)}}, url = {https://tel.archives-ouvertes.fr/tel-02363211/}, year = {2019} } @article{Bourg2019, abstract = {Recent empirical evidence suggests that trade-off relationships can evolve, challenging the classical image of their high entrenchment. For energy reliant traits, this relationship should depend on the endocrine system that regulates resource allocation. Here, we model changes in this system by mutating the expression and conformation of its constitutive hormones and receptors. We show that the shape of trade-offs can indeed evolve in this model through the combined action of genetic drift and selection, such that their evolutionarily expected curvature and length depend on context. In particular, the shape of a trade-off should depend on the cost associated with resource storage, itself depending on the traded resource and on the ecological context. Despite this convergence at the phenotypic level, we show that a variety of physiological mechanisms may evolve in similar simulations, suggesting redundancy at the genetic level. This model should provide a useful framework to interpret and unify the overly complex observations of evolutionary endocrinology and evolutionary ecology.}, author = {Bourg, Salom{\'{e}} and Jacob, Laurent and Menu, Fr{\'{e}}d{\'{e}}ric and Rajon, Etienne}, doi = {10.1111/evo.13693}, issn = {15585646}, journal = {Evolution}, keywords = {Evolutionary endocrinology,evolutionary constraints,hormonal pleiotropy,resource allocation,storage cost,trade-offs}, number = {4}, pages = {661--674}, pmid = {30734273}, title = {{Hormonal pleiotropy and the evolution of allocation trade-offs}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/evo.13693}, volume = {73}, year = {2019} } @article{Durif2019, abstract = {The development of high-throughput single-cell sequencing technologies now allows the investigation of the population diversity of cellular transcriptomes. The expression dynamics (gene-to-gene variability) can be quantified more accurately, thanks to the measurement of lowly expressed genes. In addition, the cell-to-cell variability is high, with a low proportion of cells expressing the same genes at the same time/level. Those emerging patterns appear to be very challenging from the statistical point of view, especially to represent a summarized view of single-cell expression data. Principal component analysis (PCA) is a most powerful tool for high dimensional data representation, by searching for latent directions catching the most variability in the data. Unfortunately, classical PCA is based on Euclidean distance and projections that poorly work in presence of over-dispersed count data with dropout events like single-cell expression data. Results: We propose a probabilistic Count Matrix Factorization (pCMF) approach for single-cell expression data analysis that relies on a sparse Gamma-Poisson factor model. This hierarchical model is inferred using a variational EM algorithm. It is able to jointly build a low dimensional representation of cells and genes. We show how this probabilistic framework induces a geometry that is suitable for single-cell data visualization, and produces a compression of the data that is very powerful for clustering purposes. Our method is competed against other standard representation methods like t-SNE, and we illustrate its performance for the representation of single-cell expression data. Availability and implementation: Our work is implemented in the pCMF R-package (https://github.com/gdurif/pCMF). Supplementary information: Supplementary data are available at Bioinformatics online.}, archivePrefix = {arXiv}, arxivId = {1710.11028}, author = {Durif, Ghislain and Modolo, Laurent and Mold, Jeff E. and Lambert-Lacroix, Sophie and Picard, Franck}, doi = {10.1093/bioinformatics/btz177}, eprint = {1710.11028}, file = {:Users/navratil/Documents/Mendeley Desktop/Unknown/Durif et al/academic.oup.com/academic.oup.com{\_}Durif et al.{\_}Probabilistic count matrix factorization for single cell expression data analysis{\_}Unknown.pdf:pdf}, issn = {14602059}, journal = {Bioinformatics}, number = {20}, pages = {4011--4019}, pmid = {30865271}, title = {{Probabilistic count matrix factorization for single cell expression data analysis}}, url = {https://academic.oup.com/bioinformatics/article-abstract/35/20/4011/5378703}, volume = {35}, year = {2019} } @article{Reiss2019, abstract = {More than any other genome components, Transposable Elements (TEs) have the capacity to move across species barriers through Horizontal Transfer (HT), with substantial evolutionary consequences. Previous large-scale surveys, based on full-genomes comparisons, have revealed the transposition mode as an important predictor of HT rates variation across TE superfamilies. However, host biology could represent another major explanatory factor, one that needs to be investigated through extensive taxonomic sampling. Here we test this hypothesis using a field collection of 460 arthropod species from Tahiti and surrounding islands. Through targeted massive parallel sequencing, we uncover patterns of HT in three widely-distributed TE superfamilies with contrasted modes of transposition. In line with earlier findings, the DNA transposons under study (TC1-Mariner) were found to transfer horizontally at the highest frequency, closely followed by the LTR superfamily (Copia), in contrast with the non-LTR superfamily (Jockey), that mostly diversifies through vertical inheritance and persists longer within genomes. Strikingly, across all superfamilies, we observe a marked excess of HTs in Lepidoptera, an insect order that also commonly hosts baculoviruses, known for their ability to transport host TEs. These results turn the spotlight on baculoviruses as major potential vectors of TEs in arthropods, and further emphasize the importance of non-vertical TE inheritance in genome evolution.}, author = {Reiss, Daphn{\'{e}} and Mialdea, Gladys and Miele, Vincent and de Vienne, Damien M. and Peccoud, Jean and Gilbert, Cl{\'{e}}ment and Duret, Laurent and Charlat, Sylvain}, doi = {10.1371/journal.pgen.1007965}, issn = {15537404}, journal = {PLoS Genetics}, number = {2}, pmid = {30707693}, title = {{Global survey of mobile DNA horizontal transfer in arthropods reveals Lepidoptera as a prime hotspot}}, url = {https://journals.plos.org/plosgenetics/article?id=10.1371/journal.pgen.1007965}, volume = {15}, year = {2019} } @article{Miele2019, abstract = {Ecological communities are undeniably diverse, both in terms of the species that compose them as well as the type of interactions that link species to each other. Despite this long recognition of the coexistence of multiple interaction types in nature, little is known about the consequences of this diversity for community functioning. In the ongoing context of global change and increasing species extinction rates, it seems crucial to improve our understanding of the drivers of the relationship between species diversity and ecosystem functioning. Here, using a multispecies dynamical model of ecological communities including various interaction types (e.g. competition for space, predator interference, recruitment facilitation in addition to feeding), we studied the role of the presence and the intensity of these interactions for species diversity, community functioning (biomass and production) and the relationship between diversity and functioning.Taken jointly, the diverse interactions have significant effects on species diversity, whose amplitude and sign depend on the type of interactions involved and their relative abundance. They however consistently increase the slope of the relationship between diversity and functioning, suggesting that species losses might have stronger effects on community functioning than expected when ignoring the diversity of interaction types and focusing on feeding interactions only.}, author = {Miele, Vincent and Guill, Christian and Ramos-Jiliberto, Rodrigo and K{\'{e}}fi, Sonia}, doi = {10.1371/journal.pcbi.1007269}, file = {:Users/navratil/Documents/Mendeley Desktop/2019/Miele et al/PLoS Computational Biology/PLoS Computational Biology{\_}Miele et al.{\_}Non-trophic interactions strengthen the diversity-functioning relationship in an ecological bioe.pdf:pdf}, issn = {15537358}, journal = {PLoS Computational Biology}, number = {8}, pmid = {31465440}, publisher = {Public Library of Science}, title = {{Non-trophic interactions strengthen the diversity-functioning relationship in an ecological bioenergetic network model}}, volume = {15}, year = {2019} } @article{Crabot2019, abstract = {Mantel tests are widely used in ecology to assess the significance of the relationship between two distance matrices computed between pairs of samples. However, recent studies demonstrated that the presence of spatial autocorrelation in both distance matrices induced inflations of parameter estimates and type I error rates. These results also hold for partial Mantel test which is supposed to control for the spatial structures. To address the issue of spatial autocorrelation in testing the Mantel statistic, we developed a new procedure based on spatially constrained randomizations using Moran spectral randomization. A simulation study was conducted to assess the performance of this new procedure. Different scenarios were considered by manipulating the number of variables, the number of samples, the regularity of the sampling design and the level of spatial autocorrelation. As identified by previous studies, we found that Mantel statistic and its associated type I error rate are inflated in simple and partial Mantel tests when both distances matrices are spatially structured. We showed that these biases increased with the number of variables, decreased with the number of samples and were slightly lower for regular than irregular sampling. The new procedure succeeded in correcting the spurious inflations of the parameter estimates and type I error rates in any of the presented scenarios. Our results suggest that studies from several fields (e.g. genetic or community ecology) could have been overestimating the relationship between two distances matrices when both presented spatial autocorrelation. We proposed an alternative solution applicable in every field to correctly compute Mantel statistic with a fair type I error rate.}, author = {Crabot, Julie and Clappe, Sylvie and Dray, St{\'{e}}phane and Datry, Thibault}, doi = {10.1111/2041-210X.13141}, issn = {2041210X}, journal = {Methods in Ecology and Evolution}, keywords = {Mantel test,Moran spectral randomization,distance decay relationships,principal coordinates analysis,spatial autocorrelation,spatially constrained null model,type I error inflation}, month = {apr}, number = {4}, pages = {532--540}, publisher = {British Ecological Society}, title = {{Testing the Mantel statistic with a spatially-constrained permutation procedure}}, volume = {10}, year = {2019} } @article{Larroque2019, abstract = {Spatial synchrony is a common characteristic of spatio-temporal population dynamics across many taxa. While it is known that both dispersal and spatially autocor-related environmental variation (i.e., the Moran effect) can synchronize populations, the relative contributions of each, and how they interact, are generally unknown. Distinguishing these mechanisms and their effects on synchrony can help us to better understand spatial population dynamics, design conservation and management strategies, and predict climate change impacts. Population genetic data can be used to tease apart these two processes as the spatio-temporal genetic patterns they create are expected to be different. A challenge, however, is that genetic data are often collected at a single point in time, which may introduce context-specific bias. Spatio-temporal sampling strategies can be used to reduce bias and to improve our characterization of the drivers of spatial synchrony. Using spatio-temporal analyses of genotypic data, our objective was to identify the relative support for these two mechanisms to the spatial synchrony in population dynamics of the irruptive forest insect pest, the spruce budworm (Choristoneura fumiferana), in Quebec (Canada). AMOVA, cluster analysis, isolation by distance, and sPCA were used to characterize spatio-temporal genomic variation using 1,370 SBW larvae sampled over four years (2012-2015) and genotyped at 3,562 SNP loci. We found evidence of overall weak spatial genetic structure that decreased from 2012 to 2015 and a genetic diversity homogenization among the sites. We also found genetic evidence of a long-distance dispersal event over {\textgreater}140 km. These results indicate that dispersal is the key mechanism involved in driving population synchrony of the outbreak. Early intervention management strategies that aim to control source populations have the potential to be effective through limiting dispersal. However, the timing of such interventions relative to outbreak progression is likely to influence their probability of success. K E Y W O R D S cyclic populations, insect outbreak, SNP, spatial genetics, spruce budworm, synchrony, temporal genetics}, author = {Larroque, Jeremy and Legault, Simon and Johns, Rob and Lumley, | Lisa and Cusson, Michel and Renaut, S{\'{e}}bastien and Roger, | and Levesque, C and Patrick, | and James, M A}, doi = {10.1111/eva.12852}, journal = {Evolutionary Applications}, keywords = {SNP,cyclic populations,insect outbreak,spatial genetics,spruce budworm,synchrony,temporal genetics}, month = {dec}, number = {10}, pages = {1931--1945}, publisher = {Wiley-Blackwell}, title = {{Temporal variation in spatial genetic structure during population outbreaks: Distinguishing among different potential drivers of spatial synchrony}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/eva.12852}, volume = {12}, year = {2019} } @article{Boussau2019, abstract = {One contribution of 16 to a theme issue 'Convergent evolution in the genomics era: new insights and directions'.}, author = {Boussau, Bastien and Rey, Carine and Lanore, Vincent and Veber, Philippe and Gu{\'{e}}guen, Laurent and Lartillot, Nicolas and S{\'{e}}mon, Marie}, doi = {10.1098/rstb.2018.0234}, file = {:Users/navratil/Documents/Mendeley Desktop/2019/Boussau et al/royalsocietypublishing.org/royalsocietypublishing.org{\_}Boussau et al.{\_}Detecting adaptive convergent amino acid evolution{\_}2019.pdf:pdf}, journal = {royalsocietypublishing.org}, keywords = {C3/C4,Subject Areas: genomics,bioinformatics,computational biology Keywords: convergent evolution,evolution,genomics,molecular evolution,phylogenetics,probabilistic models}, number = {1777}, publisher = {Royal Society Publishing}, title = {{Detecting adaptive convergent amino acid evolution}}, url = {https://royalsocietypublishing.org/doi/abs/10.1098/rstb.2018.0234}, volume = {374}, year = {2019} } @misc{Lima2019, abstract = {Motivation: Nanopore long-read sequencing technology offers promising alternatives to high-throughput short read sequencing, especially in the context of RNA-sequencing. However this technology is currently hindered by high error rates in the output data that affect analyses such as the identification of isoforms, exon boundaries, open reading frames and creation of gene catalogues. Due to the novelty of such data, computational methods are still actively being developed and options for the error correction of Nanopore RNA-sequencing long reads remain limited. Results: In this article, we evaluate the extent to which existing long-read DNA error correction methods are capable of correcting cDNA Nanopore reads. We provide an automatic and extensive benchmark tool that not only reports classical error correction metrics but also the effect of correction on gene families, isoform diversity, bias toward the major isoform and splice site detection. We find that long read error correction tools that were originally developed for DNA are also suitable for the correction of Nanopore RNA-sequencing data, especially in terms of increasing base pair accuracy. Yet investigators should be warned that the correction process perturbs gene family sizes and isoform diversity. This work provides guidelines on which (or whether) error correction tools should be used, depending on the application type. Benchmarking software: https://gitlab.com/leoisl/ LR{\_}EC{\_}analyser.}, author = {Lima, Leandro and Marchet, Camille and Caboche, S{\'{e}}gol{\`{e}}ne and da Silva, Corinne and Istace, Benjamin and Aury, Jean Marc and Touzet, H{\'{e}}l{\`{e}}ne and Chikhi, Rayan}, booktitle = {Briefings in Bioinformatics}, doi = {10.1093/bib/bbz058}, file = {:Users/navratil/Documents/Mendeley Desktop/Unknown/Lima et al/academic.oup.com/academic.oup.com{\_}Lima et al.{\_}Comparative assessment of long-read error correction software applied to Nanopore RNA-sequencing data{\_}Unkno.pdf:pdf}, issn = {14774054}, keywords = {Benchmark,Error correction,Long reads,Nanopore,RNA-sequencing}, number = {4}, pages = {1164--1181}, pmid = {31232449}, title = {{Comparative assessment of long-read error correction software applied to Nanopore RNA-sequencing data}}, url = {https://academic.oup.com/bib/article-abstract/21/4/1164/5512144}, volume = {21}, year = {2019} } @article{Bernard2019, author = {Bernard, Claude}, file = {:Users/navratil/Documents/Mendeley Desktop/2019/Bernard/Unknown/Unknown{\_}Bernard{\_}De novo algorithms to identify patterns associated with biological events in de Bruijn graphs built from NGS data{\_}2019.pdf:pdf}, title = {{De novo algorithms to identify patterns associated with biological events in de Bruijn graphs built from NGS data}}, url = {https://tel.archives-ouvertes.fr/tel-02280110/}, year = {2019} } @inproceedings{Gastaldello2019, abstract = {Phylogenetic tree reconciliation is the approach commonly used to investigate the coevolution of sets of organisms such as hosts and symbionts. Given a phylogenetic tree for each such set, respectively denoted by H and S, together with a mapping $\phi$ of the leaves of S to the leaves of H, a reconciliation is a mapping ϱ of the internal vertices of S to the vertices of H which extends $\phi$ with some constraints. Given a cost for each reconciliation, a huge number of most parsimonious ones are possible, even exponential in the dimension of the trees. Without further information, any biological interpretation of the underlying coevolution would require that all optimal solutions are enumerated and examined. The latter is however impossible without providing some sort of high level view of the situation. One approach would be to extract a small number of representatives, based on some notion of similarity or of equivalence between the reconciliations. In this paper, we define two equivalence relations that allow one to identify many reconciliations with a single one, thereby reducing their number. Extensive experiments indicate that the number of output solutions greatly decreases in general. By how much clearly depends on the constraints that are given as input.}, author = {Gastaldello, Mattia and Calamoneri, Tiziana and Sagot, Marie France}, booktitle = {Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)}, doi = {10.1007/978-3-030-14160-8_2}, isbn = {9783030141592}, issn = {16113349}, keywords = {Cophylogeny,Equivalence relation,Reconciliations}, pages = {9--18}, publisher = {Springer Verlag}, title = {{Extracting few representative reconciliations with host switches}}, volume = {10834 LNBI}, year = {2019} } @article{Massip2019, abstract = {The replication program of vertebrate genomes is driven by the chromosomal distribution and timing of activation of tens of thousands of replication origins. Genome-wide studies have shown the association of origins with promoters and CpG islands, and their enrichment in G-quadruplex motifs (G4). However, the genetic determinants driving their activity remain poorly understood. To gain insight on the constraints operating on origins, we conducted the first evolutionary comparison of origins across vertebrates. We generated a genome-wide map of chicken origins (the first of a bird genome), and performed a comparison with human and mouse maps. The analysis of intra-species polymorphism revealed a strong depletion of genetic diversity at the core of replication initiation loci. This depletion is not linked to the presence of G4 motifs, promoters or CpG islands. In contrast, we show that origins experienced a rapid turnover during vertebrate evolution, since pairwise comparisons of origin maps revealed that {\textless}24{\%} of them are conserved among vertebrates. This study unravels the existence of a novel determinant of origins, the precise functional role of which remains to be determined. Despite the importance of replication initiation for the fitness of organisms, the distribution of origins along vertebrate chromosomes is highly flexible.}, author = {Massip, Florian and Laurent, Marc and Brossas, Caroline and Fern{\'{a}}ndez-Justel, Jos{\'{e}} Miguel and G{\'{o}}mez, Mar{\'{i}}a and Prioleau, Marie Noelle and Duret, Laurent and Picard, Franck}, doi = {10.1093/nar/gkz182}, issn = {13624962}, journal = {Nucleic Acids Research}, number = {10}, pages = {5114--5125}, pmid = {30916335}, title = {{Evolution of replication origins in vertebrate genomes: Rapid turnover despite selective constraints}}, url = {https://academic.oup.com/nar/article-abstract/47/10/5114/5420529}, volume = {47}, year = {2019} } @article{Duprey2019, author = {Duprey, Alexandre and Ta{\"{i}}b, Najwa and Leonard, Simon and Garin, Tiffany and Flandrois, Jean-Pierre and Nasser, William and Brochier-Armanet, C{\'{e}}line and Reverchon, Sylvie}, doi = {10.1111/1462-2920.14627ï}, issn = {2809-2835}, journal = {Environmental Microbiology, Society for Applied Microbiology and Wiley-Blackwell}, number = {8}, title = {{The phytopathogenic nature of Dickeya aquatica 174/2 and the dynamic early evolution of Dickeya pathogenicity The phy-topathogenic nature of Dickeya aquatica 174/2 and the dynamic early evolution of Dickeya pathogenic-ity}}, url = {https://hal.archives-ouvertes.fr/hal-02099020}, volume = {21}, year = {2019} } @article{Kandiah2019, abstract = {Kandiah et al. solve the structure of the lysine decarboxylase LdcA from a human pathogen Pseudomonas aeruginosa by cryo-EM. They use evolutionary information to analyze the system, demonstrate involvement of LdcA in full virulence of the pathogen in vivo, and propose to target this protein for therapeutic interventions.}, author = {Kandiah, Eaazhisai and Carriel, Diego and Garcia, Pierre Simon and Felix, Jan and Banzhaf, Manuel and Kritikos, George and Bacia-Verloop, Maria and Brochier-Armanet, C{\'{e}}line and Elsen, Sylvie and Gutsche, Irina}, doi = {10.1016/j.str.2019.10.003}, issn = {18784186}, journal = {Structure}, keywords = {LdcA,Pseudomonas aeruginosa,amino acid decarboxylases,bacteria,cryo-EM structure,defense island,evolution,phylogenetic analysis,ppGpp,virulence}, number = {12}, pages = {1842--1854.e4}, pmid = {31653338}, title = {{Structure, Function, and Evolution of the Pseudomonas aeruginosa Lysine Decarboxylase LdcA}}, url = {https://www.sciencedirect.com/science/article/pii/S0969212619303442}, volume = {27}, year = {2019} } @article{Lannes2019, abstract = {Epigenetic modifications have an important role to explain part of the intra-and inter-species variation in gene expression. They also have a role in the control of transposable elements (TEs) whose activity may have a significant impact on genome evolution by promoting various mutations, which are expected to be mostly deleterious. A change in the local epigenetic landscape associated with the presence of TEs is expected to affect the expression of neighboring genes since these modifications occurring at TE sequences can spread to neighboring sequences. In this work, we have studied how the epigenetic modifications of genes are conserved and what the role of TEs is in this conservation. For that, we have compared the conservation of the epigenome associated with human duplicated genes and the differential presence of TEs near these genes. Our results show higher epigenome conservation of duplicated genes from the same family when they share similar TE environment, suggesting a role for the differential presence of TEs in the evolutionary divergence of duplicates through variation in the epigenetic landscape.}, author = {Lannes, Romain and Rizzon, Car{\`{e}}ne and Lerat, Emmanuelle}, doi = {10.3390/genes10030249}, journal = {mdpi.com}, keywords = {epigenetics,gene duplication,gene evolution,transposable elements}, title = {{Does the Presence of Transposable Elements Impact the Epigenetic Environment of Human Duplicated Genes?}}, url = {www.mdpi.com/journal/genes}, year = {2019} } @article{Fablet2019, abstract = {All genomes contain repeated sequences that are known as transposable elements (TEs). Among these are endogenous retroviruses (ERVs), which are sequences similar to retroviruses and are transmitted across generations from parent to progeny. These sequences are controlled in genomes through epigenetic mechanisms. At the center of the epigenetic control of TEs are small interfering RNAs of the piRNA class, which trigger heterochromatinization of TE sequences. The tirant ERV of Drosophila simulans displays intra-specific variability in copy numbers, insertion sites, and transcription levels, providing us with a well-suited model to study the dynamic relationship between a TE family and the host genome through epigenetic mechanisms. We show that tirant transcript amounts and piRNA amounts are positively correlated in ovaries in normal conditions, unlike what was previously described following divergent crosses. In addition, we describe tirant insertion polymorphism in the genomes of three D. simulans wild-type strains, which reveals a limited number of insertions that may be associated with gene transcript level changes through heterochromatin spreading and have phenotypic impacts. Taken together, our results participate in the understanding of the equilibrium between the host genome and its TEs.}, author = {Fablet, Marie and Jacquet, Angelo and Rebollo, Rita and Haudry, Annabelle and Rey, Carine and Salces-Ortiz, Judit and Bajad, Prajakta and Burlet, Nelly and Jantsch, Michael F. and Guerreiro, Maria Pilar Garc{\'{i}}a and Vieira, Cristina}, doi = {10.1534/g3.118.200789}, issn = {21601836}, journal = {G3: Genes, Genomes, Genetics}, keywords = {Chromatin,Drosophila,Epigenetic control,PiRNA,Retrotransposon,Transposable element}, number = {3}, pages = {855--865}, pmid = {30658967}, title = {{Dynamic interactions between the genome and an endogenous retrovirus: Tirant in Drosophila simulans wild-type strains}}, url = {https://academic.oup.com/g3journal/article-abstract/9/3/855/6026689}, volume = {9}, year = {2019} } @article{Tambones2019, abstract = {Background: The use of large-scale genomic analyses has resulted in an improvement of transposable element sampling and a significant increase in the number of reported HTT (horizontal transfer of transposable elements) events by expanding the sampling of transposable element sequences in general and of specific families of these elements in particular, which were previously poorly sampled. In this study, we investigated the occurrence of HTT events in a group of elements that, until recently, were uncommon among the HTT records in Drosophila - the Jockey elements, members of the LINE (long interspersed nuclear element) order of non-LTR (long terminal repeat) retrotransposons. The sequences of 111 Jockey families deposited in Repbase that met the criteria of the analysis were used to identify Jockey sequences in 48 genomes of Drosophilidae (genus Drosophila, subgenus Sophophora: melanogaster, obscura and willistoni groups; subgenus Drosophila: immigrans, melanica, repleta, robusta, virilis and grimshawi groups; subgenus Dorsilopha: busckii group; genus/subgenus Zaprionus and genus Scaptodrosophila). Results: Phylogenetic analyses revealed 72 Jockey families in 41 genomes. Combined analyses revealed 15 potential HTT events between species belonging to different genera and species groups of Drosophilidae, providing evidence for the flow of genetic material favoured by the spatio-temporal sharing of these species present in the Palaeartic or Afrotropical region. Conclusions: Our results provide phylogenetic, biogeographic and temporal evidence of horizontal transfers of the Jockey elements, increase the number of rare records of HTT in specific families of LINE elements, increase the number of known occurrences of these events, and enable a broad understanding of the evolutionary dynamics of these elements and the host species.}, author = {Tambones, Izabella L. and Haudry, Annabelle and Sim{\~{a}}o, Maryanna C. and Carareto, Claudia M.A.}, doi = {10.1186/s13100-019-0184-1}, file = {:Users/navratil/Documents/Mendeley Desktop/2019/Tambones et al/Mobile DNA/Mobile DNA{\_}Tambones et al.{\_}High frequency of horizontal transfer in Jockey families (LINE order) of drosophilids{\_}2019.pdf:pdf}, issn = {17598753}, journal = {Mobile DNA}, keywords = {Drosophila,HTT,Scaptodrosophila,VHICA,Zaprionus,transposable elements}, month = {nov}, number = {1}, publisher = {BioMed Central Ltd.}, title = {{High frequency of horizontal transfer in Jockey families (LINE order) of drosophilids}}, volume = {10}, year = {2019} } @article{Acuna2019, abstract = {Bubbles are pairs of internally vertex-disjoint (s, t)-paths in a directed graph, which have many applications in the processing of DNA and RNA data. Listing and analysing all bubbles in a given graph is usually unfeasible in practice, due to the exponential number of bubbles present in real data graphs. In this paper, we propose a notion of bubble generator set, i.e., a polynomial-sized subset of bubbles from which all the other bubbles can be obtained through a suitable application of a specific symmetric difference operator. This set provides a compact representation of the bubble space of a graph. A bubble generator can be useful in practice, since some pertinent information about all the bubbles can be more conveniently extracted from this compact set. We provide a polynomial-time algorithm to decompose any bubble of a graph into the bubbles of such a generator in a tree-like fashion. Finally, we present two applications of the bubble generator on a real RNA-seq dataset.}, author = {Acu{\~{n}}a, V. and Grossi, R. and Italiano, G. F. and Lima, L. and Rizzi, R. and Sacomoto, G. and Sagot, M. F. and Sinaimeri, B.}, doi = {10.1007/s00453-019-00619-z}, issn = {14320541}, journal = {Algorithmica}, keywords = {Bubble generator set,Bubbles,Decomposition algorithm}, publisher = {Springer New York LLC}, title = {{On Bubble Generators in Directed Graphs}}, year = {2019} } @article{Ashraf2019, abstract = {Alteration of host cell splicing is a common feature of many viral infections which is underappreciated because of the complexity and technical difficulty of studying alternative splicing (AS) regulation. Recent advances in RNA sequencing technologies revealed that up to several hundreds of host genes can show altered mRNA splicing upon viral infection. The observed changes in AS events can be either a direct consequence of viral manipulation of the host splicing machinery or result indirectly from the virus-induced innate immune response or cellular damage. Analysis at a higher resolution with single-cell RNAseq, and at a higher scale with the integration of multiple omics data sets in a systems biology perspective, will be needed to further comprehend this complex facet of virus–host interactions.}, author = {Ashraf, Usama and Benoit-Pilven, Clara and Lacroix, Vincent and Navratil, Vincent and Naffakh, Nadia}, doi = {10.1016/j.tim.2018.11.004}, issn = {18784380}, journal = {Trends in Microbiology}, keywords = {alternative splicing,genome-wide transcriptomics,systems biology,virus–host interaction}, month = {mar}, number = {3}, pages = {268--281}, pmid = {30577974}, publisher = {Elsevier Ltd}, title = {{Advances in Analyzing Virus-Induced Alterations of Host Cell Splicing}}, volume = {27}, year = {2019} } @incollection{Aouacheria2019, abstract = {BCL-2 proteins correspond to a structurally, functionally, and phylogenetically heterogeneous group of regulators that play crucial roles in the life and death of animal cells. Some of these regulators also represent therapeutic targets in human diseases including cancer. In the omics era, there is great need for easy data retrieval and fast analysis of the molecular players involved in cell death. In this chapter, we present generic and specific computational resources (such as the reference database BCL2DB) as well as bioinformatics tools that can be used to investigate BCL-2 homologs and BH3-only proteins.}, author = {Aouacheria, Abdel and Navratil, Vincent and Combet, Christophe}, booktitle = {Methods in Molecular Biology}, doi = {10.1007/978-1-4939-8861-7_2}, issn = {10643745}, keywords = {Apoptosis,BCL-2,BH3,Bioinformatics,Cell death,Databases,Omics,Protein domains,Protein motifs,Structure–function relationships}, pages = {23--43}, pmid = {30535996}, publisher = {Humana Press Inc.}, title = {{Database and Bioinformatic Analysis of BCL-2 Family Proteins and BH3-Only Proteins}}, volume = {1877}, year = {2019} } @article{Bauman2018, abstract = {Eigenvector-mapping methods such as Moran's eigenvector maps (MEM) are derived from a spatial weighting matrix (SWM) that describes the relations among a set of sampled sites. The specification of the SWM is a crucial step, but the SWM is generally chosen arbitrarily, regardless of the sampling design characteristics. Here, we compare the statistical performances of different types of SWMs (distance-based or graph-based) in contrasted realistic simulation scenarios. Then, we present an optimization method and evaluate its performances compared to the arbitrary choice of the most-widely used distance-based SWM. Results showed that the distance-based SWMs generally had lower power and accuracy than other specifications, and strongly underestimated spatial signals. The optimization method, using a correction procedure for multiple tests, had a correct type I error rate, and had higher power and accuracy than an arbitrary choice of the SWM. Nevertheless, the power decreased when too many SWMs were compared, resulting in a trade-off between the gain of accuracy and the loss of power. We advocate that future studies should optimize the choice of the SWM using a small set of appropriate candidates. R functions to implement the optimization are available in the adespatial package and are detailed in a tutorial.}, author = {Bauman, David and Drouet, Thomas and Fortin, Marie Jos{\'{e}}e and Dray, St{\'{e}}phane}, doi = {10.1002/ecy.2469}, issn = {00129658}, journal = {Ecology}, keywords = {Moran's eigenvector maps (MEM),community ecology,community simulation,connection scheme,inference of ecological processes from spatial patterns,multiscale spatial patterns,optimization,principal coordinates of neighbor matrices (PCNM),spatial autocorrelation,spatial eigenvector mapping (SEVM),spatial weighting matrix,type I error rate inflation}, month = {oct}, number = {10}, pages = {2159--2166}, pmid = {30039615}, publisher = {Ecological Society of America}, title = {{Optimizing the choice of a spatial weighting matrix in eigenvector-based methods}}, volume = {99}, year = {2018} } @article{Cariou2018, abstract = {Objective: Targeted sequencing of 16S rDNA amplicons is routinely used for microbial community profiling but this method suffers several limitations such as bias affinity of universal primers and short read size. Gene capture by hybridization represents a promising alternative. Here we used a metagenomic extract from the pea aphid Acyrthosiphon pisum to compare the performances of two widely used PCR primer pairs with DNA capture, based on solution hybrid selection. Results: All methods produced an exhaustive description of the 8 bacterial taxa known to be present in this sample. In addition, the methods yielded similar quantitative results, with the number of reads strongly correlating with quantitative PCR controls. Both methods can thus be considered as qualitatively and quantitatively robust on such a sample with low microbial complexity.}, author = {Cariou, Marie and Ribi{\`{e}}re, C{\'{e}}line and Morli{\`{e}}re, St{\'{e}}phanie and Gauthier, Jean Pierre and Simon, Jean Christophe and Peyret, Pierre and Charlat, Sylvain}, doi = {10.1186/s13104-018-3559-3}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Cariou et al/BMC Research Notes/BMC Research Notes{\_}Cariou et al.{\_}Comparing 16S rDNA amplicon sequencing and hybridization capture for pea aphid microbiota diversity ana.pdf:pdf}, issn = {17560500}, journal = {BMC Research Notes}, keywords = {16S,Amplicon sequencing,Hybridization capture,Microbiota,Pea aphid}, month = {jul}, number = {1}, pmid = {29996907}, publisher = {BioMed Central Ltd.}, title = {{Comparing 16S rDNA amplicon sequencing and hybridization capture for pea aphid microbiota diversity analysis}}, volume = {11}, year = {2018} } @article{Clappe2018, abstract = {The methods of direct gradient analysis and variation partitioning are the most widely used frameworks to evaluate the contributions of species sorting to metacommunity structure. In many cases, however, species are also driven by spatial processes that are independent of environmental heterogeneity (e.g., neutral dynamics). As such, spatial autocorrelation can occur independently in both species (due to limited dispersal) and the environmental data, leading to spurious correlations between species distributions and the spatialized (i.e., spatially autocorrelated) environment. In these cases, the method of variation partitioning may present high Type I error rates (i.e., reject the null hypothesis more often than the pre-established critical level) and inflated estimates regarding the environmental component that is used to estimate the importance of species sorting. In this paper, we (1) demonstrate that metacommunities driven by neutral dynamics (via limited dispersal) alone or in combination with species sorting leads to inflated estimates and Type I error rates when testing for the importance of species sorting; and (2) propose a general and flexible new variation partitioning procedure to adjust for spurious contributions due to spatial autocorrelation from the environmental fraction. We used simulated metacommunity data driven by pure neutral, pure species sorting, and mixed (i.e., neutral + species sorting dynamics) processes to evaluate the performances of our new methodological framework. We also demonstrate the utility of the proposed framework with an empirical plant dataset in which we show that half of the variation initially due to the environment by the standard variation partitioning framework was due to spurious correlations.}, author = {Clappe, Sylvie and Dray, St{\'{e}}phane and Peres-Neto, Pedro R.}, doi = {10.1002/ecy.2376}, issn = {00129658}, journal = {Ecology}, keywords = {Moran spectral randomization,direct gradient analysis,environmental effect,limited dispersal,metacommunity ecology,neutral dynamics,spatial autocorrelation,spatially constrained null model,variation partitioning}, month = {aug}, number = {8}, pages = {1737--1747}, pmid = {29723919}, publisher = {Ecological Society of America}, title = {{Beyond neutrality: disentangling the effects of species sorting and spurious correlations in community analysis}}, volume = {99}, year = {2018} } @article{Beugin2018, abstract = {The investigation of genetic clusters in natural populations is an ubiquitous problem in a range of fields relying on the analysis of genetic data, such as molecular ecology, conservation biology and microbiology. Typically, genetic clusters are defined as distinct panmictic populations, or parental groups in the context of hybridisation. Two types of methods have been developed for identifying such clusters: model-based methods, which are usually computer-intensive but yield results which can be interpreted in the light of an explicit population genetic model, and geometric approaches, which are less interpretable but remarkably faster. Here, we introduce snapclust, a fast maximum-likelihood solution to the genetic clustering problem, which allies the advantages of both model-based and geometric approaches. Our method relies on maximising the likelihood of a fixed number of panmictic populations, using a combination of geometric approach and fast likelihood optimisation, using the Expectation-Maximisation (EM) algorithm. It can be used for assigning genotypes to populations and optionally identify various types of hybrids between two parental populations. Several goodness-of-fit statistics can also be used to guide the choice of the retained number of clusters. Using extensive simulations, we show that snapclust performs comparably to current gold standards for genetic clustering as well as hybrid detection, with some advantages for identifying hybrids after several backcrosses, while being orders of magnitude faster than other model-based methods. We also illustrate how snapclust can be used for identifying the optimal number of clusters, and subsequently assign individuals to various hybrid classes simulated from an empirical microsatellite dataset. snapclust is implemented in the package adegenet for the free software R, and is therefore easily integrated into existing pipelines for genetic data analysis. It can be applied to any kind of co-dominant markers, and can easily be extended to more complex models including, for instance, varying ploidy levels. Given its flexibility and computer-efficiency, it provides a useful complement to the existing toolbox for the study of genetic diversity in natural populations.}, author = {Beugin, Marie Pauline and Gayet, Thibault and Pontier, Dominique and Devillard, S{\'{e}}bastien and Jombart, Thibaut}, doi = {10.1111/2041-210X.12968}, issn = {2041210X}, journal = {Methods in Ecology and Evolution}, keywords = {EM algorithm,SNP,genetic assignment,genetic clustering,hybridisation,microsatellites,population membership,relative performances}, month = {apr}, number = {4}, pages = {1006--1016}, publisher = {British Ecological Society}, title = {{A fast likelihood solution to the genetic clustering problem}}, volume = {9}, year = {2018} } @article{Baudrot2018, abstract = {Mechanistic modeling approaches, such as the toxicokinetic-toxicodynamic (TKTD) framework, are promoted by international institutions such as the European Food Safety Authority and the Organization for Economic Cooperation and Development to assess the environmental risk of chemical products generated by human activities. TKTD models can encompass a large set of mechanisms describing the kinetics of compounds inside organisms (e.g., uptake and elimination) and their effect at the level of individuals (e.g., damage accrual, recovery, and death mechanism). Compared to classical dose–response models, TKTD approaches have many advantages, including accounting for temporal aspects of exposure and toxicity, considering data points all along the experiment and not only at the end, and making predictions for untested situations as realistic exposure scenarios. Among TKTD models, the general unified threshold model of survival (GUTS) is within the most recent and innovative framework but is still underused in practice, especially by risk assessors, because specialist programming and statistical skills are necessary to run it. Making GUTS models easier to use through a new module freely available from the web platform MOSAIC (standing for MOdeling and StAtistical tools for ecotoxIClogy) should promote GUTS operability in support of the daily work of environmental risk assessors. This paper presents the main features of MOSAIC{\_}GUTS: uploading of the experimental data, GUTS fitting analysis, and LCx estimates with their uncertainty. These features will be exemplified from literature data. Integr Environ Assess Manag 2018;14:625–630. {\textcopyright} 2018 SETAC.}, author = {Baudrot, Virgile and Veber, Philippe and Gence, Guillaume and Charles, Sandrine}, doi = {10.1002/ieam.4061}, issn = {15513793}, journal = {Integrated Environmental Assessment and Management}, keywords = {Bayesian inference,LCx estimates,Survival,Toxicokinetics-toxicodynamics,Web interface}, number = {5}, pages = {625--630}, pmid = {29781233}, title = {{Fit Reduced GUTS Models Online: From Theory to Practice}}, url = {https://setac.onlinelibrary.wiley.com/doi/abs/10.1002/ieam.4061}, volume = {14}, year = {2018} } @article{Mercier2018, abstract = {Controlling the technological variability on an analytical chain is critical for biomarker discovery. The sources of technological variability should be modeled, which calls for specific experimental design, signal processing, and statistical analysis. Furthermore, with unbalanced data, the various components of variability cannot be estimated with the sequential or adjusted sums of squares of usual software programs. We propose a novel approach to variance component analysis with application to the matrix-assisted laser desorption/ionization time-of-flight (MALDI-TOF) technology and use this approach for protein quantification by a classical signal processing algorithm and two more recent ones (BHI-PRO 1 and 2). Given the high technological variability, the quantification failed to restitute the known quantities of five out of nine proteins present in a controlled solution. There was a linear relationship between protein quantities and peak intensities for four out of nine peaks with all algorithms. The biological component of the variance was higher with BHI-PRO than with the classical algorithm (80–95{\%} with BHI-PRO 1, 79–95{\%} with BHI-PRO 2 vs. 56–90{\%}); thus, BHI-PRO were more efficient in protein quantification. The technological component of the variance was higher with the classical algorithm than with BHI-PRO (6–25{\%} vs. 2.5–9.6{\%} with BHI-PRO 1 and 3.5–11.9{\%} with BHI-PRO 2). The chemical component was also higher with the classical algorithm (3.6–18.7{\%} vs. {\textless} 3.5{\%}). Thus, BHI-PRO were better in removing noise from signal when the expected peaks are detected. Overall, either BHI-PRO algorithm may reduce the technological variance from 25 to 10{\%} and thus improve protein quantification and biomarker validation.}, author = {Mercier, Catherine and Klich, Amna and Truntzer, Caroline and Picaud, Vincent and Giovannelli, Jean Fran{\c{c}}ois and Ducoroy, Patrick and Grangeat, Pierre and Maucort-Boulch, Delphine and Roy, Pascal}, doi = {10.1002/bimj.201600198}, issn = {15214036}, journal = {Biometrical Journal}, keywords = {biomarker discovery,experimental design,sum of squares type,technological variability,variance components}, number = {2}, pages = {262--274}, pmid = {29230881}, title = {{Variance component analysis to assess protein quantification in biomarker discovery. Application to MALDI-TOF mass spectrometry}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/bimj.201600198}, volume = {60}, year = {2018} } @article{Rey2018, abstract = {In the history of life, some phenotypes have been acquired several times independently, through convergent evolution. Recently, lots of genome-scale studies have been devoted to identify nucleotides or amino acids that changed in a convergent manner when the convergent phenotypes evolved. These efforts have had mixed results, probably because of differences in the detection methods, and because of conceptual differences about the definition of a convergent substitution. Some methods contend that substitutions are convergent only if they occur on all branches where the phenotype changed toward the exact same state at a given nucleotide or amino acid position. Others are much looser in their requirements and define a convergent substitution as one that leads the site at which they occur to prefer a phylogeny in which species with the convergent phenotype group together. Here, we suggest to look for convergent shifts in amino acid preferences instead of convergent substitutions to the exact same amino acid. We define as convergent shifts substitutions that occur on all branches where the phenotype changed and such that they correspond to a change in the type of amino acid preferred at this position. We implement the corresponding model into a method named PCOC. We show on simulations that PCOC better recovers convergent shifts than existing methods in terms of sensitivity and specificity. We test it on a plant protein alignment where convergent evolution has been studied in detail and find that our method recovers several previously identified convergent substitutions and proposes credible new candidates.}, author = {Rey, Carine and Gu{\'{e}}guen, Laurent and S{\'{e}}mon, Marie and Boussau, Bastien}, doi = {10.1093/molbev/msy114}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Bioinformatics,C4 metabolism,Convergent evolution,Echolocation,Genomics,Sequence evolution}, number = {9}, pages = {2296--2306}, pmid = {29986048}, title = {{Accurate detection of convergent amino-acid evolution with PCOC}}, url = {https://academic.oup.com/mbe/article/35/9/2296/5050468}, volume = {35}, year = {2018} } @article{Moros-Nicolas2018, abstract = {The zona pellucida (ZP) is an extracellular matrix that surrounds mammalian oocytes. In eutherians it is formed from three or four proteins (ZP1, ZP2, ZP3, ZP4). In the few marsupials that have been studied, however, only three of these have been characterised (ZP2, ZP3, ZP4). Nevertheless, the composition in marsupials may be more complex, since a duplication of the ZP3 gene was recently described in one species. The aim of this work was to elucidate the ZP composition in marsupials and relate it to the evolution of the ZP gene family. For that, an in silico and molecular analysis was undertaken, focusing on two South American species (gray short-tailed opossum and common opossum) and five Australian species (brushtail possum, koala, Bennett's wallaby, Tammar wallaby and Tasmanian devil). This analysis identified the presence of ZP1 mRNA and mRNA from two or three paralogues of ZP3 in marsupials. Furthermore, evidence for ZP1 and ZP4 pseudogenes in the South American subfamily Didelphinae and for ZP3 pseudogenes in two marsupials is provided. In conclusion, two different composition models are proposed for marsupials: a model with four proteins (ZP1, ZP2 and ZP3 (two copies)) for the South American species and a model with six proteins (ZP1, ZP2, ZP3 (three copies) and ZP4) for the Australasian species.}, author = {Moros-Nicol{\'{a}}s, Carla and Chevret, Pascale and Izquierdo-Rico, Mar{\'{i}}a Jos{\'{e}} and Holt, William V. and Esteban-D{\'{i}}az, Daniela and L{\'{o}}pez-B{\'{e}}jar, Manel and Mart{\'{i}}nez-Nevado, Eva and Nilsson, Maria A. and Ballesta, Jos{\'{e}} and Avil{\'{e}}s, Manuel}, doi = {10.1071/RD16519}, issn = {14485990}, journal = {Reproduction, Fertility and Development}, keywords = {evolution,fertilisation,oocyte,sperm-egg interaction}, number = {5}, pages = {721--733}, pmid = {29162213}, title = {{Composition of marsupial zona pellucida: A molecular and phylogenetic approach}}, url = {https://www.publish.csiro.au/rd/rd16519}, volume = {30}, year = {2018} } @article{Gueguen2018, abstract = {The measurement of synonymous and nonsynonymous substitution rates (dS and dN) is useful for assessing selection operating on protein sequences or for investigating mutational processes affecting genomes. In particular, the ratio ddNS is expected to be a good proxy for x, the ratio of fixation probabilities of nonsynonymous mutations relative to that of neutral mutations. Standard methods for estimating dN, dS, or x rely on the assumption that the base composition of sequences is at the equilibrium of the evolutionary process. In many clades, this assumption of stationarity is in fact incorrect, and we show here through simulations and analyses of empirical data that nonstationarity biases the estimate of dN, dS, and x. We show that the bias in the estimate of x can be fixed by explicitly taking into consideration nonstationarity in the modeling of codon evolution, in a maximum likelihood framework. Moreover, we propose an exact method for estimating dN and dS on branches, based on stochastic mapping, that can take into account nonstationarity. This method can be directly applied to any kind of codon evolution model, as long as neutrality is clearly parameterized.}, author = {Gu{\'{e}}guen, Laurent and Duret, Laurent}, doi = {10.1093/molbev/msx308}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Nonsynonymous substitutions,Selection,Stochastic mapping.,Synonymous substitutions}, number = {3}, pages = {734--742}, pmid = {29220511}, title = {{Unbiased estimate of synonymous and nonsynonymous substitution rates with nonstationary base composition}}, url = {https://academic.oup.com/mbe/article-abstract/35/3/734/4705835}, volume = {35}, year = {2018} } @article{Beugin2018a, author = {Beugin, Marie-Pauline}, journal = {Ecology, environment. Université de Lyon}, title = {{The European wildcat as a model for the study of wildlife : focus on hybridization and the circulation of viruses}}, url = {https://tel.archives-ouvertes.fr/tel-01807665/}, year = {2018} } @article{Fruchard2018, author = {Fruchard, C}, title = {{A study of sex chromosomes and sex determination in plants: Silene and Coccinia systems comparison}}, url = {https://tel.archives-ouvertes.fr/tel-01874803/}, year = {2018} } @article{Gayet2018, abstract = {The wild boar (Sus scrofa scrofa) is a peculiar species. It is an appreciated game species for hunters, a nightmare for farmers and a subject of debate for the society in general. The tenfold increase of the population over the last decades in France and all over Europe, despite increased hunting pressure, generated great human-wildlife conflict. The wild boar is responsible for great economic losses due to vehicle collision, diseases transmission and damaged crops and ecosystems. Improving management strategies becomes a prime interest to avoid such conflicts, or at least keep them under control. Obtaining information on the species is a first step toward good management strategies. The objective of my work is, in a first part, to characterize the mating system of the wild boar and to identify some parameters, especially hunting, influencing the reproductive processes. The second part focus on the investigation of the influence of the mating system on wild boar life history traits. My researches are based on the study of several populations contrasting in their hunting practices and on longitudinal data of a highly monitored population. The study is based on data collected on wild boars killed by hunting. Genotypes were obtained for pregnant females and their litter and paternity analyses were realized to measure the number of fathers in a litter and estimate multiple paternity rates (proportion of litter sired by more than one father). I was able to show that the mating system is mainly promiscuous (several males mate with several females) contrasting with the polygyny (a dominant male monopolizing a group of females) usually described in this species. Moreover, reproductive processes, estimated by the number of mates of a female and the multiple paternity rates, are influenced by hunting variations in a population. I also showed that number of fathers has positive effect on female fecundity. High rates of multiple paternity together with high genetic diversity were found in a heavily hunted population, suggesting multiple paternity may buffer yearly bottlenecks. However, the increase of number of fathers is not associated with increase of within-litter variation}, author = {Gayet, T}, title = {{Modification of the structure of wild boar populations by hunting and influence on reproductive processes}}, url = {https://tel.archives-ouvertes.fr/tel-02314838/}, year = {2018} } @article{Roussel2018, abstract = {Background: Evaluating the factors favoring the onset of influenza epidemics is a critical public health issue for surveillance, prevention and control. While past outbreaks provide important insights for understanding epidemic onsets, their statistical analysis is challenging since the impact of a factor can be viewed at different scales. Indeed, the same factor can explain why epidemics are more likely to begin (i) during particular weeks of the year (global scale); (ii) earlier in particular regions (spatial scale) or years (annual scale) than others and (iii) earlier in some years than others within a region (spatiotemporal scale). Methods: Here, we present a statistical approach based on dynamical modeling of infectious diseases to study epidemic onsets. We propose a method to disentangle the role of covariates at different scales and use a permutation procedure to assess their significance. Epidemic data gathered from 18 French regions over six epidemic years were provided by the Regional Influenza Surveillance Group (GROG) sentinel network. Results: Our results failed to highlight a significant impact of mobility flows on epidemic onset dates. Absolute humidity had a significant impact, but only at the spatial scale. No link between demographic covariates and influenza epidemic onset dates could be established. Discussion: Dynamical modeling presents an interesting basis to analyze spatiotemporal variations in the outcome of epidemic onsets and how they are related to various types of covariates. The use of these models is quite complex however, due to their mathematical complexity. Furthermore, because they attempt to integrate migration processes of the virus, such models have to be much more explicit than pure statistical approaches. We discuss the relation of this approach to survival analysis, which present significant differences but may constitute an interesting alternative for non-methodologists.}, author = {Roussel, Marion and Pontier, Dominique and Cohen, Jean Marie and Lina, Bruno and Fouchet, David}, doi = {10.7717/peerj.4440}, issn = {21678359}, journal = {PeerJ}, keywords = {Climate,Mobility flows,Permutation tests,Population size,Proportion of children}, number = {3}, title = {{Linking influenza epidemic onsets to covariates at different scales using a dynamical model}}, url = {https://peerj.com/articles/4440/}, volume = {2018}, year = {2018} } @article{Klich2018, abstract = {Background: In the field of biomarker validation with mass spectrometry, controlling the technical variability is a critical issue. In selected reaction monitoring (SRM) measurements, this issue provides the opportunity of using variance component analysis to distinguish various sources of variability. However, in case of unbalanced data (unequal number of observations in all factor combinations), the classical methods cannot correctly estimate the various sources of variability, particularly in presence of interaction. The present paper proposes an extension of the variance component analysis to estimate the various components of the variance, including an interaction component in case of unbalanced data. Results: We applied an experimental design that uses a serial dilution to generate known relative protein concentrations and estimated these concentrations by two processing algorithms, a classical and a more recent one. The extended method allowed estimating the variances explained by the dilution and the technical process by each algorithm in an experiment with 9 proteins: L-FABP, 14.3.3 sigma, Calgi, Def.A6, Villin, Calmo, I-FABP, Peroxi-5, and S100A14. Whereas, the recent algorithm gave a higher dilution variance and a lower technical variance than the classical one in two proteins with three peptides (L-FABP and Villin), there were no significant difference between the two algorithms on all proteins. Conclusions: The extension of the variance component analysis was able to estimate correctly the variance components of protein concentration measurement in case of unbalanced design.}, author = {Klich, Amna and Mercier, Catherine and Gerfault, Laurent and Grangeat, Pierre and Beaulieu, Corinne and Degout-Charmette, Elodie and Fortin, Tanguy and Mah{\'{e}}, Pierre and Giovannelli, Jean Fran{\c{c}}ois and Charrier, Jean Philippe and Giremus, Audrey and Maucort-Boulch, Delphine and Roy, Pascal}, doi = {10.1186/s12859-018-2075-8}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Klich et al/BMC Bioinformatics/BMC Bioinformatics{\_}Klich et al.{\_}Variance component analysis to assess protein quantification in biomarker validation Application to sele.pdf:pdf}, issn = {14712105}, journal = {BMC Bioinformatics}, keywords = {Experimental design,Mass spectrometry,SRM,Technical variability,Validation biomarkers,Variance component analysis}, month = {mar}, number = {1}, publisher = {BioMed Central Ltd.}, title = {{Variance component analysis to assess protein quantification in biomarker validation: Application to selected reaction monitoring-mass spectrometry}}, volume = {19}, year = {2018} } @book{Lobry2018, abstract = {A complete case study with all coding sequences from the bacteria Borrellia burgdorferi illustrates how multivariate analyses reveals evolutionary mechanisms acting at the molecular level. They are either mutationnal (symmetric and asymmetric directionnal mutation pressure) or selective (selection against head-on collisions or linked to gene expressivity or subcellular location).}, author = {Lobry, Jean R.}, booktitle = {Multivariate Analyses of Codon Usage Biases}, doi = {10.1016/C2018-0-02165-9}, isbn = {9781785482960}, pages = {1--148}, title = {{Multivariate analyses of codon usage biases}}, url = {https://books.google.com/books?hl=fr{\&}lr={\&}id=r1h7DwAAQBAJ{\&}oi=fnd{\&}pg=PP1{\&}dq=CC+LBBE+PRABI{\&}ots=HoHy4k5c7g{\&}sig=thuhdGhGq2hAaSqPc{\_}bvsTEzNTU}, year = {2018} } @techreport{Clappe2018a, author = {Clappe, Sylvie}, title = {{Bringing methodological light to ecological processes : are ecological scales and constrained null models relevant solutions?}}, url = {https://tel.archives-ouvertes.fr/tel-02411567/ https://tel.archives-ouvertes.fr/tel-02411567v2}, year = {2018} } @article{David2018, abstract = {The anti-inflammatory ibuprofen is a ubiquitous surface water contaminant. However, the chronic impact of this pharmaceutical on aquatic invertebrate populations remains poorly understood. In model insect Aedes aegypti, we investigated the intergenerational consequences of parental chronic exposure to an environmentally relevant concentration of ibuprofen. While exposed individuals did not show any phenotypic changes, their progeny showed accelerated development and an increased tolerance to starvation. In order to understand the mechanistic processes underpinning the direct and intergenerational impacts of ibuprofen, we combined transcriptomic, metabolomics, and hormone kinetics studies at several life stages in exposed individuals and their progeny. This integrative approach revealed moderate transcriptional changes in exposed larvae consistent with the pharmacological mode of action of ibuprofen. Parental exposure led to lower levels of several polar metabolites in progeny eggs and to major transcriptional changes in the following larval stage. These transcriptional changes, most likely driven by changes in the expression of numerous transcription factors and epigenetic regulators, led to ecdysone signaling and stress response potentiation. Overall, the present study illustrates the complexity of the molecular basis of the intergenerational pollutant response in insects and the importance of considering the entire life cycle of exposed organisms and of their progeny in order to fully understand the mode of action of pollutants and their impact on ecosystems.}, author = {David, Jean-Philippe and Reynaud, St{\'{e}}phane}, doi = {10.1021/acs.est.8b00988}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/David, Reynaud/ACS Publications/ACS Publications{\_}David, Reynaud{\_}A multiscale approach to decipher molecular mechanisms involved in the direct and intergenerational effe.pdf:pdf}, journal = {ACS Publications}, month = {jul}, number = {14}, pages = {7937--7950}, publisher = {American Chemical Society}, title = {{A multiscale approach to decipher molecular mechanisms involved in the direct and intergenerational effect of ibuprofen on the mosquito Aedes aegypti}}, url = {https://www.researchgate.net/publication/325610950}, volume = {52}, year = {2018} } @article{Schermer2018, abstract = {In many perennial wind-pollinated plants, the dynamics of seed production is commonly known to be highly fluctuating from year to year and synchronised among individuals within populations. The proximate causes of such seeding dynamics, called masting, are still poorly understood in oak species that are widespread in the northern hemisphere, and whose fruiting dynamics dramatically impacts forest regeneration and biodiversity. Combining long-term surveys of oak airborne pollen amount and acorn production over large-scale field networks in temperate areas, and a mechanis-tic modelling approach, we found that the pollen dynamics is the key driver of oak masting. Mechanisms at play involved both internal resource allocation to pollen production synchronised among trees and spring weather conditions affecting the amount of airborne pollen available for reproduction. The sensitivity of airborne pollen to weather conditions might make oak masting and its ecological consequences highly sensitive to climate change.}, author = {Schermer, Eliane and Bel-Venner, Marie-Claude and Fouchet, David and elie Siberchicot, Aur and Boulanger, Vincent and Caignard, Thomas and Thibaudon, Michel and Oliver, Gilles and Nicolas, Manuel and Gaillard, Jean-Michel and Delzon, Sylvain and Venner, Samuel}, doi = {10.1111/ele.13171}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Schermer et al/Wiley Online Library/Wiley Online Library{\_}Schermer et al.{\_}Pollen limitation as a main driver of fruiting dynamics in oak populations{\_}2018.pdf:pdf}, journal = {Wiley Online Library}, keywords = {Masting,Quercus spp,pollen limitation,resource budget model,spring weather conditions}, month = {jan}, number = {1}, pages = {98--107}, publisher = {Blackwell Publishing Ltd}, title = {{Pollen limitation as a main driver of fruiting dynamics in oak populations}}, url = {http://cran.r-project.org}, volume = {22}, year = {2018} } @article{Varaldi2018, author = {Varaldi, Julien and Bernard, Claude and Lyon, University and Lepetit, David}, doi = {10.1017/S0031182018000835}, journal = {cambridge.org}, title = {{Deciphering the behaviour manipulation imposed by a virus on its parasitoid host: insights from a dual transcriptomic approach}}, url = {https://doi.org/10.1017/S0031182018000835}, year = {2018} } @article{Lambert2018, abstract = {Infectious diseases raise many concerns for wildlife and new insights must be gained to manage infected populations. Wild ungulates provide opportunities to gain such insights as they host many pathogens. Using modelling and data collected from an intensively monitored population of Pyrenean chamois, we investigated the role of stochastic processes in governing epidemiological patterns of pestivirus spread in both protected and hunted populations. We showed that demographic stochasticity led to three epidemiological outcomes: early infection fade-out, epidemic outbreaks with population collapse, either followed by virus extinction or by endemic situations. Without re-introduction, the virus faded out in {\textgreater}50{\%} of replications within 4 years and did not persist {\textgreater}20 years. Test-and-cull of infected animals and vaccination had limited effects relative to the efforts devoted, especially in hunted populations in which only quota reduction somewhat improve population recovery. Success of these strategies also relied on the maintenance of a high level of surveillance of hunter-harvested animals. Our findings suggested that, while surveillance and maintenance of population levels at intermediate densities to avoid large epidemics are useful at any time, a ‘do nothing' approach during epidemics could be the ‘least bad' management strategy in populations of ungulates species facing pestivirus infection.}, author = {Lambert, S{\'{e}}bastien and Ezanno, Pauline and Garel, Mathieu and Gilot-Fromont, Emmanuelle}, doi = {10.1038/s41598-018-34623-0}, issn = {20452322}, journal = {Scientific Reports}, number = {1}, pmid = {30442961}, title = {{Demographic stochasticity drives epidemiological patterns in wildlife with implications for diseases and population management}}, url = {https://www.nature.com/articles/s41598-018-34623-0}, volume = {8}, year = {2018} } @article{VENNER2018, author = {VENNER, S}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/VENNER/Unknown/Unknown{\_}VENNER{\_}Acronyme«PotenCh{\^{e}}ne»{\_}2018.pdf:pdf}, title = {{Acronyme:«PotenCh{\^{e}}ne»}}, url = {http://bgf.gip-ecofor.org/wp-content/uploads/2020/08/BGF{\_}PotenChene{\_}RapportFinal{\_}20180522.pdf}, year = {2018} } @article{Jaillard2018, abstract = {Genome-wide association study (GWAS) methods applied to bacterial genomes have shown promising results for genetic marker discovery or detailed assessment of marker effect. Recently, alignment-free methods based on k-mer composition have proven their ability to explore the accessory genome. However, they lead to redundant descriptions and results which are sometimes hard to interpret. Here we introduce DBGWAS, an extended k-mer-based GWAS method producing interpretable genetic variants associated with distinct phenotypes. Relying on compacted De Bruijn graphs (cDBG), our method gathers cDBG nodes, identified by the association model, into subgraphs defined from their neighbourhood in the initial cDBG. DBGWAS is alignment-free and only requires a set of contigs and phenotypes. In particular, it does not require prior annotation or reference genomes. It produces subgraphs representing phenotype-associated genetic variants such as local polymorphisms and mobile genetic elements (MGE). It offers a graphical framework which helps interpret GWAS results. Importantly it is also computationally efficient—experiments took one hour and a half on average. We validated our method using antibiotic resistance phenotypes for three bacterial species. DBGWAS recovered known resistance determinants such as mutations in core genes in Mycobacterium tuberculosis, and genes acquired by horizontal transfer in Staphylococcus aureus and Pseudomonas aeruginosa—along with their MGE context. It also enabled us to formulate new hypotheses involving genetic variants not yet described in the antibiotic resistance literature. An open-source tool implementing DBGWAS is available at https://gitlab.com/leoisl/dbgwas.}, author = {Jaillard, Magali and Lima, Leandro and Tournoud, Maud and Mah{\'{e}}, Pierre and van Belkum, Alex and Lacroix, Vincent and Jacob, Laurent}, doi = {10.1371/journal.pgen.1007758}, issn = {15537404}, journal = {PLoS Genetics}, number = {11}, pmid = {30419019}, title = {{A fast and agnostic method for bacterial genome-wide association studies: Bridging the gap between k-mers and genetic events}}, url = {https://journals.plos.org/plosgenetics/article?id=10.1371/journal.pgen.1007758}, volume = {14}, year = {2018} } @article{Davin2018, abstract = {Biodiversity has always been predominantly microbial, and the scarcity of fossils from bacteria, archaea and microbial eukaryotes has prevented a comprehensive dating of the tree of life. Here, we show that patterns of lateral gene transfer deduced from an analysis of modern genomes encode a novel and abundant source of information about the temporal coexistence of lineages throughout the history of life. We use state-of-The-Art species tree-Aware phylogenetic methods to reconstruct the history of thousands of gene families and demonstrate that dates implied by gene transfers are consistent with estimates from relaxed molecular clocks in Bacteria, Archaea and Eukarya. We present the order of speciations according to lateral gene transfer data calibrated to geological time for three datasets comprising 40 genomes for Cyanobacteria, 60 genomes for Archaea and 60 genomes for Fungi. An inspection of discrepancies between transfers and clocks and a comparison with mammalian fossils show that gene transfer in microbes is potentially as informative for dating the tree of life as the geological record in macroorganisms.}, author = {Dav{\'{i}}n, Adri{\'{a}}n A. and Tannier, Eric and Williams, Tom A. and Boussau, Bastien and Daubin, Vincent and Sz{\"{o}}llosi, Gergely J.}, doi = {10.1038/s41559-018-0525-3}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Zuckerkandl/Unknown/Unknown{\_}Zuckerkandl{\_}Gene transfers can date the tree of life{\_}2018.pdf:pdf}, issn = {2397334X}, journal = {Nature Ecology and Evolution}, number = {5}, pages = {904--909}, pmid = {29610471}, title = {{Gene transfers can date the tree of life}}, url = {https://d-nb.info/116171877X/34}, volume = {2}, year = {2018} } @article{Durif2018, abstract = {Motivation The high dimensionality of genomic data calls for the development of specific classification methodologies, especially to prevent over-optimistic predictions. This challenge can be tackled by compression and variable selection, which combined constitute a powerful framework for classification, as well as data visualization and interpretation. However, current proposed combinations lead to unstable and non convergent methods due to inappropriate computational frameworks. We hereby propose a computationally stable and convergent approach for classification in high dimensional based on sparse Partial Least Squares (sparse PLS). Results We start by proposing a new solution for the sparse PLS problem that is based on proximal operators for the case of univariate responses. Then we develop an adaptive version of the sparse PLS for classification, called logit-SPLS, which combines iterative optimization of logistic regression and sparse PLS to ensure computational convergence and stability. Our results are confirmed on synthetic and experimental data. In particular, we show how crucial convergence and stability can be when cross-validation is involved for calibration purposes. Using gene expression data, we explore the prediction of breast cancer relapse. We also propose a multicategorial version of our method, used to predict cell-Types based on single-cell expression data.}, archivePrefix = {arXiv}, arxivId = {1502.05933}, author = {Durif, Ghislain and Modolo, Laurent and Michaelsson, Jakob and Mold, Jeff E. and Lambert-Lacroix, Sophie and Picard, Franck}, doi = {10.1093/bioinformatics/btx571}, eprint = {1502.05933}, issn = {14602059}, journal = {Bioinformatics}, number = {3}, pages = {485--493}, pmid = {28968879}, title = {{High dimensional classification with combined adaptive sparse PLS and logistic regression}}, url = {https://academic.oup.com/bioinformatics/article-abstract/34/3/485/4157444}, volume = {34}, year = {2018} } @article{Benoit-Pilven2018, abstract = {Genome-wide analyses estimate that more than 90{\%} of multi exonic human genes produce at least two transcripts through alternative splicing (AS). Various bioinformatics methods are available to analyze AS from RNAseq data. Most methods start by mapping the reads to an annotated reference genome, but some start by a de novo assembly of the reads. In this paper, we present a systematic comparison of a mapping-first approach (FaRLine) and an assembly-first approach (KisSplice). We applied these methods to two independent RNAseq datasets and found that the predictions of the two pipelines overlapped (70{\%} of exon skipping events were common), but with noticeable differences. The assembly-first approach allowed to find more novel variants, including novel unannotated exons and splice sites. It also predicted AS in recently duplicated genes. The mapping-first approach allowed to find more lowly expressed splicing variants, and splice variants overlapping repeats. This work demonstrates that annotating AS with a single approach leads to missing out a large number of candidates, many of which are differentially regulated across conditions and can be validated experimentally. We therefore advocate for the combined use of both mapping-first and assembly-first approaches for the annotation and differential analysis of AS from RNAseq datasets.}, author = {Benoit-Pilven, Clara and Marchet, Camille and Chautard, Emilie and Lima, Leandro and Lambert, Marie Pierre and Sacomoto, Gustavo and Rey, Amandine and Cologne, Audric and Terrone, Sophie and Dulaurier, Louis and Claude, Jean Baptiste and Bourgeois, Cyril F. and Auboeuf, Didier and Lacroix, Vincent}, doi = {10.1038/s41598-018-21770-7}, issn = {20452322}, journal = {Scientific Reports}, number = {1}, pmid = {29523794}, title = {{Complementarity of assembly-first and mapping-first approaches for alternative splicing annotation and differential analysis from RNAseq data}}, url = {https://www.nature.com/articles/s41598-018-21770-7}, volume = {8}, year = {2018} } @article{Kremer2018, abstract = {In horizontally transmitted symbioses, structural, biochemical, and molecular features both facilitate host colonization by specific symbionts and mediate their persistent carriage. In the association between the squid Euprymna scolopes and its luminous bacterial partner Vibrio fischeri, the symbionts interact with two ep-ithelial fields; they interact (i) transiently with the superficial ciliated field that poten-tiates colonization and regresses within days of colonization and (ii) persistently with the cells that line the internal crypts, whose ultrastructure changes in response to the symbionts. Development of the association creates conditions that promote the symbiotic partner over the lifetime of the host. To determine whether light organ maturation requires continuous interactions with V. fischeri or only the signaling that occurs during its initiation, we compared 4-week-old squid that were uncolonized with those colonized either persistently by wild-type V. fischeri or transiently by a V. fischeri mutant that triggers early events in morphogenesis but does not persist. Microscopic analysis of the light organs showed that, while morphogenesis of the superficial ciliated field is greatly accelerated by V. fischeri colonization, its eventual outcome is largely independent of colonization state. In contrast, the symbiont-induced changes in crypt cell shape require persistent host-symbiont interaction, reflected in the similarity between uncolonized and transiently colonized animals. Transcriptomic analyses reflected the microscopy results; host gene expression at 4 weeks was due primarily to the persistent interactions of host and symbiont cells. Further, the transcriptomic signature of specific pathways reflected the daily rhythm of symbiont release and regrowth and required the presence of the symbionts. IMPORTANCE A long-term relationship between symbiotic partners is often characterized by development and maturation of host structures that harbor the symbiont cells over the host's lifetime. To understand the mechanisms involved in symbiosis maintenance more fully, we studied the mature bobtail squid, whose light-emitting organ, under experimental conditions, can be transiently or persistently colonized by Vibrio fischeri or remain uncolonized. Superficial anatomical changes in the organ were largely independent of symbiosis. However, both the microanatomy of cells with which symbionts interact and the patterns of gene expression in the mature animal were due principally to the persistent interactions of host and symbiont cells rather than to a response to early colonization events. Further, the characteristic pronounced daily rhythm on the host transcriptome required persistent V. fischeri colonization of the organ. This experimental study provides a window into how persistent symbiotic colonization influences the form and function of host animal tissues. Citation Kremer N, Koch EJ, El Filali A, Zhou L, Heath-Heckman EAC, Ruby EG, McFall-Ngai MJ. 2018. Persistent interactions with bacterial symbionts direct mature-host cell morphology and gene expression in the squid-vibrio symbiosis. mSystems 3:e00165-18. https://doi .}, author = {Kremer, Natacha and Koch, Eric J and Filali, Adil El and Zhou, Lawrence and Heath-Heckman, Elizabeth A C and Ruby, Edward G and Mcfall-Ngai, Margaret J}, doi = {10.1128/mSystems.00165-18}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Kremer et al/Am Soc Microbiol/Am Soc Microbiol{\_}Kremer et al.{\_}Persistent Interactions with Bacterial Symbionts Direct Mature-Host Cell Morphology and Gene Expression i.pdf:pdf}, journal = {Am Soc Microbiol}, month = {oct}, number = {5}, pages = {165--183}, publisher = {American Society for Microbiology}, title = {{Persistent Interactions with Bacterial Symbionts Direct Mature-Host Cell Morphology and Gene Expression in the Squid-Vibrio Symbiosis}}, url = {https://journals.asm.org/doi/abs/10.1128/mSystems.00165-18}, volume = {3}, year = {2018} } @article{Jaillard2018a, abstract = {Genome-wide association study (GWAS) methods applied to bacterial genomes have shown promising results for genetic marker discovery or detailed assessment of marker effect. Recently, alignment-free methods based on k-mer composition have proven their ability to explore the accessory genome. However, they lead to redundant descriptions and results which are sometimes hard to interpret. Here we introduce DBGWAS, an extended k-mer-based GWAS method producing interpretable genetic variants associated with distinct phenotypes. Relying on compacted De Bruijn graphs (cDBG), our method gathers cDBG nodes, identified by the association model, into subgraphs defined from their neighbourhood in the initial cDBG. DBGWAS is alignment-free and only requires a set of contigs and phenotypes. In particular, it does not require prior annotation or reference genomes. It produces subgraphs representing phenotype-associated genetic variants such as local polymorphisms and mobile genetic elements (MGE). It offers a graphical framework which helps interpret GWAS results. Importantly it is also computationally efficient—experiments took one hour and a half on average. We validated our method using antibiotic resistance phenotypes for three bacterial species. DBGWAS recovered known resistance determinants such as mutations in core genes in Mycobacterium tuberculosis, and genes acquired by horizontal transfer in Staphylococcus aureus and Pseudomonas aeruginosa—along with their MGE context. It also enabled us to formulate new hypotheses involving genetic variants not yet described in the antibiotic resistance literature. An open-source tool implementing DBGWAS is available at https://gitlab.com/leoisl/dbgwas.}, author = {Jaillard, Magali and Lima, Leandro and Tournoud, Maud and Mah{\'{e}}, Pierre and van Belkum, Alex and Lacroix, Vincent and Jacob, Laurent}, doi = {10.1371/journal.pgen.1007758}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Jaillard et al/PLoS Genetics/PLoS Genetics{\_}Jaillard et al.{\_}A fast and agnostic method for bacterial genome-wide association studies Bridging the gap between k-mers a.pdf:pdf}, issn = {15537404}, journal = {PLoS Genetics}, month = {nov}, number = {11}, pmid = {30419019}, publisher = {Public Library of Science}, title = {{A fast and agnostic method for bacterial genome-wide association studies: Bridging the gap between k-mers and genetic events}}, volume = {14}, year = {2018} } @article{Martin2018, abstract = {Context: Routine movements of large herbivores, often considered as ecosystem engineers, impact key ecological processes. Functional landscape connectivity for such species influences the spatial distribution of associated ecological services and disservices. Objectives: We studied how spatio-temporal variation in the risk-resource trade-off, generated by fluctuations in human activities and environmental conditions, influences the routine movements of roe deer across a heterogeneous landscape, generating shifts in functional connectivity at daily and seasonal time scales. Methods: We used GPS locations of 172 adult roe deer and step selection functions to infer landscape connectivity. In particular, we assessed the influence of six habitat features on fine scale movements across four biological seasons and three daily periods, based on variations in the risk-resource trade-off. Results: The influence of habitat features on roe deer movements was strongly dependent on proximity to refuge habitat, i.e. woodlands. Roe deer confined their movements to safe habitats during daytime and during the hunting season, when human activity is high. However, they exploited exposed open habitats more freely during night-time. Consequently, we observed marked temporal shifts in landscape connectivity, which was highest at night in summer and lowest during daytime in autumn. In particular, the onset of the autumn hunting season induced an abrupt decrease in landscape connectivity. Conclusions: Human disturbance had a strong impact on roe deer movements, generating pronounced spatio-temporal variation in landscape connectivity. However, high connectivity at night across all seasons implies that Europe's most abundant and widespread large herbivore potentially plays a key role in transporting ticks, seeds and nutrients among habitats.}, author = {Martin, Jodie and Vourc'h, Gwena{\"{e}}l and Bonnot, Nad{\`{e}}ge and Cargnelutti, Bruno and Chaval, Yannick and Lourtet, Bruno and Goulard, Michel and Hoch, Thierry and Plantard, Olivier and Hewison, A. J.Mark and Morellet, Nicolas}, doi = {10.1007/s10980-018-0641-0}, issn = {15729761}, journal = {Landscape Ecology}, keywords = {Capreolus capreolus,Fragmentation,Habitat selection,Human activity,Human infrastructures,Step selection functions}, month = {jun}, number = {6}, pages = {937--954}, publisher = {Springer Netherlands}, title = {{Temporal shifts in landscape connectivity for an ecosystem engineer, the roe deer, across a multiple-use landscape}}, volume = {33}, year = {2018} } @article{Larroque2018, abstract = {Some of the authors of this publication are also working on these related projects: Genetic connectivity of deep sea species: focus on bivalves, shrimps and gastropods of the Atlantic ocean using RAD sequencing. View project Parasitism and spatial genetic structure.Example of the Mediteranean Mouflon (Ovis gmelini musimon x Ovis sp.). View project Elodie Portanier Station Biologique de Roscoff The user has requested enhancement of the downloaded file.}, author = {Larroque, Jeremy and Marchand, Pascal and Maillard, Daniel}, doi = {10.1007/s10980-018-0650-z}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Larroque, Marchand, Maillard/Springer/Springer{\_}Larroque, Marchand, Maillard{\_}Landscape genetics matches with behavioral ecology and brings new insight on the functional connec.pdf:pdf}, journal = {Springer}, keywords = {Causal modeling,Functional landscape connectivity,Landscape genetics,Mammals,Mediterranean mouflon,Ovis}, month = {jul}, number = {7}, pages = {1069--1085}, publisher = {Springer Netherlands}, title = {{Landscape genetics matches with behavioral ecology and brings new insight on the functional connectivity in Mediterranean mouflon}}, url = {https://doi.org/10.1007/s10980-018-0650-z}, volume = {33}, year = {2018} } @article{Medigue2018, abstract = {The overwhelming list of new bacterial genomes becoming available on a daily basis makes accurate genome annotation an essential step that ultimately determines the relevance of thousands of genomes stored in public databanks. The MicroScope platform (http://www.genoscope.cns.fr/agc/microscope) is an integrative resource that supports systematic and efficient revision of microbial genome annotation, data management and comparative analysis. Starting from the results of our syntactic, functional and relational annotation pipelines, MicroScope provides an integrated environment for the expert annotation and comparative analysis of prokaryotic genomes. It combines tools and graphical interfaces to analyze genomes and to perform the manual curation of gene function in a comparative genomics and metabolic context. In this article, we describe the free-of-charge MicroScope services for the annotation and analysis of microbial (meta)genomes, transcriptomic and re-sequencing data. Then, the functionalities of the platform are presented in a way providing practical guidance and help to the nonspecialists in bioinformatics. Newly integrated analysis tools (i.e. prediction of virulence and resistance genes in bacterial genomes) and original method recently developed (the pan-genome graph representation) are also described. Integrated environments such as MicroScope clearly contribute, through the user community, to help maintaining accurate resources.}, author = {M{\'{e}}digue, Claudine and Calteau, Alexandra and Cruveiller, St{\'{e}}phane and Gachet, Mathieu and Gautreau, Guillaume and Josso, Adrien and Lajus, Aur{\'{e}}lie and Langlois, Jordan and Pereira, Hugo and Planel, R{\'{e}}mi and Roche, David and Rollin, Johan and Rouy, Zoe and Vallenet, David}, doi = {10.1093/bib/bbx113}, issn = {14774054}, journal = {Briefings in Bioinformatics}, keywords = {comparative genomics,gene function curation,metabolic networks,microbial genome annotation system,transcriptomics,variant detection}, number = {4}, pages = {1071--1084}, pmid = {28968784}, title = {{MicroScope-An integrated resource for community expertise of gene functions and comparative analysis of microbial genomic and metabolic data}}, url = {https://academic.oup.com/bib/article-abstract/20/4/1071/4157326}, volume = {20}, year = {2018} } @article{Lemopoulos2018, abstract = {The Guianas are one of the most diverse regions of the Neotropics, hosting a particularly high rate of freshwater fish ende-mism. The present distributional patterns of freshwater fish species in the major catchments of the Guianas (comprising Guyana, Suriname and French Guiana) were analysed to reveal the faunal relationships between rivers, evaluate different hypotheses concerning biogeographical units, and redefine the boundaries of the Guianese freshwater ecoregions. A parsimony analysis of endemicity was performed using a data partitioning strategy to alleviate some drawbacks inherent to the method (e.g. long branch attraction artefact, heterotachy), and take into account alternative parsimony models assigning different constraints on state changes for the different species. A strong spatial element was present in the data with a structuring of species along a west-east gradient. Two main biogeographical units were highlighted: one to the west, ranging from the Essequibo to the Com-mewijne rivers and including the Proto Berbice and Surinamese regions, and one to the east ranging from the Maroni to the Oyapock rivers and including the Western, Central and Eastern French Guiana regions. Each ecoregion possessed distinctive fish assemblages, and three to four potential zones of faunal exchanges between Amazonian and Guianese rivers have been confirmed.}, author = {Lemopoulos, Alexandre and {El Covain}, Rapha€}, doi = {10.1111/cla.12341}, journal = {Wiley Online Library}, month = {feb}, number = {1}, pages = {106--124}, publisher = {Blackwell Publishing Inc.}, title = {{Biogeography of the freshwater fishes of the Guianas using a partitioned parsimony analysis of endemicity with reappraisal of ecoregional boundaries}}, url = {http://www.worldwildlife.org/pages/hydrosheds}, volume = {35}, year = {2018} } @article{Muyle2018, abstract = {Sex chromosomes have repeatedly evolved from a pair of autosomes. Consequently, X and Y chromosomes initially have similar gene content, but ongoing Y degeneration leads to reduced expression and eventual loss of Y genes1. The resulting imbalance in gene expression between Y genes and the rest of the genome is expected to reduce male fitness, especially when protein networks have components from both autosomes and sex chromosomes. A diverse set of dosage compensating mechanisms that alleviates these negative effects has been described in animals2–4. However, the early steps in the evolution of dosage compensation remain unknown, and dosage compensation is poorly understood in plants5. Here, we describe a dosage compensation mechanism in the evolutionarily young XY sex determination system of the plant Silene latifolia. Genomic imprinting results in higher expression from the maternal X chromosome in both males and females. This compensates for reduced Y expression in males, but results in X overexpression in females and may be detrimental. It could represent a transient early stage in the evolution of dosage compensation. Our finding has striking resemblance to the first stage proposed by Ohno6 for the evolution of X inactivation in mammals.}, author = {Muyle, Aline and Zemp, Niklaus and Fruchard, C{\'{e}}cile and Cegan, Radim and Vrana, Jan and Deschamps, Clothilde and Tavares, Raquel and Hobza, Roman and Picard, Franck and Widmer, Alex and Marais, Gabriel A.B.}, doi = {10.1038/s41477-018-0221-y}, issn = {20550278}, journal = {Nature Plants}, month = {sep}, number = {9}, pages = {677--680}, pmid = {30104649}, publisher = {Palgrave Macmillan Ltd.}, title = {{Genomic imprinting mediates dosage compensation in a young plant XY system}}, volume = {4}, year = {2018} } @article{Duchemin2018, abstract = {Motivation: A reconciliation is an annotation of the nodes of a gene tree with evolutionary events—for example, speciation, gene duplication, transfer, loss, etc.—along with a mapping onto a species tree. Many algorithms and software produce or use reconciliations but often using different reconciliation formats, regarding the type of events considered or whether the species tree is dated or not. This complicates the comparison and communication between different programs. Results: Here, we gather a consortium of software developers in gene tree species tree reconciliation to propose and endorse a format that aims to promote an integrative—albeit flexible—specification of phylogenetic reconciliations. This format, named recPhyloXML, is accompanied by several tools such as a reconciled tree visualizer and conversion utilities.}, author = {Duchemin, Wandrille and Gence, Guillaume and Chifolleau, Anne Muriel Arigon and Arvestad, Lars and Bansal, Mukul S. and Berry, Vincent and Boussau, Bastien and Chevenet, Fran{\c{c}}ois and Comte, Nicolas and Dav{\'{i}}n, Adri{\'{a}}n A. and Dessimoz, Christophe and Dylus, David and Hasic, Damir and Mallo, Diego and Planel, R{\'{e}}mi and Posada, David and Scornavacca, Celine and Sz{\"{o}}llősi, Gergely and Zhang, Louxin and Tannier, {\'{E}}ric and Daubin, Vincent}, doi = {10.1093/bioinformatics/bty389}, file = {:Users/navratil/Documents/Mendeley Desktop/2018/Duchemin et al/Bioinformatics/Bioinformatics{\_}Duchemin et al.{\_}RecPhyloXML A format for reconciled gene trees{\_}2018.pdf:pdf}, issn = {14602059}, journal = {Bioinformatics}, number = {21}, pages = {3646--3652}, pmid = {29762653}, publisher = {Oxford University Press}, title = {{RecPhyloXML: A format for reconciled gene trees}}, volume = {34}, year = {2018} } @article{Durif2017, abstract = {The statistical analysis of Next-Generation Sequencing (NGS) data has raised many computational challenges regarding modeling and inference. High-throughput technologies now allow to monitor the expression of thou- sands of genes while considering a growing number of individuals, such as hundreds of single cells. Despite the increasing number of observations, ge- nomic data remain characterized by their high-dimensionality. The research directions that will be explored in this manuscript concern hybrid dimen- sion reduction methods that rely on both compression (representation of the data into a lower dimensional space) and variable selection. Developments are made concerning: i) the sparse Partial Least Squares (PLS) regression framework for supervised classification, and ii) the sparse matrix factoriza- tion framework for unsupervised exploration. In both situations, our main purpose will be to focus on the reconstruction and visualization of the com- plex organization of the data. In this regard, we tackle particular challenges regarding the development of methods to analyze high-dimensional data, since the dimensionality di- rectly interferes with the optimization procedures. In a first part, we will de- velop a sparse PLS approach, based on an adaptive sparsity-inducing penalty, that is suitable for logistic regression, e.g. to predict the label of a discrete outcome, such as the fate of patients or the specific type of unidentified sin- gle cells based on gene expression profiles. The main issue in such framework is to account for the response when discarding irrelevant variables. We will highlight the direct link between the derivation of the algorithms and the reliability of the results. In a second part, motivated by questions regarding single-cell data anal- ysis, we will consider the framework of matrix factorization for count data. We propose a model-based approach that is very flexible, and that accounts for over-dispersion as well as zero-inflation (both characteristic of single-cell data). Our matrix factorization method relies on a hierarchical model for which we derive an estimation procedure based on variational inference. In this scheme, we consider variable selection based on a spike-and-slab model suitable for count data. The interest of our procedure for data reconstruc- tion, visualization and clustering will be illustrated in simulation experiments and by presenting preliminary results of an on-going analysis of single-cell data. All proposed statistical methods were implemented into two R packages plsgenomics and CMF based on high performance computing.}, author = {Durif, Ghislain}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Durif/PhD Thesis/PhD Thesis{\_}Durif{\_}Multivariate analysis of high throughput sequencing data{\_}2017.pdf:pdf}, journal = {PhD Thesis}, title = {{Multivariate analysis of high throughput sequencing data}}, url = {https://tel.archives-ouvertes.fr/tel-01581175}, year = {2017} } @article{Chehimi2017, author = {Chehimi, M and Delort, L and de la {\ldots}, H Vidal - Forum and 2017, Undefined}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Chehimi et al/hal.archives-ouvertes.fr/hal.archives-ouvertes.fr{\_}Chehimi et al.{\_}Contribution of adipose stem cells from obese subjects to hepato-or breast-carcinoma tumorogenes.pdf:pdf}, journal = {hal.archives-ouvertes.fr}, title = {{Contribution of adipose stem cells from obese subjects to hepato-or breast-carcinoma tumorogenesis, through promotion of Th17 cells}}, url = {https://hal.archives-ouvertes.fr/hal-01563610/}, year = {2017} } @article{Delort2017, author = {Delort, L and Decombat, C and de la {\ldots}, M Vermerie - Forum and 2017, Undefined}, journal = {hal.archives-ouvertes.fr}, title = {{Impact des adipocytes et de leur secr{\'{e}}tome sur l'efficacit{\'{e}} de l'hormonoth{\'{e}}rapie dans le cancer du sein en situation de surpoids/ob{\'{e}}sit{\'{e}}}}, url = {https://hal.archives-ouvertes.fr/hal-01562311/}, year = {2017} } @article{Lassalle2017a, abstract = {Horizontal gene transfer (HGT) is considered as a major source of innovation in bacteria, and as such is expected to drive adaptation to new ecological niches. However, among the many genes acquired through HGT along the diversification history of genomes, only a fraction may have actively contributed to sustained ecological adaptation. We used a phylogenetic approach accounting for the transfer of genes (or groups of genes) to estimate the history of genomes in Agrobacterium biovar 1, a diverse group of soil and plant-dwelling bacterial species. We identified clade-specific blocks of cotransferred genes encoding coherent biochemical pathways that may have contributed to the evolutionary success of key Agrobacterium clades. This pattern of gene coevolution rejects a neutral model of transfer, in which neighboring genes would be transferred independently of their function and rather suggests purifying selection on collectively coded acquired pathways. The acquisition of these synapomorphic blocks of cofunctioning genes probably drove the ecological diversification of Agrobacterium and defined features of ancestral ecological niches, which consistently hint at a strong selective role of host plant rhizospheres.}, author = {Lassalle, Florent and Planel, R{\'{e}}mi and Penel, Simon and Chapulliot, David and Barbe, Val{\'{e}}rie and Dubost, Audrey and Calteau, Alexandra and Vallenet, David and Mornico, Damien and Bigot, Thomas and Gu{\'{e}}guen, Laurent and Vial, Ludovic and Muller, Daniel and Daubin, Vincent and Nesme, Xavier}, doi = {10.1093/gbe/evx255}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Agrobacterium tumefaciens,HGT,ancestral genome,cotransferred genes,reverse ecology,tree reconciliation}, number = {12}, pages = {3413--3431}, pmid = {29220487}, title = {{Ancestral Genome Estimation Reveals the History of Ecological Diversification in Agrobacterium}}, url = {https://academic.oup.com/gbe/article-abstract/9/12/3413/4697203}, volume = {9}, year = {2017} } @article{Rivals2017, author = {Rivals, Eric and Ainouche, Malika and Ird, Umr-diade and Cristina, Vieira and Vincent, Lacroix}, title = {{Analyses et m{\'{e}}thodes pour les donn{\'{e}}es transcriptomiques issues d'esp{\`{e}}ces non mod{\`{e}}les}}, url = {https://tel.archives-ouvertes.fr/tel-01575640/}, year = {2017} } @article{Pouyet2017, abstract = {Synonymous codon usage (SCU) varies widely among human genes. In particular, genes involved in different functional categories display a distinct codon usage, which was interpreted as evidence that SCU is adaptively constrained to optimize translation efficiency in distinct cellular states. We demonstrate here that SCU is not driven by constraints on tRNA abundance, but by large-scale variation in GC-content, caused by meiotic recombination, via the non-adaptive process of GC-biased gene conversion (gBGC). Expression in meiotic cells is associated with a strong decrease in recombination within genes. Differences in SCU among functional categories reflect differences in levels of meiotic transcription, which is linked to variation in recombination and therefore in gBGC. Overall, the gBGC model explains 70{\%} of the variance in SCU among genes. We argue that the strong heterogeneity of SCU induced by gBGC in mammalian genomes precludes any optimization of the tRNA pool to the demand in codon usage.}, author = {Pouyet, Fanny and Mouchiroud, Dominique and Duret, Laurent and S{\'{e}}mon, Marie}, doi = {10.7554/eLife.27344}, issn = {2050084X}, journal = {eLife}, pmid = {28826480}, title = {{Recombination, meiotic expression and human codon usage}}, url = {https://search.proquest.com/openview/e6da8970d9ba271849130fe0c489ce60/1?pq-origsite=gscholar{\&}cbl=2045579}, volume = {6}, year = {2017} } @article{Lefebure2017, abstract = {The evolutionary origin of the striking genome size variations found in eukaryotes remains enigmatic. The effective size of populations, by controlling selection efficacy, is expected to be a key parameter underlying genome size evolution. However, this hypothesis has proved difficult to investigate using empirical data sets. Here, we tested this hypothesis using 22 de novo transcriptomes and low-coverage genomes of asellid isopods, which represent 11 independent habitat shifts from surface water to resource-poor groundwater. We show that these habitat shifts are associated with higher transcriptomewide dN/dS. After ruling out the role of positive selection and pseudogenization, we show that these transcriptome-wide dN/dS increases are the consequence of a reduction in selection efficacy imposed by the smaller effective population size of subterranean species. This reduction is paralleled by an important increase in genome size (25{\%} increase on average), an increase also confirmed in subterranean decapods and mollusks. We also control for an adaptive impact of genome size on life history traits but find no correlation between body size, or growth rate, and genome size. We show instead that the independent increases in genome size measured in subterranean isopods are the direct consequence of increasing invasion rates by repeat elements, which are less efficiently purged out by purifying selection. Contrary to selection efficacy, polymorphism is not correlated to genome size. We propose that recent demographic fluctuations and the difficulty of observing polymorphism variation in polymorphism-poor species can obfuscate the link between effective population size and genome size when polymorphism data are used alone.}, author = {Lef{\'{e}}bure, Tristan and Morvan, Claire and Malard, Florian and Fran{\c{c}}ois, Cl{\'{e}}mentine and Konecny-Dupr{\'{e}}, Lara and Gu{\'{e}}guen, Laurent and Weiss-Gayet, Mich{\`{e}}le and Seguin-Orlando, Andaine and Ermini, Luca and Sarkissian, Clio Der and {Pierre Charrier}, N. and Eme, David and Mermillod-Blondin, Florian and Duret, Laurent and Vieira, Cristina and Orlando, Ludovic and Douady, Christophe Jean}, doi = {10.1101/gr.212589.116}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Lef{\'{e}}bure et al/Genome Research/Genome Research{\_}Lef{\'{e}}bure et al.{\_}Less effective selection leads to larger genomes{\_}2017.pdf:pdf}, issn = {15495469}, journal = {Genome Research}, month = {jun}, number = {6}, pages = {1016--1028}, pmid = {28424354}, publisher = {Cold Spring Harbor Laboratory Press}, title = {{Less effective selection leads to larger genomes}}, url = {http://www.genome.org/cgi/doi/10.1101/gr.212589.116.}, volume = {27}, year = {2017} } @article{Verin2017, abstract = {Many life-history traits are important determinants of the generation time. For instance, semelparous species whose adults reproduce only once have shorter generation times than iteroparous species that reproduce on several occasions, assuming equal development duration. A shorter generation time ensures a higher growth rate in stable environments where resources are in excess and is therefore a positively selected feature in this situation. In a stable and limiting environment, all combinations of traits that produce the same number of viable offspring are selectively equivalent. Here we study the neutral evolution of life-history strategies with different generation times and show that the slowest strategy represents the most likely evolutionary outcome when mutation is considered. Indeed, strategies with longer generation times generate fewer mutants per time unit, which makes them less likely to be replaced within a given time period. This turnover bias favors the evolution of strategies with long generation times. Its real impact, however, depends on both the population size and the nature of selection on life-history strategies. The latter is primarily impacted by the relationships between life-history traits whose estimation will be crucial to understanding the evolution of life-history strategies.}, archivePrefix = {arXiv}, arxivId = {1502.05508}, author = {Verin, M{\'{e}}lissa and Bourg, Salom{\'{e}} and Menu, Fr{\'{e}}d{\'{e}}ric and Rajon, Etienne}, doi = {10.1086/692324}, eprint = {1502.05508}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Verin et al/American Naturalist/American Naturalist{\_}Verin et al.{\_}The biased evolution of generation time{\_}2017.pdf:pdf}, issn = {00030147}, journal = {American Naturalist}, keywords = {Aging,Developmental time,Evolutionary demography,Mutation bias,Neutral theory,Reproductive strategies}, number = {2}, pages = {E28--E39}, pmid = {28731790}, title = {{The biased evolution of generation time}}, url = {https://www.journals.uchicago.edu/doi/abs/10.1086/692324}, volume = {190}, year = {2017} } @article{Lopez-Maestre2017, abstract = {Crosses between close species can lead to genomic disorders, often considered to be the cause of hybrid incompatibility, one of the initial steps in the speciation process. How these incompatibilities are established and what are their causes remain unclear. To understand the initiation of hybrid incompatibility, we performed reciprocal crosses between two species of Drosophila (D. mojavensis and D. arizonae) that diverged less than 1 Mya. We performed a genome-wide transcriptomic analysis on ovaries from parental lines and on hybrids from reciprocal crosses. Using an innovative procedure of co-assembling transcriptomes, we show that parental lines differ in the expression of their genes and transposable elements. Reciprocal hybrids presented specific gene categories and few transposable element families misexpressed relative to the parental lines. Because TEs are mainly silenced by piwi-interacting RNAs (piRNAs), we hypothesize that in hybrids the deregulation of specific TE families is due to the absence of such small RNAs. Small RNA sequencing confirmed our hypothesis and we therefore propose that TEs can indeed be major players of genome differentiation and be implicated in the first steps of genomic incompatibilities through small RNA regulation.}, author = {Lopez-Maestre, H{\'{e}}l{\`{e}}ne and Carnelossi, Elias A.G. and Lacroix, Vincent and Burlet, Nelly and Mugat, Bruno and Chambeyron, S{\'{e}}verine and Carareto, Claudia M.A. and Vieira, Cristina}, doi = {10.1038/srep40618}, issn = {20452322}, journal = {Scientific Reports}, pmid = {28091568}, title = {{Identification of misexpressed genetic elements in hybrids between Drosophila-related species}}, url = {https://www.nature.com/articles/srep40618}, volume = {7}, year = {2017} } @article{Benoit-Pilven2017, author = {Benoit-Pilven, C and Marchet, C and Chautard, E and Lima, L}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Benoit-Pilven et al/Unknown/Unknown{\_}Benoit-Pilven et al.{\_}Annotation and differential analysis of alternative splicing using de novo assembly of RNAseq data{\_}2017.pdf:pdf}, title = {{Annotation and differential analysis of alternative splicing using de novo assembly of RNAseq data}}, url = {https://hal.archives-ouvertes.fr/hal-01643169/}, year = {2017} } @article{Bailly-Bechet2017, abstract = {Wolbachia bacteria infect about half of all arthropods, with diverse and extreme consequences ranging from sex-ratio distortion and mating incompatibilities to protection against viruses. These phenotypic effects, combined with efficient vertical transmission from mothers to offspring, satisfactorily explain the invasion dynamics of Wolbachia within species. However, beyond the species level, the lack of congruence between the host and symbiont phylogenetic trees indicates that Wolbachia horizontal transfers and extinctions do happen and underlie its global distribution. But how often do they occur? And has the Wolbachia pandemic reached its equilibrium? Here, we address these questions by inferring recent acquisition/loss events from the distribution of Wolbachia lineages across the mitochondrial DNA tree of 3,600 arthropod specimens, spanning 1,100 species from Tahiti and surrounding islands. We show that most events occurred within the last million years, but are likely attributable to individual level variation (e.g., imperfect maternal transmission) rather than population level variation (e.g., Wolbachia extinction). At the population level, we estimate that mitochondria typically accumulate 4.7{\%} substitutions per site during an infected episode, and 7.1{\%} substitutions per site during the uninfected phase. Using a Bayesian time calibration of the mitochondrial tree, these numbers translate into infected and uninfected phases of approximately 7 and 9 million years. Infected species thus lose Wolbachia slightly more often than uninfected species acquire it, supporting the view that its present incidence, estimated here slightly below 0.5, represents an epidemiological equilibrium.}, author = {Bailly-Bechet, Marc and Martins-Sim{\~{o}}es, Patricia and Sz{\"{o}}llosi, Gergely J. and Mialdea, Gladys and Sagot, Marie France and Charlat, Sylvain}, doi = {10.1093/molbev/msx073}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {Arthropods,Evolutionary dynamics,Horizontal transfer,Symbiosis,Wolbachia}, number = {5}, pages = {1183--1193}, pmid = {28201740}, title = {{How Long Does Wolbachia Remain on Board?}}, url = {https://academic.oup.com/mbe/article-abstract/34/5/1183/2992913}, volume = {34}, year = {2017} } @article{Matassi2017, abstract = {Background: Rh50 proteins belong to the family of ammonia permeases together with their Amt/MEP homologs. Ammonia permeases increase the permeability of NH3/NH4 + across cell membranes and are believed to be involved in excretion of toxic ammonia and in the maintenance of pH homeostasis. RH50 genes are widespread in eukaryotes but absent in land plants and fungi, and remarkably rare in prokaryotes. The evolutionary history of RH50 genes in prokaryotes is just beginning to be unveiled. Results: Here, a molecular phylogenetic approach suggests horizontal gene transfer (HGT) as a primary force driving the evolution and spread of RH50 among prokaryotes. In addition, the taxonomic distribution of the RH50 gene among prokaryotes turned out to be very narrow; a single-copy RH50 is present in the genome of only a small proportion of Bacteria, and, first evidence to date, in only three methanogens among Euryarchaea. The coexistence of RH50 and AMT in prokaryotes seems also a rare event. Finally, phylogenetic analyses were used to reconstruct the HGT network along which prokaryotic RH50 evolution has taken place. Conclusions: The eukaryotic or bacterial “origin” of the RH50 gene remains unsolved. The RH50 prokaryotic HGT network suggests a preferential directionality of transfer from aerobic to anaerobic organisms. The observed HGT events between archaeal methanogens, anaerobic and aerobic ammonia-oxidizing bacteria suggest that syntrophic relationships play a major role in the structuring of the network, and point to oxygen minimum zones as an ecological niche that might be of crucial importance for HGT-driven evolution.}, author = {Matassi, Giorgio}, doi = {10.1186/s12862-016-0850-6}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Matassi/BMC Evolutionary Biology/BMC Evolutionary Biology{\_}Matassi{\_}Horizontal gene transfer drives the evolution of Rh50 permeases in prokaryotes{\_}2017.pdf:pdf}, issn = {14712148}, journal = {BMC Evolutionary Biology}, keywords = {Ammonia-oxidizing bacteria,Anammox,HGT,Methanogens,Oxygen minimum zones OMZ,RH50 ammonia permeases}, month = {jan}, number = {1}, pages = {1--14}, pmid = {28049420}, publisher = {BioMed Central}, title = {{Horizontal gene transfer drives the evolution of Rh50 permeases in prokaryotes}}, volume = {17}, year = {2017} } @article{Saudemont2017, abstract = {Background: Most eukaryotic genes are subject to alternative splicing (AS), which may contribute to the production of protein variants or to the regulation of gene expression via nonsense-mediated messenger RNA (mRNA) decay (NMD). However, a fraction of splice variants might correspond to spurious transcripts and the question of the relative proportion of splicing errors to functional splice variants remains highly debated. Results: We propose a test to quantify the fraction of AS events corresponding to errors. This test is based on the fact that the fitness cost of splicing errors increases with the number of introns in a gene and with expression level. We analyzed the transcriptome of the intron-rich eukaryote Paramecium tetraurelia. We show that in both normal and in NMD-deficient cells, AS rates strongly decrease with increasing expression level and with increasing number of introns. This relationship is observed for AS events that are detectable by NMD as well as for those that are not, which invalidates the hypothesis of a link with the regulation of gene expression. Our results show that in genes with a median expression level, 92-98{\%} of observed splice variants correspond to errors. We observed the same patterns in human transcriptomes and we further show that AS rates correlate with the fitness cost of splicing errors. Conclusions: These observations indicate that genes under weaker selective pressure accumulate more maladaptive substitutions and are more prone to splicing errors. Thus, to a large extent, patterns of gene expression variants simply reflect the balance between selection, mutation, and drift.}, author = {Saudemont, Baptiste and Popa, Alexandra and Parmley, Joanna L. and Rocher, Vincent and Blugeon, Corinne and Necsulea, Anamaria and Meyer, Eric and Duret, Laurent}, doi = {10.1186/s13059-017-1344-6}, issn = {1474760X}, journal = {Genome Biology}, keywords = {Alternative splicing,Random genetic drift,Selectionist/neutralist debate}, number = {1}, pmid = {29084568}, title = {{The fitness cost of mis-splicing is the main determinant of alternative splicing patterns}}, url = {https://link.springer.com/article/10.1186/s13059-017-1344-6;}, volume = {18}, year = {2017} } @article{Venner2017, abstract = {Transposable elements (TEs) represent the single largest component of numerous eukaryotic genomes, and their activity and dispersal constitute an important force fostering evolutionary innovation. The horizontal transfer of TEs (HTT) between eukaryotic species is a common and widespread phenomenon that has had a profound impact on TE dynamics and, consequently, on the evolutionary trajectory of many species' lineages. However, the mechanisms promoting HTT remain largely unknown. In this article, we argue that network theory combined with functional ecology provides a robust conceptual framework and tools to delineate how complex interactions between diverse organisms may act in synergy to promote HTTs.}, author = {Venner, Samuel and Miele, Vincent and Terzian, Christophe and Bi{\'{e}}mont, Christian and Daubin, Vincent and Feschotte, C{\'{e}}dric and Pontier, Dominique}, doi = {10.1371/journal.pbio.2001536}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Venner et al/PLoS Biology/PLoS Biology{\_}Venner et al.{\_}Ecological networks to unravel the routes to horizontal transposon transfers{\_}2017.pdf:pdf}, issn = {15457885}, journal = {PLoS Biology}, month = {feb}, number = {2}, pmid = {28199335}, publisher = {Public Library of Science}, title = {{Ecological networks to unravel the routes to horizontal transposon transfers}}, volume = {15}, year = {2017} } @article{Bargues2017, abstract = {Background: The presence of transposable elements (TEs) in genomes is known to explain in part the variations of genome sizes among eukaryotes. Even among closely related species, the variation of TE amount may be striking, as for example between the two sibling species, Drosophila melanogaster and D. simulans. However, not much is known concerning the TE content and dynamics among other Drosophila species. The sequencing of several Drosophila genomes, covering the two subgenus Sophophora and Drosophila, revealed a large variation of the repeat content among these species but no much information is known concerning their precise TE content. The identification of some consensus sequences of TEs from the various sequenced Drosophila species allowed to get an idea concerning their variety in term of diversity of superfamilies but the used classification remains very elusive and ambiguous. Results: We choose to focus on LTR-retrotransposons because they represent the most widely represented class of TEs in the Drosophila genomes. In this work, we describe for the first time the phylogenetic relationship of each LTR-retrotransposon family described in 20 Drosophila species, compute their proportion in their respective genomes and identify several new cases of horizontal transfers. Conclusion: All these results allow us to have a clearer view on the evolutionary history of LTR retrotransposons among Drosophila that seems to be mainly driven by vertical transmissions although the implications of horizontal transfers, losses and intra-specific diversification are clearly also at play.}, author = {Bargues, Nicolas and Lerat, Emmanuelle}, doi = {10.1186/s13100-017-0090-3}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Bargues, Lerat/Mobile DNA/Mobile DNA{\_}Bargues, Lerat{\_}Evolutionary history of LTR-retrotransposons among 20 Drosophila species{\_}2017.pdf:pdf}, issn = {17598753}, journal = {Mobile DNA}, keywords = {Drosophila,Horizontal transfer,LTR-retrotransposons,Transposable element dynamics}, month = {apr}, number = {1}, publisher = {BioMed Central Ltd.}, title = {{Evolutionary history of LTR-retrotransposons among 20 Drosophila species}}, volume = {8}, year = {2017} } @article{Acuna2017, abstract = {Bubbles are pairs of internally vertex-disjoint (s, t)-paths with applications in the processing of DNA and RNA data. For example , enumerating alternative splicing events in a reference-free context can be done by enumerating all bubbles in a de Bruijn graph built from RNA-seq reads [16]. However, listing and analysing all bubbles in a given graph is usually unfeasible in practice, due to the exponential number of bubbles present in real data graphs. In this paper, we propose a notion of a bubble generator set, i.e. a polynomial-sized subset of bubbles from which all the others can be obtained through the application of a specific symmetric difference operator. This set provides a compact representation of the bubble space of a graph, which can be useful in practice since some pertinent information about all the bubbles can be more conveniently extracted from this compact set. Furthermore, we provide a polynomial-time algorithm to decompose any bubble of a graph into the bubbles of such a generator in a tree-like fashion.}, author = {Acuna, Vicente and Grossi, Roberto and Italiano, Giuseppe and Lima, Leandro and Rizzi, Romeo and Sacomoto, Gustavo and Sagot, Marie-France and Sinaimeri, Blerina and Acu{\~{n}}a, V and Grossi, R and Italiano, G F and Lima, L and Rizzi, R and Sacomoto, G and Sagot, M.-F and Sinaimeri, B}, doi = {10.1007/978-3-319-68705-6_2ï}, journal = {Springer}, keywords = {Bubble generator set,Bubble space,Bubbles,Decomposi-tion algorithm}, pages = {18--31}, title = {{On Bubble Generators in Directed Graphs. WG 2017-43rd International Workshop on Graph-Theoretic Concepts in Computer Science}}, url = {https://hal.inria.fr/hal-01647516}, year = {2017} } @article{Galia2017a, abstract = {Background: Enterohemorrhagic Escherichia coli (EHEC) are zoonotic agents associated with outbreaks worldwide. Growth of EHEC strains in ground beef could be inhibited by background microbiota that is present initially at levels greater than that of the pathogen E. coli. However, how the microbiota outcompetes the pathogenic bacteria is unknown. Our objective was to identify metabolic pathways of EHEC that were altered by natural microbiota in order to improve our understanding of the mechanisms controlling the growth and survival of EHECs in ground beef. Results: Based on 16S metagenomics analysis, we identified the microbial community structure in our beef samples which was an essential preliminary for subtractively analyzing the gene expression of the EHEC strains. Then, we applied strand-specific RNA-seq to investigate the effects of this microbiota on the global gene expression of EHEC O2621765 and O157EDL933 strains by comparison with their behavior in beef meat without microbiota. In strain O2621765, the expression of genes connected with nitrate metabolism and nitrite detoxification, DNA repair, iron and nickel acquisition and carbohydrate metabolism, and numerous genes involved in amino acid metabolism were down-regulated. Further, the observed repression of ftsL and murF, involved respectively in building the cytokinetic ring apparatus and in synthesizing the cytoplasmic precursor of cell wall peptidoglycan, might help to explain the microbiota's inhibitory effect on EHECs. For strain O157EDL933, the induced expression of the genes implicated in detoxification and the general stress response and the repressed expression of the peR gene, a gene negatively associated with the virulence phenotype, might be linked to the survival and virulence of O157:H7 in ground beef with microbiota. Conclusion: In the present study, we show how RNA-Seq coupled with a 16S metagenomics analysis can be used to identify the effects of a complex microbial community on relevant functions of an individual microbe within it. These findings add to our understanding of the behavior of EHECs in ground beef. By measuring transcriptional responses of EHEC, we could identify putative targets which may be useful to develop new strategies to limit their shedding in ground meat thus reducing the risk of human illnesses.}, author = {Galia, Wessam and Leriche, Francoise and Cruveiller, St{\'{e}}phane and Garnier, Cindy and Navratil, Vincent and Dubost, Audrey and Blanquet-Diot, St{\'{e}}phanie and Thevenot-Sergentet, Delphine}, doi = {10.1186/s12864-017-3957-2}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Galia et al/BMC Genomics/BMC Genomics{\_}Galia et al.{\_}Strand-specific transcriptomes of Enterohemorrhagic Escherichia coli in response to interactions with groun(2).pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {16S metagenomics analysis,EHEC,Ground beef,Natural microbiota,RNA-Seq}, month = {aug}, number = {1}, pmid = {28774270}, publisher = {BioMed Central Ltd.}, title = {{Strand-specific transcriptomes of Enterohemorrhagic Escherichia coli in response to interactions with ground beef microbiota: Interactions between microorganisms in raw meat}}, volume = {18}, year = {2017} } @article{Lima2017, abstract = {Background: The main challenge in de novo genome assembly of DNA-seq data is certainly to deal with repeats that are longer than the reads. In de novo transcriptome assembly of RNA-seq reads, on the other hand, this problem has been underestimated so far. Even though we have fewer and shorter repeated sequences in transcriptomics, they do create ambiguities and confuse assemblers if not addressed properly. Most transcriptome assemblers of short reads are based on de Bruijn graphs (DBG) and have no clear and explicit model for repeats in RNA-seq data, relying instead on heuristics to deal with them. Results: The results of this work are threefold. First, we introduce a formal model for representing high copy-number and low-divergence repeats in RNA-seq data and exploit its properties to infer a combinatorial characteristic of repeat-associated subgraphs. We show that the problem of identifying such subgraphs in a DBG is NP-complete. Second, we show that in the specific case of local assembly of alternative splicing (AS) events, we can implicitly avoid such subgraphs, and we present an efficient algorithm to enumerate AS events that are not included in repeats. Using simulated data, we show that this strategy is significantly more sensitive and precise than the previous version of KisSplice (Sacomoto et al. in WABI, pp 99-111, 1), Trinity (Grabherr et al. in Nat Biotechnol 29(7):644-652, 2), and Oases (Schulz et al. in Bioinformatics 28(8):1086-1092, 3), for the specific task of calling AS events. Third, we turn our focus to full-length transcriptome assembly, and we show that exploring the topology of DBGs can improve de novo transcriptome evaluation methods. Based on the observation that repeats create complicated regions in a DBG, and when assemblers try to traverse these regions, they can infer erroneous transcripts, we propose a measure to flag transcripts traversing such troublesome regions, thereby giving a confidence level for each transcript. The originality of our work when compared to other transcriptome evaluation methods is that we use only the topology of the DBG, and not read nor coverage information. We show that our simple method gives better results than Rsem-Eval (Li et al. in Genome Biol 15(12):553, 4) and TransRate (Smith-Unna et al. in Genome Res 26(8):1134-1144, 5) on both real and simulated datasets for detecting chimeras, and therefore is able to capture assembly errors missed by these methods.}, author = {Lima, Leandro and Sinaimeri, Blerina and Sacomoto, Gustavo and Lopez-Maestre, Helene and Marchet, Camille and Miele, Vincent and Sagot, Marie France and Lacroix, Vincent}, doi = {10.1186/s13015-017-0091-2}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Lima et al/Algorithms for Molecular Biology/Algorithms for Molecular Biology{\_}Lima et al.{\_}Playing hide and seek with repeats in local and global de novo transcriptome assembly of sh.pdf:pdf}, issn = {17487188}, journal = {Algorithms for Molecular Biology}, keywords = {Alternative splicing,Assembly evaluation,De Bruijn graph topology,Enumeration algorithm,Formal model for representing repeats,RNA-seq,Repeats,Transcriptome assembly}, month = {feb}, number = {1}, publisher = {BioMed Central Ltd.}, title = {{Playing hide and seek with repeats in local and global de novo transcriptome assembly of short RNA-seq reads}}, volume = {12}, year = {2017} } @article{Lerat2017, abstract = {Over recent decades, substantial efforts have been made to understand the interactions between host genomes and transposable elements (TEs). The impact of TEs on the regulation of host genes is well known, with TEs acting as platforms of regulatory sequences. Nevertheless, due to their repetitive nature it is considerably hard to integrate TE analysis into genome-wide studies. Here, we developed a specific tool for the analysis of TE expression: TEtools. This tool takes into account the TE sequence diversity of the genome, it can be applied to unannotated or unassembled genomes and is freely available under the GPL3 (https://github.com/l-modolo/TEtools). TEtools performs the mapping of RNA-seq data obtained from classical mRNAs or small RNAs onto a list of TE sequences and performs differential expression analyses with statistical relevance. Using this tool, we analyzed TE expression from five Drosophila wild-type strains. Our data show for the first time that the activity of TEs is strictly linked to the activity of the genes implicated in the piwi-interacting RNA biogenesis and therefore fits an arms race scenario between TE sequences and host control genes.}, author = {Lerat, Emmanuelle and Fablet, Marie and Modolo, Laurent and Lopez-Maestre, H{\'{e}}l{\`{e}}ne and Vieira, Cristina}, doi = {10.1093/nar/gkw953}, issn = {13624962}, journal = {Nucleic acids research}, number = {4}, pages = {e17}, pmid = {28204592}, title = {{TEtools facilitates big data expression analysis of transposable elements and reveals an antagonism between their activity and that of piRNA genes}}, url = {https://academic.oup.com/nar/article-abstract/45/4/e17/2290912}, volume = {45}, year = {2017} } @article{Goubert2017, abstract = {Invasive species represent unique opportunities to evaluate the role of local adaptation during colonization of new environments. Among these species, the Asian tiger mosquito, Aedes albopictus, is a threatening vector of several human viral diseases, including dengue and chikungunya, and raises concerns about the Zika fever. Its broad presence in both temperate and tropical environments has been considered the reflection of great “ecological plasticity.” However, no study has been conducted to assess the role of adaptive evolution in the ecological success of Ae. albopictus at the molecular level. In the present study, we performed a genomic scan to search for potential signatures of selection leading to local adaptation in one-hundred-forty field-collected mosquitoes from native populations of Vietnam and temperate invasive populations of Europe. High-throughput genotyping of transposable element insertions led to the discovery of more than 120,000 polymorphic loci, which, in their great majority, revealed a virtual absence of structure between the biogeographic areas. Nevertheless, 92 outlier loci showed a high level of differentiation between temperate and tropical populations. The majority of these loci segregate at high insertion frequencies among European populations, indicating that this pattern could have been caused by recent adaptive evolution events in temperate areas. An analysis of the overlapping and neighbouring genes highlighted several candidates, including diapause, lipid and juvenile hormone pathways.}, author = {Goubert, Clement and Henri, Helene and Minard, Guillaume and {Valiente Moro}, Claire and Mavingui, Patrick and Vieira, Cristina and Boulesteix, Matthieu}, doi = {10.1111/mec.14184}, issn = {1365294X}, journal = {Molecular Ecology}, keywords = {Aedes albopictus,genome scan,invasive species,local adaptation,transposable elements}, number = {15}, pages = {3968--3981}, pmid = {28517033}, title = {{High-throughput sequencing of transposable element insertions suggests adaptive evolution of the invasive Asian tiger mosquito towards temperate environments}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/mec.14184}, volume = {26}, year = {2017} } @article{Duchemin2017, abstract = {DeCoSTAR is a software that aims at reconstructing the organization of ancestral genes or genomes in the form of sets of neighborhood relations (adjacencies) between pairs of ancestral genes or gene domains. It can also improve the assembly of fragmented genomes by proposing evolutionary-induced adjacencies between scaffolding fragments. Ancestral genes or domains are deduced from reconciled phylogenetic trees under an evolutionarymodel that considers gains, losses, speciations, duplications, and transfers as possible events for gene evolution. Reconciliations are either given as input or computed with the ecceTERA package, into which DeCoSTAR is integrated. DeCoSTAR computes adjacency evolutionary scenarios using a scoring scheme based on aweighted sum of adjacency gains and breakages. Solutions, both optimal and near-optimal, are sampled according to the Boltzmann-Gibbs distribution centered around parsimonious solutions, and statistical supports on ancestral and extant adjacencies are provided.DeCoSTAR supports the features of previously contributed tools that reconstruct ancestral adjacencies, namely DeCo, DeCoLT, ART-DeCo, and DeClone. In a fewminutes, DeCoSTAR can reconstruct the evolutionary history of domains inside genes, of gene fusion and fission events, or of gene order along chromosomes, for large data sets including dozens of whole genomes from all kingdoms of life. We illustrate the potential of DeCoSTAR with several applications: ancestral reconstruction of gene orders for Anopheles mosquito genomes, multidomain proteins in Drosophila, and gene fusion and fission detection in Actinobacteria.}, author = {Duchemin, Wandrille and Anselmetti, Yoann and Patterson, Murray and Ponty, Yann and B{\'{e}}rard, S{\`{e}}verine and Chauve, Cedric and Scornavacca, Celine and Daubin, Vincent and Tannier, Eric}, doi = {10.1093/gbe/evx069}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Evolution,Gene fusion/fission,Gene order,Protein domain,Rearrangements,Reconciliation,Software}, number = {5}, pages = {1312--1319}, pmid = {28402423}, title = {{DeCoSTAR: Reconstructing the ancestral organization of genes or genomes using reconciled phylogenies}}, url = {https://academic.oup.com/gbe/article-abstract/9/5/1312/3200386}, volume = {9}, year = {2017} } @inproceedings{Acuna2017a, abstract = {Bubbles are pairs of internally vertex-disjoint (s, t)-paths with applications in the processing of DNA and RNA data. For example, enumerating alternative splicing events in a reference-free context can be done by enumerating all bubbles in a de Bruijn graph built from RNA-seq reads [16]. However, listing and analysing all bubbles in a given graph is usually unfeasible in practice, due to the exponential number of bubbles present in real data graphs. In this paper, we propose a notion of a bubble generator set, i.e. a polynomial-sized subset of bubbles from which all the others can be obtained through the application of a specific symmetric difference operator. This set provides a compact representation of the bubble space of a graph, which can be useful in practice since some pertinent information about all the bubbles can be more conveniently extracted from this compact set. Furthermore, we provide a polynomial-time algorithm to decompose any bubble of a graph into the bubbles of such a generator in a tree-like fashion.}, author = {Acu{\~{n}}a, Vicente and Grossi, Roberto and Italiano, Giuseppe F. and Lima, Leandro and Rizzi, Romeo and Sacomoto, Gustavo and Sagot, Marie France and Sinaimeri, Blerina}, booktitle = {Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)}, doi = {10.1007/978-3-319-68705-6_2}, isbn = {9783319687049}, issn = {16113349}, keywords = {Bubble generator set,Bubble space,Bubbles,Decomposition algorithm}, pages = {18--31}, publisher = {Springer Verlag}, title = {{On bubble generators in directed graphs}}, volume = {10520 LNCS}, year = {2017} } @article{Duret2017, abstract = {The spread of maternally inherited microorganisms, such as Wolbachia bacteria , can induce indirect selective sweeps on host mitochondria, to which they are linked within the cytoplasm. The resulting reduction in effective population size might lead to smaller mitochondrial diversity and reduced efficiency of natural selection. While documented in several host species, it is currently unclear if such a scenario is common enough to globally impact the diversity and evolution of mitochondria in Wolbachia-infected lineages. Here, we address this question using a mapping of Wolbachia acquisition/ex-tinction events on a large mitochondrial DNA tree, including over 1000 species. Our analyses indicate that on a large phylogenetic scale, other sources of variation, such as mutation rates, tend to hide the effects of Wolbachia. However, paired comparisons between closely related infected and unin-fected taxa reveal that Wolbachia is associated with a twofold reduction in silent mitochondrial polymorphism, and a 13{\%} increase in nonsynonymous substitution rates. These findings validate the conjecture that the widespread distribution of Wolbachia infections throughout arthropods impacts the effective population size of mitochondria. These effects might in part explain the disconnection between genetic diversity and demographic population size in mitochondria, and also fuel red-queen-like cytonuclear co-evolution through the fixation of deleterious mitochondrial alleles.}, author = {Duret, L and Charlat, S}, doi = {10.1111/jeb.13186}, journal = {Wiley Online Library}, keywords = {Wolbachia,effective population size,genetic diversity,mitochondria,selective sweep}, month = {dec}, number = {12}, pages = {2204--2210}, publisher = {Blackwell Publishing Ltd}, title = {{The global impact of Wolbachia on mitochondrial diversity and evolution}}, url = {https://onlinelibrary.wiley.com/doi/abs/10.1111/jeb.13186}, volume = {30}, year = {2017} } @article{Philippon2017, abstract = {The reliability of molecular phylogenies is strongly dependent on the quality of the assembled datasets. In the case of eukaryotes, the selection of only one protein isoform per genomic locus is mandatory to avoid biases linked to redundancy. Here, we present IsoSel, a tool devoted to the selection of alternative isoforms in the context of phylogenetic reconstruction. It provides a better alternative to the widely used approach consisting in the selection of the longest isoforms and it performs better than Guidance, its only available counterpart. IsoSel is publicly available at http://doua.prabi.fr/software/isosel.}, author = {Philippon, H{\'{e}}lo{\"{i}}se and Souvane, Alexia and Brochier-Armanet, C{\'{e}}line and Perri{\`{e}}re, Guy}, doi = {10.1371/journal.pone.0174250}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Philippon et al/PLoS ONE/PLoS ONE{\_}Philippon et al.{\_}IsoSel Protein isoform selector for phylogenetic reconstructions{\_}2017.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, month = {mar}, number = {3}, pmid = {28323858}, publisher = {Public Library of Science}, title = {{IsoSel: Protein isoform selector for phylogenetic reconstructions}}, volume = {12}, year = {2017} } @techreport{Schbath2017, author = {Schbath, Sophie and Mariadassou, Mahendra and Lao, Julie}, booktitle = {hal.archives-ouvertes.fr}, pages = {234}, title = {{Comparison of statistical methods of inference of cooccurrence networks within micro-bial ecosystems from metagenomics data}}, url = {https://hal.archives-ouvertes.fr/hal-01563604}, year = {2017} } @article{Faucon2017, abstract = {Background: The capacity of Aedes mosquitoes to resist chemical insecticides threatens the control of major arbovirus diseases worldwide. Until alternative control tools are widely deployed, monitoring insecticide resistance levels and identifying resistance mechanisms in field mosquito populations is crucial for implementing appropriate management strategies. Metabolic resistance to pyrethroids is common in Aedes aegypti but the monitoring of the dynamics of resistant alleles is impeded by the lack of robust genomic markers. Methodology/Principal findings: In an attempt to identify the genomic bases of metabolic resistance to deltamethrin, multiple resistant and susceptible populations originating from various continents were compared using both RNA-seq and a targeted DNA-seq approach focused on the upstream regions of detoxification genes. Multiple detoxification enzymes were over transcribed in resistant populations, frequently associated with an increase in their gene copy number. Targeted sequencing identified potential promoter variations associated with their over transcription. Non-synonymous variations affecting detoxification enzymes were also identified in resistant populations. Conclusion /Significance: This study not only confirmed the role of gene copy number variations as a frequent cause of the over expression of detoxification enzymes associated with insecticide resistance in Aedes aegypti but also identified novel genomic resistance markers potentially associated with their cis-regulation and modifications of their protein structure conformation. As for gene transcription data, polymorphism patterns were frequently conserved within regions but differed among continents confirming the selection of different resistance factors worldwide. Overall, this study paves the way of the identification of a comprehensive set of genomic markers for monitoring the spatio-temporal dynamics of the variety of insecticide resistance mechanisms in Aedes aegypti.}, author = {Faucon, Frederic and Gaude, Thierry and Dusfour, Isabelle and Navratil, Vincent and Corbel, Vincent and Juntarajumnong, Waraporn and Girod, Romain and Poupardin, Rodolphe and Boyer, Frederic and Reynaud, Stephane and David, Jean Philippe}, doi = {10.1371/journal.pntd.0005526}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Faucon et al/PLoS Neglected Tropical Diseases/PLoS Neglected Tropical Diseases{\_}Faucon et al.{\_}In the hunt for genomic markers of metabolic resistance to pyrethroids in the mosquito Ae.pdf:pdf}, issn = {19352735}, journal = {PLoS Neglected Tropical Diseases}, month = {apr}, number = {4}, pmid = {28379969}, publisher = {Public Library of Science}, title = {{In the hunt for genomic markers of metabolic resistance to pyrethroids in the mosquito Aedes aegypti: An integrated next-generation sequencing approach}}, volume = {11}, year = {2017} } @article{Galia2017, abstract = {Background: Enterohemorrhagic Escherichia coli (EHEC) are zoonotic agents associated with outbreaks worldwide. Growth of EHEC strains in ground beef could be inhibited by background microbiota that is present initially at levels greater than that of the pathogen E. coli. However, how the microbiota outcompetes the pathogenic bacteria is unknown. Our objective was to identify metabolic pathways of EHEC that were altered by natural microbiota in order to improve our understanding of the mechanisms controlling the growth and survival of EHECs in ground beef. Results: Based on 16S metagenomics analysis, we identified the microbial community structure in our beef samples which was an essential preliminary for subtractively analyzing the gene expression of the EHEC strains. Then, we applied strand-specific RNA-seq to investigate the effects of this microbiota on the global gene expression of EHEC O2621765 and O157EDL933 strains by comparison with their behavior in beef meat without microbiota. In strain O2621765, the expression of genes connected with nitrate metabolism and nitrite detoxification, DNA repair, iron and nickel acquisition and carbohydrate metabolism, and numerous genes involved in amino acid metabolism were down-regulated. Further, the observed repression of ftsL and murF, involved respectively in building the cytokinetic ring apparatus and in synthesizing the cytoplasmic precursor of cell wall peptidoglycan, might help to explain the microbiota's inhibitory effect on EHECs. For strain O157EDL933, the induced expression of the genes implicated in detoxification and the general stress response and the repressed expression of the peR gene, a gene negatively associated with the virulence phenotype, might be linked to the survival and virulence of O157:H7 in ground beef with microbiota. Conclusion: In the present study, we show how RNA-Seq coupled with a 16S metagenomics analysis can be used to identify the effects of a complex microbial community on relevant functions of an individual microbe within it. These findings add to our understanding of the behavior of EHECs in ground beef. By measuring transcriptional responses of EHEC, we could identify putative targets which may be useful to develop new strategies to limit their shedding in ground meat thus reducing the risk of human illnesses.}, author = {Galia, Wessam and Leriche, Francoise and Cruveiller, St{\'{e}}phane and Garnier, Cindy and Navratil, Vincent and Dubost, Audrey and Blanquet-Diot, St{\'{e}}phanie and Thevenot-Sergentet, Delphine}, doi = {10.1186/s12864-017-3957-2}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Galia et al/BMC Genomics/BMC Genomics{\_}Galia et al.{\_}Strand-specific transcriptomes of Enterohemorrhagic Escherichia coli in response to interactions with ground b.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {16S metagenomics analysis,EHEC,Ground beef,Natural microbiota,RNA-Seq}, month = {aug}, number = {1}, pmid = {28774270}, publisher = {BioMed Central Ltd.}, title = {{Strand-specific transcriptomes of Enterohemorrhagic Escherichia coli in response to interactions with ground beef microbiota: Interactions between microorganisms in raw meat}}, volume = {18}, year = {2017} } @article{Lassalle2017, abstract = {Horizontal gene transfer (HGT) is considered as a major source of innovation in bacteria, and as such is expected to drive adaptation to new ecological niches. However, among the many genes acquired through HGT along the diversification history of genomes, only a fraction may have actively contributed to sustained ecological adaptation. We used a phylogenetic approach accounting for the transfer of genes (or groups of genes) to estimate the history of genomes in Agrobacterium biovar 1, a diverse group of soil and plant-dwelling bacterial species. We identified clade-specific blocks of cotransferred genes encoding coherent biochemical pathways that may have contributed to the evolutionary success of key Agrobacterium clades. This pattern of gene coevolution rejects a neutral model of transfer, in which neighboring genes would be transferred independently of their function and rather suggests purifying selection on collectively coded acquired pathways. The acquisition of these synapomorphic blocks of cofunctioning genes probably drove the ecological diversification of Agrobacterium and defined features of ancestral ecological niches, which consistently hint at a strong selective role of host plant rhizospheres.}, author = {Lassalle, Florent and Planel, R{\'{e}}mi and Penel, Simon and Chapulliot, David and Barbe, Val{\'{e}}rie and Dubost, Audrey and Calteau, Alexandra and Vallenet, David and Mornico, Damien and Bigot, Thomas and Gu{\'{e}}guen, Laurent and Vial, Ludovic and Muller, Daniel and Daubin, Vincent and Nesme, Xavier}, doi = {10.1093/gbe/evx255}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Lassalle et al/Genome Biology and Evolution/Genome Biology and Evolution{\_}Lassalle et al.{\_}Ancestral Genome Estimation Reveals the History of Ecological Diversification in Agrobacter.pdf:pdf}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Agrobacterium tumefaciens,HGT,ancestral genome,cotransferred genes,reverse ecology,tree reconciliation}, month = {dec}, number = {12}, pages = {3413--3431}, pmid = {29220487}, publisher = {Oxford University Press}, title = {{Ancestral Genome Estimation Reveals the History of Ecological Diversification in Agrobacterium}}, volume = {9}, year = {2017} } @article{Oger2017, abstract = {Members of the order Thermococcales are common inhabitants of hightemperature hydrothermal vent systems (black smokers) that are represented in clone libraries mostly by isolates from the Thermococcus genus. We report the complete sequence of a novel species from the Pyrococcus genus, P. kukulkanii strain NCB100, which has been isolated from a flange fragment of the Rebecca's Roost hydrothermal vent system in the Guaymas Basin.}, author = {Oger, Philippe M. and Callac, Nolwenn and Oger-Desfeux, Christine and Hughes, Sandrine and Gillet, Benjamin and Jebbar, Mohamed and Godfroy, Anne}, doi = {10.1128/genomeA.01667-16}, file = {:Users/navratil/Documents/Mendeley Desktop/2017/Oger et al/Genome Announcements/Genome Announcements{\_}Oger et al.{\_}Complete genome sequence of the hyperthermophilic piezophilic archaeon Pyrococcus kukulkanii NCB100 iso.pdf:pdf}, issn = {21698287}, journal = {Genome Announcements}, number = {7}, publisher = {American Society for Microbiology}, title = {{Complete genome sequence of the hyperthermophilic piezophilic archaeon Pyrococcus kukulkanii NCB100 isolated from the Rebecca's Roost hydrothermal vent in the Guaymas Basin}}, volume = {5}, year = {2017} } @article{Larroque2016, abstract = {Maintenance of genetic variation is of critical importance for wild populations since low levels limit the species' ability to respond to different threats (diseases, predators, environmental changes) in both the long and the short term. Human activities could impact the genetic variation of wild species in multiple ways, including via fragmentation and harvesting. We used an individual-based landscape genetics approach to describe the impact of landscape elements and trapping pressure on the spatial genetic structure of a large sample (n = 370) of the stone marten (Martes foina) in central-eastern France (Bresse). An analysis of isolation-by-resistance using a causal modeling approach showed an influence of landscape cover and/or trapping pressure on gene flow according to age and sex class. Overall, the connectivity in the study area is provided mainly by vegetation cover, while roads and open areas partially impede it. Unexpectedly for this “urban adapter” species, buildings could reduce gene flow. We also emphasized the sex-dependent effect of trapping on gene flow. Genetic differentiation in males was influenced by trapping pressure and landscape structure while only the latter influenced genetic differentiation in females. A stronger isolation by distance in males than in females suggested that at the scale of the study area, males are more exposed to trapping pressure, which reduces effective dispersal. Overall, the combination of both landscape and trapping costs might create an ‘ecological trap' that could disrupt gene flow, leading to a north–south division in the study area.}, author = {Larroque, Jeremy and Ruette, Sandrine and Vandel, Jean Michel and Queney, Guillaume and Devillard, S{\'{e}}bastien}, doi = {10.1007/s10592-016-0862-1}, issn = {15729737}, journal = {Conservation Genetics}, keywords = {Genetic variability,Individual-based landscape genetics,Isolation by distance,Isolation by resistance,Martes foina,Stone marten}, number = {6}, pages = {1293--1306}, title = {{Age and sex-dependent effects of landscape cover and trapping on the spatial genetic structure of the stone marten (Martes foina)}}, url = {https://link.springer.com/article/10.1007/s10592-016-0862-1}, volume = {17}, year = {2016} } @article{Lopez-Maestre2016, abstract = {SNPs (Single Nucleotide Polymorphisms) are genetic markers whose precise identification is a prerequisite for association studies. Methods to identify them are currently well developed for model species, but rely on the availability of a (good) reference genome, and therefore cannot be applied to non-model species. They are also mostly tailored for whole genome (re-)sequencing experiments, whereas in many cases, transcriptome sequencing can be used as a cheaper alternative which already enables to identify SNPs located in transcribed regions. In this paper, we propose a method that identifies, quantifies and annotates SNPs without any reference genome, using RNA-seq data only. Individuals can be pooled prior to sequencing, if not enough material is available from one individual. Using pooled human RNA-seq data, we clarify the precision and recall of our method and discuss them with respect to other methods which use a reference genome or an assembled transcriptome. We then validate experimentally the predictions of our method using RNA-seq data from two non-model species. The method can be used for any species to annotate SNPs and predict their impact on the protein sequence. We further enable to test for the association of the identified SNPs with a phenotype of interest.}, author = {Lopez-Maestre, H{\'{e}}l{\`{e}}ne and Brinza, Lilia and Marchet, Camille and Kielbassa, Janice and Bastien, Sylv{\`{e}}re and Boutigny, Mathilde and Monnin, David and Filali, Adil El and Carareto, Claudia Marcia and Vieira, Cristina and Picard, Franck and Kremer, Natacha and Vavre, Fabrice and Sagot, Marie France and Lacroix, Vincent}, doi = {10.1093/nar/gkw655}, issn = {13624962}, journal = {Nucleic Acids Research}, number = {19}, pmid = {27458203}, title = {{SNP calling from RNA-seq data without a reference genome: Identification, quantification, differential analysis and impact on the protein sequence}}, url = {https://academic.oup.com/nar/article-abstract/44/19/e148/2468394}, volume = {44}, year = {2016} } @article{Kefi2016, abstract = {Species are linked to each other by a myriad of positive and negative interactions. This complex spectrum of interactions constitutes a network of links that mediates ecological communities' response to perturbations, such as exploitation and climate change. In the last decades, there have been great advances in the study of intricate ecological networks. We have, nonetheless, lacked both the data and the tools to more rigorously understand the patterning of multiple interaction types between species (i.e., “multiplex networks”), as well as their consequences for community dynamics. Using network statistical modeling applied to a comprehensive ecological network, which includes trophic and diverse non-trophic links, we provide a first glimpse at what the full “entangled bank” of species looks like. The community exhibits clear multidimensional structure, which is taxonomically coherent and broadly predictable from species traits. Moreover, dynamic simulations suggest that this non-random patterning of how diverse non-trophic interactions map onto the food web could allow for higher species persistence and higher total biomass than expected by chance and tends to promote a higher robustness to extinctions.}, author = {K{\'{e}}fi, Sonia and Miele, Vincent and Wieters, Evie A. and Navarrete, Sergio A. and Berlow, Eric L.}, doi = {10.1371/journal.pbio.1002527}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/K{\'{e}}fi et al/PLoS Biology/PLoS Biology{\_}K{\'{e}}fi et al.{\_}How Structured Is the Entangled Bank The Surprisingly Simple Organization of Multiplex Ecological Networks Lea.pdf:pdf}, issn = {15457885}, journal = {PLoS Biology}, month = {aug}, number = {8}, pmid = {27487303}, publisher = {Public Library of Science}, title = {{How Structured Is the Entangled Bank? The Surprisingly Simple Organization of Multiplex Ecological Networks Leads to Increased Persistence and Resilience}}, volume = {14}, year = {2016} } @article{Roussel2016, abstract = {Background: Improving knowledge about influenza transmission is crucial to upgrade surveillance network and to develop accurate predicting models to enhance public health intervention strategies. Epidemics usually occur in winter in temperate countries and during the rainy season for tropical countries, suggesting a climate impact on influenza spread. Despite a lot of studies, the role of weather on influenza spread is not yet fully understood. In the present study, we investigated this issue at two different levels. Methods: First, we evaluated how weekly (intra-annual) incidence variations of clinical diseases could be linked to those of climatic factors. We considered that only a fraction of the human population is susceptible at the beginning of a year due to immunity acquired from previous years. Second, we focused on epidemic sizes (cumulated number of clinical reported cases) and looked at how their inter-annual and regional variations could be related to differences in the winter climatic conditions of the epidemic years over the regions. We quantified the impact of fifteen climatic variables in France using the R{\'{e}}seau des GROG surveillance network incidence data over eleven regions and nine years. Results: At the epidemic scale, no impact of climatic factors was highlighted. At the intra-annual scale, six climatic variables had a significant impact: average temperature (5.54 ± 1.09 {\%}), absolute humidity (5.94 ± 1.08 {\%}), daily variation of absolute humidity (3.02 ± 1.17 {\%}), sunshine duration (3.46 ± 1.06 {\%}), relative humidity (4.92 ± 1.20 {\%}) and daily variation of relative humidity (4.46 ± 1.24 {\%}). Since in practice the impact of two highly correlated variables is very hard to disentangle, we performed a principal component analysis that revealed two groups of three highly correlated climatic variables: one including the first three highlighted climatic variables on the one hand, the other including the last three ones on the other hand. Conclusions: These results suggest that, among the six factors that appeared to be significant, only two (one per group) could in fact have a real effect on influenza spread, although it is not possible to determine which one based on a purely statistical argument. Our results support the idea of an important role of climate on the spread of influenza.}, author = {Roussel, Marion and Pontier, Dominique and Cohen, Jean Marie and Lina, Bruno and Fouchet, David}, doi = {10.1186/s12889-016-3114-x}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Roussel et al/BMC Public Health/BMC Public Health{\_}Roussel et al.{\_}Quantifying the role of weather on seasonal influenza{\_}2016(2).pdf:pdf}, issn = {14712458}, journal = {BMC Public Health}, month = {may}, number = {1}, pmid = {27230111}, publisher = {BioMed Central Ltd.}, title = {{Quantifying the role of weather on seasonal influenza}}, volume = {16}, year = {2016} } @article{Cassan2016, abstract = {To cite this version: Elodie Cassan. Bioinformatique des g{\`{e}}nes chevauchants; application {\`{a}} la prot{\'{e}}ine antisens ASP du VIH-1. M{\'{e}}decine humaine et pathologie. Universit{\'{e}} Montpellier, 2016. Fran{\c{c}}ais. {\"{i}}¿¿NNT : 2016MONTT068{\"{i}}¿¿. {\"{i}}¿¿tel-01556634{\"{i}}¿¿}, author = {Cassan, Elodie}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Cassan/Unknown/Unknown{\_}Cassan{\_}Bioinformatique des g{\`{e}}nes chevauchants application {\`{a}} la prot{\'{e}}ine antisens ASP du VIH-1{\_}2016.pdf:pdf}, pages = {204}, title = {{Bioinformatique des g{\`{e}}nes chevauchants; application {\`{a}} la prot{\'{e}}ine antisens ASP du VIH-1}}, url = {https://tel.archives-ouvertes.fr/tel-01556634 files/4016/Cassan - Bioinformatique des g{\`{e}}nes chevauchants{\%}0Aapplicatio.pdf}, year = {2016} } @article{Julien-Laferriere2016, author = {Julien-Laferri{\`{e}}re, A and Bulteau, L and {\ldots}, D Parrot - JOURN{\'{E}}ES}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Julien-Laferri{\`{e}}re, Bulteau, {\ldots}/jobim2016.sciencesconf.org/jobim2016.sciencesconf.org{\_}Julien-Laferri{\`{e}}re, Bulteau, {\ldots}{\_}JOURN{\'{E}}ES OUVERTES DE BIOLOGIE INFORMATIQUE {\&} MATH{\'{E}}MATIQUES{\_}2016.pdf:pdf}, journal = {jobim2016.sciencesconf.org}, title = {{JOURN{\'{E}}ES OUVERTES DE BIOLOGIE INFORMATIQUE {\&} MATH{\'{E}}MATIQUES}}, url = {http://jobim2016.sciencesconf.org/resource/sponsors}, year = {2016} } @article{Viallon2016, abstract = {Using networks as prior knowledge to guide model selection is a way to reach structured sparsity. In particular , the fused lasso that was originally designed to penalize differences of coefficients corresponding to successive features has been generalized to handle features whose effects are structured according to a given network. As any prior information, the network provided in the penalty may contain misleading edges that connect coefficients whose difference is not zero, and the extent to which the performance of the method depend on the suitability of the graph has never been clearly assessed. In this work we investigate the theoretical and empirical properties of the adaptive generalized fused lasso in the context of generalized linear models. In the fixed p setting, we show that, asymptotically, adding misleading edges in the graph does not prevent the adap-tive generalized fused lasso from enjoying asymptotic oracle properties, while forgetting suitable edges can be more problematic. These theoretical results are complemented by an extensive simulation study that assesses the robustness of the adaptive generalized fused lasso against misspecification of the network as well as its applicability when theoretical coefficients are not exactly equal. Our contribution is also to evaluate the applicability of the generalized fused lasso for the joint modeling of multiple sparse regression functions. Illustrations are provided on two real data examples.}, author = {Viallon, Vivian and Lambert-Lacroix, Sophie and H{\"{o}}fling, Holger and Picard, Franck and Hoefling, H{\"{o}}lger and Viallon, V and Lambert-Lacroix, S and {Hoefling Novartis Pharma}, H and Picard, Switzerland F}, doi = {10.1007/s11222-014-9497-6ï}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Viallon et al/Springer/Springer{\_}Viallon et al.{\_}On the robustness of the generalized fused lasso to prior specifications{\_}2016.pdf:pdf}, journal = {Springer}, keywords = {generalized linear models,joint modeling,lasso,model selection}, number = {1}, title = {{On the robustness of the generalized fused lasso to prior specifications}}, url = {https://hal.archives-ouvertes.fr/hal-01067903v2}, volume = {26}, year = {2016} } @techreport{Benoit-pilven2016, author = {Benoit-pilven, Clara}, title = {{Analyse de l'{\'{e}}pissage alternatif dans les donn{\'{e}}es RNAseq: d{\'{e}}veloppement et comparaison d'outils bioinformatiques}}, url = {https://tel.archives-ouvertes.fr/tel-01493669}, year = {2016} } @article{Pouyet2016, abstract = {Gene sequences are the target of evolution operating at different levels, including the nucleotide, codon, and amino acid levels. Disentangling the impact of those different levels on gene sequences requires developing a probabilistic model with three layers. Here we present SENCA (site evolution of nucleotides, codons, and amino acids), a codon substitution model that separately describes 1) nucleotide processes which apply on all sites of a sequence such as the mutational bias, 2) preferences between synonymous codons, and 3) preferences among amino acids. We argue that most synonymous substitutions are not neutral and that SENCA provides more accurate estimates of selection compared with more classical codon sequence models. We study the forces that drive the genomic content evolution, intraspecifically in the core genome of 21 prokaryotes and interspecifically for five Enterobacteria. We retrieve the existence of a universal mutational bias toward AT, and that taking into account selection on synonymous codon usage has consequences on the measurement of selection on nonsynonymous substitutions. We also confirm that codon usage bias is mostly driven by selection on preferred codons. We propose new summary statistics to measure the relative importance of the different evolutionary processes acting on sequences.}, author = {Pouyet, Fanny and Bailly-Bechet, Marc and Mouchiroud, Dominique and Gu{\'{e}}guen, Laurent}, doi = {10.1093/gbe/evw165}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Codon usage bias,Evolutionary codon model,Nonstationary homogeneous model}, number = {8}, pages = {2427--2441}, pmid = {27401173}, title = {{SENCA: A multilayered codon model to study the origins and dynamics of codon usage}}, url = {https://academic.oup.com/gbe/article-abstract/8/8/2427/2198174}, volume = {8}, year = {2016} } @techreport{Pouyet2016a, abstract = {To cite this version: Fanny Pouyet. {\'{E}}tude bioinformatique de l'{\'{e}}volution de l'usage du code g{\'{e}}n{\'{e}}tique. G{\'{e}}n{\'{e}}tique humaine. Universit{\'{e}} de Lyon, 2016. Fran{\c{c}}ais. {\"{i}}¿¿NNT : 2016LYSE1140{\"{i}}¿¿. {\"{i}}¿¿tel-01410446{\"{i}}¿¿}, author = {Pouyet, Fanny}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Pouyet/Unknown/Unknown{\_}Pouyet{\_}{\'{E}}tude bioinformatique de l'{\'{e}}volution de l'usage du code g{\'{e}}n{\'{e}}tique{\_}2016.pdf:pdf}, title = {{{\'{E}}tude bioinformatique de l'{\'{e}}volution de l'usage du code g{\'{e}}n{\'{e}}tique}}, url = {https://tel.archives-ouvertes.fr/tel-01410446}, year = {2016} } @article{Lepetit2016, abstract = {Parasites are sometimes able to manipulate the behavior of their hosts.However, the molecular cuesunderlying this phenomenon are poorly documented.We previously reported that the parasitoid wasp Leptopilina boulardi which develops from Drosophila larvae is often infectedby aninheritedDNAvirus. In addition tobeingmaternally transmitted, thevirusbenefits fromhorizontal transmission in superparasitized larvae (Drosophila that havebeenparasitized several times). Interestingly, thevirus forces infected females to lay eggs in already parasitized larvae, thus increasing the chance of being horizontally transmitted. In a first step towards the identification of virus genes responsible for the behavioral manipulation, we present here the genome sequence of the virus, called LbFV. The sequencing revealed that its genome contains an homologous repeat sequence (hrs) found in eight regions in the genome. The presence of this hrsmay explain the genomic plasticity that we observed for this genome. The genome of LbFV encodes 108 ORFs, most of themhaving no homologs in public databases. The virus is however related to Hytrosaviridae, although distantly. LbFVmay thus represent a member of a new virus family. Several genes of LbFVwere captured from eukaryotes, including two anti-apoptotic genes. More surprisingly, we found that LbFV captured from an ancestral wasp a protein with a Jumonji domain. This gene was afterwards duplicated in the virus genome.We hypothesized that this genemay be involved in manipulating the expression of wasp genes, and possibly in manipulating its behavior.}, author = {Lepetit, David and Gillet, Benjamin and Hughes, Sandrine and Kraaijeveld, Ken and Varaldi, Julien}, doi = {10.1093/gbe/evw277}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Behavior,Horizontal gene transfer,LbFV,Manipulation,Phylogeny,Recombination}, number = {12}, pages = {3718--3739}, pmid = {28173110}, title = {{Genome sequencing of the behavior manipulating virus lbfv reveals a possible new virus family}}, url = {https://academic.oup.com/gbe/article-abstract/8/12/3718/2737484}, volume = {8}, year = {2016} } @article{Julien-Laferriere2016a, abstract = {Synthetic biology has boomed since the early 2000s when it started being shown that it was possible to efficiently synthetize compounds of interest in a much more rapid and effective way by using other organisms than those naturally producing them. However, to thus engineer a single organism, often a microbe, to optimise one or a collection of metabolic tasks may lead to difficulties when attempting to obtain a production system that is efficient, or to avoid toxic effects for the recruited microorganism. The idea of using instead a microbial consortium has thus started being developed in the last decade. This was motivated by the fact that such consortia may perform more complicated functions than could single populations and be more robust to environmental fluctuations. Success is however not always guaranteed. In particular, establishing which consortium is best for the production of a given compound or set thereof remains a great challenge. This is the problem we address in this paper. We thus introduce an initial model and a method that enable to propose a consortium to synthetically produce compounds that are either exogenous to it, or are endogenous but where interaction among the species in the consortium could improve the production line.}, author = {Julien-Laferriere, Alice and Bulteau, Laurent and Parrot, Delphine and Marchetti-Spaccamela, Alberto and Stougie, Leen and Vinga, Susana and Mary, Arnaud and Sagot, Marie France}, doi = {10.1038/srep29182}, issn = {20452322}, journal = {Scientific Reports}, pmid = {27373593}, title = {{A Combinatorial Algorithm for Microbial Consortia Synthetic Design}}, url = {https://www.nature.com/articles/srep29182}, volume = {6}, year = {2016} } @article{Martinez2016, abstract = {Parasitoid wasps can be found in association with heritable viruses. Although some viruses have been shown to profoundly affect the biology and evolution of parasitoid wasps, the genetic and phenotypic diversity of parasitoid-associated viruses remains largely unexplored.We previously discovered a behaviour-manipulating DNA virus in the parasitoid wasp Leptopilina boulardi. In this species, which lays its eggs inside Drosophila larvae, Leptopilina boulardi filamentous virus (LbFV) forces the females to lay their eggs in already parasitized Drosophila larvae. This behavioural manipulation increases the chances for the horizontal transmission of the virus. Here, we describe in the same parasitoid species another virus, which we propose to call Leptopilina boulardi toti-like virus (LbTV). This doublestranded RNA virus is highly prevalent in insect laboratory lines as well as in parasitoids caught in the field. In some cases, LbTV was found in coinfection with LbFV, but did not affect the behaviour of the wasp. Instead we found that the presence of LbTV correlates with an increase in the number of offspring, mostly due to increased survival of parasitoid larvae. LbTV is vertically transmitted mostly through the maternal lineage even if frequent paternal transmission also occurs. Unlike LbFV, LbTV is not horizontally transmitted. Its genome encodes a putative RNA-dependent RNA polymerase (RdRp) showing similarities with RdRps of Totiviridae. These results underline the high incidence and diversity of inherited viruses in parasitoids as well as their potential impact on the phenotype of their hosts.}, author = {Martinez, Julien and Lepetit, David and Ravallec, Marc and d{\'{e}} ric Fleury, Fr{\'{e}} and Varaldi, Julien and {Julien Martinez}, Correspondence}, doi = {10.1099/jgv.0.000360}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Martinez et al/microbiologyresearch.org/microbiologyresearch.org{\_}Martinez et al.{\_}Additional heritable virus in the parasitic wasp Leptopilina boulardi prevalence, transmission.pdf:pdf}, journal = {microbiologyresearch.org}, month = {feb}, number = {2}, pages = {523--535}, publisher = {Microbiology Society}, title = {{Additional heritable virus in the parasitic wasp Leptopilina boulardi: prevalence, transmission and phenotypic effects}}, url = {www.microbiologyresearch.org}, volume = {97}, year = {2016} } @article{Larroque2016a, abstract = {Context: Quantifying gene flow in natural populations is a key topic in both evolutionary and conservation biology. Understanding the extent to which the landscape matrix facilitates or impedes gene flow is becoming a high priority in a context of worldwide habitat loss and fragmentation. Objectives: Unexpectedly, a lower genetic diversity and a higher genetic structure have been previously observed in the less fragmented and the most forested habitat across four pine marten (Martes martes) populations in France. Our aim was to quantify the effect of landscape on the spatial distribution of genetic diversity in two populations in contrasting habitats. Methods: We conducted an individual-based landscape genetics analysis in a highly fragmented rural plain (Bresse, n = 126) and in a highly forested (50 {\%}) mountainous area (Ari{\`{e}}ge, n = 88) in France. We tested for isolation-by-resistance using least-cost distances and used a causal modeling approach on 16,384 landscape and 104 elevation resistance scenarios. Results: Landscape structure influenced the genetic differentiation in Bresse, with vegetation providing more genetic connectivity over the study area than open areas, while roads and human buildings showed unexpected low resistance to gene flow. In Ari{\`{e}}ge, genetic differentiation was mainly associated with changes in elevation, with an optimal elevation for gene flow of around 1700 m, likely associated with changes in vegetation structure. Conclusions: The pine marten seems to be able to cope with human-dominated landscapes and with fragmented forest landscapes, whereas elevation is the major driver of genetic differentiation in our mountainous landscape. Additionally, we highlight the importance of spatial replication in landscape genetics for deriving reliable conservation and management measures over the species distribution.}, author = {Larroque, Jeremy and Ruette, Sandrine and Vandel, Jean Michel and Devillard, S{\'{e}}bastien}, doi = {10.1007/s10980-015-0281-6}, file = {:Users/navratil/Documents/Mendeley Desktop/Unknown/Vandel et al/researchgate.net/researchgate.net{\_}Vandel et al.{\_}Divergent landscape effects on genetic differentiation in two populations of the European pine marten (Ma.pdf:pdf}, issn = {15729761}, journal = {Landscape Ecology}, keywords = {Connectivity,Elevation,Isolation-by-distance,Isolation-by-resistance,Martes martes,Spatial replication}, number = {3}, pages = {517--531}, title = {{Divergent landscape effects on genetic differentiation in two populations of the European pine marten (Martes martes)}}, url = {https://www.researchgate.net/publication/282904236}, volume = {31}, year = {2016} } @article{Ndiaye2016, abstract = {The systematics of the arid-adapted Old World Gerbillus rodent genus has always been challenging, with many different taxonomic arrangements proposed. Beyond such taxonomic aspects, the timing and geographical pattern of the evolutionary history of this group remains largely unknown. Based on mitochondrial (cytochrome b) and nuclear (interphotoreceptor retinoid-binding protein) sequences obtained from the specimens of 21 species, we conducted a phylogenetic analysis of the group, estimated the ages and putative ancestral ranges of its major lineages. Four major clades were clearly retrieved within Gerbillus, for which we propose a subgenus rank. We showed that the emergence of the genus dates back to the end of the Miocene, which corresponds to a period of aridification and C4 vegetation expansion in open habitats, while the four sublineages originated at the end of the Pliocene. Most subsequent diversification events occurred during the Pleistocene, a period characterized by recurrent climatic/environmental shifts with increasing aridification during the last two millions of years. Finally, we suggested that most of the Gerbillus evolutionary history took place in Africa. Only in a few instances did dispersal events from Africa to Asia give birth to extant Asian lineages, a pattern that contrasts with what has been found in many animal groups.}, author = {Ndiaye, Arame and Chevret, Pascale and Dobigny, Gauthier and Granjon, Laurent}, doi = {10.1111/jzs.12143}, issn = {14390469}, journal = {Journal of Zoological Systematics and Evolutionary Research}, keywords = {Africa/Asia dispersal,Bayesian analyses,Dipodillus,Gerbillinae,arid zones,palaeo-environmental fluctuations,taxonomy}, month = {nov}, number = {4}, pages = {299--317}, publisher = {Blackwell Publishing Ltd}, title = {{Evolutionary systematics and biogeography of the arid habitat-adapted rodent genus Gerbillus (Rodentia, Muridae): a mostly Plio-Pleistocene African history}}, volume = {54}, year = {2016} } @article{Gregoire2016, abstract = {Background: Only 2 {\%} of the human genome code for proteins. Among the remaining 98 {\%}, transposable elements (TEs) represent millions of sequences. TEs have an impact on genome evolution by promoting mutations. Especially, TEs possess their own regulatory sequences and can alter the expression pattern of neighboring genes. Since they can potentially be harmful, TE activity is regulated by epigenetic mechanisms. These mechanisms participate in the modulation of gene expression and can be associated with some human diseases resulting from gene expression deregulation. The fact that the TE silencing can be removed in cancer could explain a part of the changes in gene expression. Indeed, epigenetic modifications associated locally with TE sequences could impact neighboring genes since these modifications can spread to adjacent sequences. Results: We compared the histone enrichment, TE neighborhood, and expression divergence of human genes between a normal and a cancer conditions. We show that the presence of TEs near genes is associated with greater changes in histone enrichment and that differentially expressed genes harbor larger histone enrichment variation related to the presence of particular TEs. Conclusions: Taken together, these results suggest that the presence of TEs near genes could favor important variation in gene expression when the cell environment is modified.}, author = {Gr{\'{e}}goire, Laura and Haudry, Annabelle and Lerat, Emmanuelle}, doi = {10.1186/s12864-016-2970-1}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Gr{\'{e}}goire, Haudry, Lerat/BMC Genomics/BMC Genomics{\_}Gr{\'{e}}goire, Haudry, Lerat{\_}The transposable element environment of human genes is associated with histone and expression chan.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Epigenetics,Gene regulation,Transposable elements}, month = {aug}, number = {1}, pmid = {27506777}, publisher = {BioMed Central Ltd.}, title = {{The transposable element environment of human genes is associated with histone and expression changes in cancer}}, volume = {17}, year = {2016} } @article{Venner2016, abstract = {Masting, a breeding strategy common in perennial plants, is defined by seed production that is highly variable over years and synchronized at the population level. Resource budget models (RBMs) proposed that masting relies on two processes: (i) the depletion of plant reserves following high fruiting levels, which leads to marked temporal fluctuations in fruiting; and (ii) outcross pollination that synchronizes seed crops among neighboring trees. We revisited the RBM approach to examine the extent to which masting could be impacted by the degree of pollination efficiency, by taking into account various logistic relationships between pollination success and pollen availability. To link masting to other reproductive traits, we split the reserve depletion coefficient into three biological parameters related to resource allocation strategies for flowering and fruiting. While outcross pollination is considered to be the key mechanism that synchronizes fruiting in RBMs, our model counterintuitively showed that intense masting should arise under low-efficiency pollination. When pollination is very efficient, medium-level masting may occur, provided that the costs of female flowering (relative to pollen production) and of fruiting (maximum fruit set and fruit size) are both very high. Our work highlights the powerful framework of RBMs, which include explicit biological parameters, to link fruiting dynamics to various reproductive traits and to provide new insights into the reproductive strategies of perennial plants.}, author = {Venner, Samuel and Siberchicot, Aur{\'{e}}lie and P{\'{e}}lisson, Pierre Fran{\c{c}}ois and Schermer, Eliane and Bel-Venner, Marie Claude and Nicolas, Manuel and D{\'{e}}bias, Fran{\c{c}}ois and Miele, Vincent and Sauzet, Sandrine and Boulanger, Vincent and Delzon, Sylvain}, doi = {10.1086/686684}, issn = {00030147}, journal = {American Naturalist}, keywords = {Fruit set,Fruit size,Masting,Pollination efficiency,Resource budget model,Sex allocation}, month = {jul}, number = {1}, pages = {66--75}, pmid = {27322122}, publisher = {University of Chicago Press}, title = {{Fruiting strategies of perennial plants: A resource budget model to couple mast seeding to pollination efficiency and resource allocation strategies}}, volume = {188}, year = {2016} } @article{Cariou2016, abstract = {Background: RAD-seq is a powerful tool, increasingly used in population genomics. However, earlier studies have raised red flags regarding possible biases associated with this technique. In particular, polymorphism on restriction sites results in preferential sampling of closely related haplotypes, so that RAD data tends to underestimate genetic diversity. Results: Here we (1) clarify the theoretical basis of this bias, highlighting the potential confounding effects of population structure and selection, (2) confront predictions to real data from in silico digestion of full genomes and (3) provide a proof of concept toward an ABC-based correction of the RAD-seq bias. Under a neutral and panmictic model, we confirm the previously established relationship between the true polymorphism and its RAD-based estimation, showing a more pronounced bias when polymorphism is high. Using more elaborate models, we show that selection, resulting in heterogeneous levels of polymorphism along the genome, exacerbates the bias and leads to a more pronounced underestimation. On the contrary, spatial genetic structure tends to reduce the bias. We confront the neutral and panmictic model to “ideal” empirical data (in silico RAD-sequencing) using full genomes from natural populations of the fruit fly Drosophila melanogaster and the fungus Shizophyllum commune, harbouring respectively moderate and high genetic diversity. In D. melanogaster, predictions fit the model, but the small difference between the true and RAD polymorphism makes this comparison insensitive to deviations from the model. In the highly polymorphic fungus, the model captures a large part of the bias but makes inaccurate predictions. Accordingly, ABC corrections based on this model improve the estimations, albeit with some imprecisions. Conclusion: The RAD-seq underestimation of genetic diversity associated with polymorphism in restriction sites becomes more pronounced when polymorphism is high. In practice, this means that in many systems where polymorphism does not exceed 2 {\%}, the bias is of minor importance in the face of other sources of uncertainty, such as heterogeneous bases composition or technical artefacts. The neutral panmictic model provides a practical mean to correct the bias through ABC, albeit with some imprecisions. More elaborate ABC methods might integrate additional parameters, such as population structure and selection, but their opposite effects could hinder accurate corrections.}, author = {Cariou, Marie and Duret, Laurent and Charlat, Sylvain}, doi = {10.1186/s12862-016-0791-0}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Cariou, Duret, Charlat/BMC Evolutionary Biology/BMC Evolutionary Biology{\_}Cariou, Duret, Charlat{\_}How and how much does RAD-seq bias genetic diversity estimates{\_}2016.pdf:pdf}, issn = {14712148}, journal = {BMC Evolutionary Biology}, keywords = {ABC,Allele drop-out,Non-neutral model,Population genomics,Population structure,Reduced representation genomics}, month = {nov}, number = {1}, pages = {1--8}, pmid = {27825303}, publisher = {BioMed Central}, title = {{How and how much does RAD-seq bias genetic diversity estimates?}}, volume = {16}, year = {2016} } @article{Carrouel2016, abstract = {In oral health, the interdental spaces are a real ecological niche for which the body has few or no alternative defenses and where the traditional daily methods for control by disrupting biofilm are not adequate. The interdental spaces are the source of many hypotheses regarding their potential associations with and/or causes of cardiovascular disease, diabetes, chronic kidney disease, degenerative disease, and depression. This PCR study is the first to describe the interdental microbiota in healthy adults aged 18-35 years-old with reference to the Socransky complexes. The complexes tended to reflect microbial succession events in developing dental biofilms. Early colonizers included members of the yellow, green, and purple complexes. The orange complex bacteria generally appear after the early colonizers and include many putative periodontal pathogens, such as Fusobacterium nucleatum. The red complex (Porphyromonas gingivalis, Tannerella forsythia, and Treponema denticola) was considered the climax community and is on the list of putative periodontal pathogens. The 19 major periodontal pathogens tested were expressed at various levels. F. nucleatum was the most abundant species, and the least abundant were Actinomyces viscosus, P. gingivalis, and Aggregatibacter actinomycetemcomitans. The genome counts for Eikenella corrodens, Campylobacter concisus, Campylobacter rectus, T. denticola, and Tannerella forsythensis increased significantly with subject age. The study highlights the observation that bacteria from the yellow complex (Streptococcus spp., S. mitis), the green complex (E. corrodens, Campylobacter gracilis, Capnocytophaga ochracea, Capnocytophaga sputigena, A. actinomycetemcomitans), the purple complex (Veillonella parvula, Actinomyces odontolyticus) and the blue complex (A. viscosus) are correlated. Concerning the orange complex, F. nucleatum is the most abundant species in interdental biofilm. The red complex, which is recognized as the most important pathogen in adult periodontal disease, represents 8.08{\%} of the 19 bacteria analyzed. P. gingivalis was detected in 19{\%} of healthy subjects and represents 0.02{\%} of the interdental biofilm. T. forsythensis and T. denticola (0.02 and 0.04{\%} of the interdental biofilm) were detected in 93 and 49{\%} of healthy subjects, respectively. The effective presence of periodontal pathogens is a strong indicator of the need to develop new methods for disrupting interdental biofilm in daily oral hygiene.}, author = {Carrouel, Florence and Viennot, St{\'{e}}phane and Santamaria, Julie and Veber, Philippe and Bourgeois, Denis}, doi = {10.3389/fmicb.2016.00840}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Carrouel et al/Frontiers in Microbiology/Frontiers in Microbiology{\_}Carrouel et al.{\_}Quantitative molecular detection of 19 major pathogens in the interdental biofilm of periodont.pdf:pdf}, issn = {1664302X}, journal = {Frontiers in Microbiology}, keywords = {Interdental microbiota,Oral biofilm,P. gingivalis,Periodontology,Socransky complexes}, number = {JUN}, publisher = {Frontiers Research Foundation}, title = {{Quantitative molecular detection of 19 major pathogens in the interdental biofilm of periodontally healthy young adults}}, url = {https://pubmed.ncbi.nlm.nih.gov/27313576/}, volume = {7}, year = {2016} } @article{Dumas2016, abstract = {Background: The genetic regulation of metabolic phenotypes (i.e., metabotypes) in type 2 diabetes mellitus occurs through complex organ-specific cellular mechanisms and networks contributing to impaired insulin secretion and insulin resistance. Genome-wide gene expression profiling systems can dissect the genetic contributions to metabolome and transcriptome regulations. The integrative analysis of multiple gene expression traits and metabolic phenotypes (i.e., metabotypes) together with their underlying genetic regulation remains a challenge. Here, we introduce a systems genetics approach based on the topological analysis of a combined molecular network made of genes and metabolites identified through expression and metabotype quantitative trait locus mapping (i.e., eQTL and mQTL) to prioritise biological characterisation of candidate genes and traits. Methods: We used systematic metabotyping by 1H NMR spectroscopy and genome-wide gene expression in white adipose tissue to map molecular phenotypes to genomic blocks associated with obesity and insulin secretion in a series of rat congenic strains derived from spontaneously diabetic Goto-Kakizaki (GK) and normoglycemic Brown-Norway (BN) rats. We implemented a network biology strategy approach to visualize the shortest paths between metabolites and genes significantly associated with each genomic block. Results: Despite strong genomic similarities (95-99 {\%}) among congenics, each strain exhibited specific patterns of gene expression and metabotypes, reflecting the metabolic consequences of series of linked genetic polymorphisms in the congenic intervals. We subsequently used the congenic panel to map quantitative trait loci underlying specific mQTLs and genome-wide eQTLs. Variation in key metabolites like glucose, succinate, lactate, or 3-hydroxybutyrate and second messenger precursors like inositol was associated with several independent genomic intervals, indicating functional redundancy in these regions. To navigate through the complexity of these association networks we mapped candidate genes and metabolites onto metabolic pathways and implemented a shortest path strategy to highlight potential mechanistic links between metabolites and transcripts at colocalized mQTLs and eQTLs. Minimizing the shortest path length drove prioritization of biological validations by gene silencing. Conclusions: These results underline the importance of network-based integration of multilevel systems genetics datasets to improve understanding of the genetic architecture of metabotype and transcriptomic regulation and to characterize novel functional roles for genes determining tissue-specific metabolism.}, author = {Dumas, Marc Emmanuel and Domange, C{\'{e}}line and Calderari, Sophie and Mart{\'{i}}nez, Andrea Rodr{\'{i}}guez and Ayala, Rafael and Wilder, Steven P. and Su{\'{a}}rez-Zamorano, Nicolas and Collins, Stephan C. and Wallis, Robert H. and Gu, Quan and Wang, Yulan and Hue, Christophe and Otto, Georg W. and Argoud, Kar{\`{e}}ne and Navratil, Vincent and Mitchell, Steve C. and Lindon, John C. and Holmes, Elaine and Cazier, Jean Baptiste and Nicholson, Jeremy K. and Gauguier, Dominique}, doi = {10.1186/s13073-016-0352-6}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Dumas et al/Genome Medicine/Genome Medicine{\_}Dumas et al.{\_}Topological analysis of metabolic networks integrating co-segregating transcriptomes and metabolomes in typ.pdf:pdf}, issn = {1756994X}, journal = {Genome Medicine}, keywords = {1H NMR,EQTL,Genome Mapping,MQTL,Metabolic networks,Metabolomics,Transcriptomics}, month = {sep}, number = {1}, pmid = {27716393}, publisher = {BioMed Central Ltd.}, title = {{Topological analysis of metabolic networks integrating co-segregating transcriptomes and metabolomes in type 2 diabetic rat congenic series}}, volume = {8}, year = {2016} } @article{Freyermuth2016, abstract = {Myotonic dystrophy (DM) is caused by the expression of mutant RNAs containing expanded CUG repeats that sequester muscleblind-like (MBNL) proteins, leading to alternative splicing changes. Cardiac alterations, characterized by conduction delays and arrhythmia, are the second most common cause of death in DM. Using RNA sequencing, here we identify novel splicing alterations in DM heart samples, including a switch from adult exon 6B towards fetal exon 6A in the cardiac sodium channel, SCN5A. We find that MBNL1 regulates alternative splicing of SCN5A mRNA and that the splicing variant of SCN5A produced in DM presents a reduced excitability compared with the control adult isoform. Importantly, reproducing splicing alteration of Scn5a in mice is sufficient to promote heart arrhythmia and cardiac-conduction delay, two predominant features of myotonic dystrophy. In conclusion, misregulation of the alternative splicing of SCN5A may contribute to a subset of the cardiac dysfunctions observed in myotonic dystrophy.}, author = {Freyermuth, Fernande and Rau, Fr{\'{e}}d{\'{e}}rique and Kokunai, Yosuke and Linke, Thomas and Sellier, Chantal and Nakamori, Masayuki and Kino, Yoshihiro and Arandel, Ludovic and Jollet, Arnaud and Thibault, Christelle and Philipps, Muriel and Vicaire, Serge and Jost, Bernard and Udd, Bjarne and Day, John W. and Duboc, Denis and Wahbi, Karim and Matsumura, Tsuyoshi and Fujimura, Harutoshi and Mochizuki, Hideki and Deryckere, Fran{\c{c}}ois and Kimura, Takashi and Nukina, Nobuyuki and Ishiura, Shoichi and Lacroix, Vincent and Campan-Fournier, Amandine and Navratil, Vincent and Chautard, Emilie and Auboeuf, Didier and Horie, Minoru and Imoto, Keiji and Lee, Kuang Yung and Swanson, Maurice S. and {De Munain}, Adolfo Lopez and Inada, Shin and Itoh, Hideki and Nakazawa, Kazuo and Ashihara, Takashi and Wang, Eric and Zimmer, Thomas and Furling, Denis and Takahashi, Masanori P. and Charlet-Berguerand, Nicolas}, doi = {10.1038/ncomms11067}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Freyermuth et al/Nature Communications/Nature Communications{\_}Freyermuth et al.{\_}Splicing misregulation of SCN5A contributes to cardiac-conduction delay and heart arrhythmia in.pdf:pdf}, issn = {20411723}, journal = {Nature Communications}, month = {apr}, pmid = {27063795}, publisher = {Nature Publishing Group}, title = {{Splicing misregulation of SCN5A contributes to cardiac-conduction delay and heart arrhythmia in myotonic dystrophy}}, volume = {7}, year = {2016} } @article{Salvetti2016, abstract = {Nucleolin (NCL) is a major component of the cell nucleolus, which has the ability to rapidly shuttle to several other cells' compartments. NCL plays important roles in a variety of essential functions, among which are ribosome biogenesis, gene expression, and cell growth. However, the precise mechanisms underlying NCL functions are still unclear. Our study aimed to provide new information on NCL functions via the identification of its nuclear interacting partners. Using an interactomics approach, we identified 140 proteins co-purified with NCL, among which 100 of them were specifically found to be associated with NCL after RNase digestion. The functional classification of these proteins confirmed the prominent role of NCL in ribosome biogenesis and additionally revealed the possible involvement of nuclear NCL in several pre-mRNA processing pathways through its interaction with RNA helicases and proteins participating in pre-mRNA splicing, transport, or stability. NCL knockdown experiments revealed that NCL regulates the localization of EXOSC10 and the amount of ZC3HAV1, two components of the RNA exosome, further suggesting its involvement in the control of mRNA stability. Altogether, this study describes the first nuclear interactome of human NCL and provides the basis for further understanding the mechanisms underlying the essential functions of this nucleolar protein.}, author = {Salvetti, Anna and Cout{\'{e}}, Yohann and Epstein, Alberto and Arata, Loredana and Kraut, Alexandra and Navratil, Vincent and Bouvet, Philippe and Greco, Anna}, doi = {10.1021/acs.jproteome.6b00126}, issn = {15353907}, journal = {Journal of Proteome Research}, keywords = {mRNA processing,nucleolin,proteomics,tandem affinity purification}, month = {may}, number = {5}, pages = {1659--1669}, pmid = {27049334}, publisher = {American Chemical Society}, title = {{Nuclear functions of nucleolin through global proteomics and interactomic approaches}}, volume = {15}, year = {2016} } @article{Francois2016, abstract = {The field of stoichiogenomics aims at understanding the influence of nutrient limitations on the elemental composition of the genome, transcriptome, and proteome. The 20 amino acids and the 4 nt differ in the number of nutrients they contain, such as nitrogen (N). Thus, N limitation shall theoretically select for changes in the composition of proteins or RNAs through preferential use of N-poor amino acids or nucleotides, which will decrease the N-budget of an organism. While these N-saving mechanisms have been evidenced in microorganisms, they remain controversial in multicellular eukaryotes. In this study, we used 13 surface and subterranean isopod species pairs that face strongly contrasted N limitations, either in terms of quantity or quality. We combined in situ nutrient quantification and transcriptome sequencing to test if N limitation selected for N-savings through changes in the expression and composition of the transcriptome and proteome. No evidence of N-savings was found in the total N-budget of transcriptomes or proteomes or in the average protein N-cost. Nevertheless, subterranean species evolving in N-depleted habitats displayed lower N-usage at their third codon positions. To test if this convergent compositional change was driven by natural selection, we developed a method to detect the strand-asymmetric signature that stoichiogenomic selection should leave in the substitution pattern. No such signature was evidenced, indicating that the observed stoichiogenomic-like patterns were attributable to nonadaptive processes. The absence of stoichiogenomic signal despite strong N limitation within a powerful phylogenetic framework casts doubt on the existence of stoichiogenomic mechanisms in metazoans.}, author = {Francois, Cl{\'{e}}mentine M. and Duret, Laurent and Simon, Laurent and Mermillod-Blondin, Florian and Malard, Florian and Konecny-Dupr{\'{e}}, Lara and Planel, R{\'{e}}mi and Penel, Simon and Douady, Christophe J. and Lef{\'{e}}bure, Tristan}, doi = {10.1093/molbev/msw131}, file = {:Users/navratil/Documents/Mendeley Desktop/2016/Francois et al/Molecular Biology and Evolution/Molecular Biology and Evolution{\_}Francois et al.{\_}No Evidence That Nitrogen Limitation Influences the Elemental Composition of Isopod Tran.pdf:pdf}, issn = {15371719}, journal = {Molecular Biology and Evolution}, keywords = {C:N mismatch,N availability,RNA and protein composition,comparative approach,nitrogen cost,orthologous gene families,stoichiogenomics}, month = {oct}, number = {10}, pages = {2605--2620}, pmid = {27401232}, publisher = {Oxford University Press}, title = {{No Evidence That Nitrogen Limitation Influences the Elemental Composition of Isopod Transcriptomes and Proteomes}}, volume = {33}, year = {2016} } @article{Jiang2016, abstract = {Dickeya species are soft rot disease-causing bacterial plant pathogens and an emerging agricultural threat in Europe. Environmental modulation of gene expression is critical for Dickeya dadantii pathogenesis. While the bacterium uses various environmental cues to distinguish between its habitats, an intricate transcriptional control system coordinating the expression of virulence genes ensures efficient infection. Understanding of this behaviour requires a detailed knowledge of expression patterns under a wide range of environmental conditions, which is currently lacking. To obtain a comprehensive picture of this adaptive response, we devised a strategy to examine the D. dadantii transcriptome in a series of 32 infection-relevant conditions encountered in the hosts. We propose a temporal map of the bacterial response to various stress conditions and show that D. dadantii elicits complex genetic behaviour combining common stress-response genes with distinct sets of genes specifically induced under each particular stress. Comparison of our dataset with an in planta expression profile reveals the combined impact of stress factors and enables us to predict the major stress confronting D. dadantii at a particular stage of infection. We provide a comprehensive catalog of D. dadantii genomic responses to environmentally relevant stimuli, thus facilitating future studies of this important plant pathogen.}, author = {Jiang, Xuejiao and Zghidi-Abouzid, Ouafa and Oger-Desfeux, Christine and Hommais, Florence and Greliche, Nicolas and Muskhelishvili, Georgi and Nasser, William and Reverchon, Sylvie}, doi = {10.1111/1462-2920.13267}, issn = {14622920}, journal = {Environmental Microbiology}, month = {nov}, number = {11}, pages = {3651--3672}, pmid = {26940633}, publisher = {Blackwell Publishing Ltd}, title = {{Global transcriptional response of Dickeya dadantii to environmental stimuli relevant to the plant infection}}, volume = {18}, year = {2016} } @article{Muyle2015, abstract = {The genetic basis of sex determination remains unknown for the vast majority of organisms with separate sexes. A key question is whether a species has sex chromosomes (SC). SC presence indicates genetic sex determination, and their sequencing may help identifying the sex-determining genes and understanding the molecular mechanisms of sex determination. Identifying SC, especially homomorphic SC, can be difficult. Sequencing SC is also very challenging, in particular the repeat-rich non-recombining regions. A novel approach for identifying sex-linked genes and SC consisting of using RNA-seq to genotype male and female individuals and study sex-linkage has recently been proposed. This approach entails a modest sequencing effort and does not require prior genomic or genetic resources, and is thus particularly suited to study non-model organisms. Applying this approach to many organisms is, however, difficult due to the lack of an appropriate statistically-grounded pipeline to analyse the data. Here we propose a model-based method to infer sex-linkage using a maximum likelihood framework and genotyping data from a full-sib family, which can be obtained for most organisms that can be grown in the lab and for economically important animals/plants. Our method works on any type of SC (XY, ZW, UV) and has been embedded in a pipeline that includes a genotyper specifically developed for RNA-seq data. Validation on empirical and simulated data indicates that our pipeline is particularly relevant to study SC of recent or intermediate age but can return useful information in old systems as well; it is available as a Galaxy workflow.}, author = {Muyle, Aline and K{\"{a}}fer, Jos and Zemp, Niklaus and Mousset, Sylvain and Picard, Franck and Marais, G. A. B.}, doi = {10.1101/023358}, journal = {bioRxiv}, keywords = {galaxy,non-model organisms,rna-seq,sex chromosomes,sex-linked genes,uv,xy,zw}, pages = {023358}, title = {{A probabilistic method for identifying sex-linked genes using RNA-seq-derived genotyping data}}, url = {https://doi.org/10.1101/023358 http://biorxiv.org/content/early/2015/07/27/023358.abstract}, year = {2015} } @article{Higashi2015, abstract = {Background: Several methods exist for the prediction of precursor miRNAs (pre-miRNAs) in genomic or sRNA-seq (small RNA sequences) data produced by NGS (Next Generation Sequencing). One key information used for this task is the characteristic hairpin structure adopted by pre-miRNAs, that in general are identified using RNA folders whose complexity is cubic in the size of the input. The vast majority of pre-miRNA predictors then rely on further information learned from previously validated miRNAs from the same or a closely related genome for the final prediction of new miRNAs. With this paper, we wished to address three main issues. The first was methodological and aimed at obtaining a more time-efficient predictor, however without losing in accuracy which represented a second issue. We indeed aimed at better predicting miRNAs at a genome scale, but also from sRNAseq data where in some cases, notably of plants, the current folding methods often infer the wrong structure. The third issue is related to the fact that it is important to rely as little as possible on previously recorded examples of miRNAs. We therefore also sought a method that is less dependent on previous miRNA records. Results: As concerns the first and second issues, we present a novel alternative to a classical folder based on a thermodynamic Nearest-Neighbour (NN) model for computing the free energy and predicting the classical hairpin structure of a pre-miRNA. We show that the free energies thus computed correlate well with those of RNAfold. This novel method, called Mirinho, has quadratic instead of cubic complexity and is much more efficient also in practice. When applied to sRNAseq data of plants, it gives in general better results than classical folders. On the third issue, we show that Mirinho, which uses as only knowledge the length of the loops and stem-arms and the free energy of the pre-miRNA hairpin, compares well with algorithms that require more information. The results, obtained with different datasets, are indeed similar to those of other approaches with which such a comparison was possible. These needed to be publicly available softwares that could be used on a large input. In some cases, Mirinho is even better in terms of sensitivity or precision. Conclusion: We provide a simpler and much faster method with very reasonable sensitivity and precision, which can be applied without special adaptation to the prediction of both animal and plant pre-miRNAs, using as input either genomic sequences or sRNA-seq data.}, author = {Higashi, Susan and Fournier, Cyril and Gautier, Christian and Gaspin, Christine and Sagot, Marie France}, doi = {10.1186/s12859-015-0594-0}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Higashi et al/BMC Bioinformatics/BMC Bioinformatics{\_}Higashi et al.{\_}Mirinho An efficient and general plant and animal pre-miRNA predictor for genomic and deep sequencing.pdf:pdf}, issn = {14712105}, journal = {BMC Bioinformatics}, keywords = {Free-energy,Plant/animal,Prediction,Quadratic algorithm,Whole genome {\&} sRNAseq,microRNA}, month = {may}, number = {1}, pmid = {26022464}, publisher = {BioMed Central Ltd.}, title = {{Mirinho: An efficient and general plant and animal pre-miRNA predictor for genomic and deep sequencing data}}, volume = {16}, year = {2015} } @article{Borland2015, abstract = {Background: Two-component systems (TCS) play critical roles in sensing and responding to environmental cues. Azospirillum is a plant growth-promoting rhizobacterium living in the rhizosphere of many important crops. Despite numerous studies about its plant beneficial properties, little is known about how the bacterium senses and responds to its rhizospheric environment. The availability of complete genome sequenced from four Azospirillum strains (A. brasilense Sp245 and CBG 497, A. lipoferum 4B and Azospirillum sp. B510) offers the opportunity to conduct a comprehensive comparative analysis of the TCS gene family. Results: Azospirillum genomes harbour a very large number of genes encoding TCS, and are especially enriched in hybrid histidine kinases (HyHK) genes compared to other plant-associated bacteria of similar genome sizes. We gained further insight into HyHK structure and architecture, revealing an intriguing complexity of these systems. An unusual proportion of TCS genes were orphaned or in complex clusters, and a high proportion of predicted soluble HKs compared to other plant-associated bacteria are reported. Phylogenetic analyses of the transmitter and receiver domains of A. lipoferum 4B HyHK indicate that expansion of this family mainly arose through horizontal gene transfer but also through gene duplications all along the diversification of the Azospirillum genus. By performing a genome-wide comparison of TCS, we unraveled important 'genus-defining' and 'plant-specifying' TCS. Conclusions: This study shed light on Azospirillum TCS which may confer important regulatory flexibility. Collectively, these findings highlight that Azospirillum genomes have broad potential for adaptation to fluctuating environments.}, author = {Borland, St{\'{e}}phanie and Oudart, Anne and Prigent-Combaret, Claire and Brochier-Armanet, C{\'{e}}line and Wisniewski-Dy{\'{e}}, Florence}, doi = {10.1186/s12864-015-1962-x}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Borland et al/BMC Genomics/BMC Genomics{\_}Borland et al.{\_}Genome-wide survey of two-component signal transduction systems in the plant growth-promoting bacterium Azos.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Azospirillum,Hybrid histidine kinase,PGPR,Signal transduction,Two-component systems}, month = {oct}, number = {1}, pmid = {26489830}, publisher = {BioMed Central Ltd.}, title = {{Genome-wide survey of two-component signal transduction systems in the plant growth-promoting bacterium Azospirillum}}, volume = {16}, year = {2015} } @article{Flandrois2015, abstract = {Background: Estimating the phylogenetic position of bacterial and archaeal organisms by genetic sequence comparisons is considered as the gold-standard in taxonomy. This is also a way to identify the species of origin of the sequence. The quality of the reference database used in such analyses is crucial: the database must reflect the up-to-date bacterial nomenclature and accurately indicate the species of origin of its sequences. Description: leBIBIQBPP is a web tool taking as input a series of nucleotide sequences belonging to one of a set of reference markers (e.g., SSU rRNA, rpoB, groEL2) and automatically retrieving closely related sequences, aligning them, and performing phylogenetic reconstruction using an approximate maximum likelihood approach. The system returns a set of quality parameters and, if possible, a suggested taxonomic assigment for the input sequences. The reference databases are extracted from GenBank and present four degrees of stringency, from the "superstringent" degree (one type strain per species) to the loosely parsed degree ("lax" database). A set of one hundred to more than a thousand sequences may be analyzed at a time. The speed of the process has been optimized through careful hardware selection and database design. Conclusion: leBIBIQBPP is a powerful tool helping biologists to position bacterial or archaeal sequence commonly used markers in a phylogeny. It is a diagnostic tool for clinical, industrial and environmental microbiology laboratory, as well as an exploratory tool for more specialized laboratories. Its main advantages, relatively to comparable systems are: i) the use of a broad set of databases covering diverse markers with various degrees of stringency; ii) the use of an approximate Maximum Likelihood approach for phylogenetic reconstruction; iii) a speed compatible with on-line usage; and iv) providing fully documented results to help the user in decision making.}, author = {Flandrois, Jean Pierre and Perri{\`{e}}re, Guy and Gouy, Manolo}, doi = {10.1186/s12859-015-0692-z}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Flandrois, Perri{\`{e}}re, Gouy/BMC Bioinformatics/BMC Bioinformatics{\_}Flandrois, Perri{\`{e}}re, Gouy{\_}leBIBIQBPP A set of databases and a webtool for automatic phylogenetic analysis of prokary.pdf:pdf}, issn = {14712105}, journal = {BMC Bioinformatics}, keywords = {Phylogeny,Prokaryotes,Taxonomic identification}, month = {aug}, number = {1}, pmid = {26264559}, publisher = {BioMed Central Ltd.}, title = {{leBIBIQBPP: A set of databases and a webtool for automatic phylogenetic analysis of prokaryotic sequences}}, volume = {16}, year = {2015} } @article{Chatagnon2015, abstract = {In mouse embryonic cells, ligand-activated retinoic acid receptors (RARs) play a key role in inhibiting pluripotency-maintaining genes and activating some major actors of cell differentiation. To investigate the mechanism underlying this dual regulation, we performed joint RAR/RXR ChIP-seq and mRNA-seq time series during the first 48 h of the RA-induced Primitive Endoderm (PrE) differentiation process in F9 embryonal carcinoma (EC) cells. We show here that this dual regulation is associated with RAR/RXR genomic redistribution during the differentiation process. In-depth analysis of RAR/RXR binding sites occupancy dynamics and composition show that in undifferentiated cells, RAR/RXR interact with genomic regions characterized by binding of pluripotency-associated factors and high prevalence of the non-canonical DR0-containing RA response element. By contrast, in differentiated cells, RAR/RXR bound regions are enriched in functional Sox17 binding sites and are characterized with a higher frequency of the canonical DR5 motif. Our data offer an unprecedentedly detailed view on the action of RA in triggering pluripotent cell differentiation and demonstrate that RAR/RXR action is mediated via two different sets of regulatory regions tightly associated with cell differentiation status.}, author = {Chatagnon, Amandine and Veber, Philippe and Morin, Val{\'{e}}rie and Bedo, Justin and Triqueneaux, G{\'{e}}rard and S{\'{e}}mon, Marie and Laudet, Vincent and D'Alch{\'{e}}-Buc, Florence and Benoit, G{\'{e}}rard}, doi = {10.1093/nar/gkv370}, issn = {13624962}, journal = {Nucleic Acids Research}, number = {10}, pages = {4833--4854}, pmid = {25897113}, title = {{RAR/RXR binding dynamics distinguish pluripotency from differentiation associated cis-regulatory elements}}, url = {https://academic.oup.com/nar/article-abstract/43/10/4833/2409338}, volume = {43}, year = {2015} } @techreport{Nguyen2015, abstract = {The effect of fluctuating environmental conditions (i.e. environmental stochasticity) on the evolution of virulence has been broadly overlooked, presumably due to a lack of connection between the fields of evolutionary epidemiology and insect ecology. Practitioners of the latter have known for a long time that stochastic environmental variations can impact the population dynamics of many insects, some of which are vectors of infectious diseases. Here we investigate whether environmental stochasticity affecting a vector's life history can have an indirect impact on the evolutionarily expected virulence of the parasite, using Chagas disease as an example. We model the evolution of virulence using the adaptive dynamics framework, showing that parasite virulence should decrease when the vector's dynamics randomly change in time. The decrease is even more pronounced when environmental variations are frequent and ample. This decrease in virulence can be viewed as a bet-hedging strategy: when a parasite is at a risk of not being transmitted (e.g. because vectors are scarce), its best option is to stay in the host longer - that is, to be less virulent. Lowering virulence is thus very similar to increasing iteroparity, a well-known risk-spreading strategy, and should be expected to evolve whenever parasite transmission varies randomly in time.}, author = {Nguyen, Anne and Rajon, Etienne and Fouchet, David and Pontier, Dominique and Rabinovich, Jorge and Gourbiere, Sebastien and Menu, Frederic}, booktitle = {bioRxiv}, doi = {10.1101/034041}, keywords = {Key-words}, pages = {034041}, title = {{Low virulence evolves as a bet-hedging strategy in fluctuating environment}}, url = {https://www.biorxiv.org/content/10.1101/034041.abstract http://biorxiv.org/lookup/doi/10.1101/034041}, year = {2015} } @article{Goubert2015, abstract = {Repetitive DNA, including transposable elements (TEs), is found throughout eukaryotic genomes. Annotating and assembling the "repeatome" during genome-wide analysis often poses a challenge. To address this problem, we present dnaPipeTE-a new bioinformatics pipeline that uses a sample of raw genomic reads. It produces precise estimates of repeated DNA content and TE consensus sequences, as well as the relative ages of TE families. We shows that dnaPipeTE performs well using very low coverage sequencing in different genomes, losing accuracy only with old TE families. We applied this pipeline to the genome of the Asian tiger mosquito Aedes albopictus, an invasive species of human health interest, for which the genome size is estimated to be over 1 Gbp. Using dnaPipeTE, we showed that this species harbors a large (50{\%} of the genome) and potentially active repeatome with an overall TE class and order composition similar to that of Aedes aegypti, the yellow fever mosquito. However, intraorder dynamics show clear distinctions between the two species, with differences at the TE family level. Our pipeline's ability to manage the repeatome annotation problem will make it helpful for new or ongoing assembly projects, and our results will benefit future genomic studies of A. albopictus.}, author = {Goubert, Cl{\'{e}}ment and Modolo, Laurent and Vieira, Cristina and Moro, Claire Valiente and Mavingui, Patrick and Boulesteix, Matthieu}, doi = {10.1093/gbe/evv050}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Aedes albopictus,Bioinformatic pipeline,Repeated DNA,TE analysis,Transposable elements,Trinity}, number = {4}, pages = {1192--1205}, pmid = {25767248}, title = {{De novo assembly and annotation of the Asian tiger mosquito (Aedesalbopictus) repeatome with dnaPipeTE from raw genomic reads and comparative analysis with the yellow fever mosquito (Aedes aegypti)}}, url = {https://academic.oup.com/gbe/article-abstract/7/4/1192/533768}, volume = {7}, year = {2015} } @article{Hellard2015, abstract = {Parasite interactions have been widely evidenced experimentally but field studies remain rare. Such studies are essential to detect interactions of interest and access (co)infection probabilities but face methodological obstacles. Confounding factors can create statistical associations, i.e. false parasite interactions. Among them, host age is a crucial covariate. It influences host exposition and susceptibility to many infections, and has a mechanical effect, older individuals being more at risk because of a longer exposure time. However, age is difficult to estimate in natural populations. Hence, one should be able to deal at least with its cumulative effect. Using a SI type dynamic model, we showed that the cumulative effect of age can generate false interactions theoretically (deterministic modeling) and with a real dataset of feline viruses (stochastic modeling). The risk to wrongly conclude to an association was maximal when parasites induced long-lasting antibodies and had similar forces of infection. We then proposed a method to correct for this effect (and for other potentially confounding shared risk factors) and made it available in a new R package, Interatrix. We also applied the correction to the feline viruses. It offers a way to account for an often neglected confounding factor and should help identifying parasite interactions in the field, a necessary step towards a better understanding of their mechanisms and consequences.}, author = {Hellard, El{\'{e}}onore and Pontier, Dominique and Siberchicot, Aur{\'{e}}lie and Sauvage, Frank and Fouchet, David}, doi = {10.1016/j.epidem.2015.02.004}, issn = {18780067}, journal = {Epidemics}, keywords = {Felis silvestris catus,Multiple infections,Parametric boostrap,SI model,Serology}, pages = {48--55}, pmid = {25979281}, title = {{Unknown age in health disorders: A method to account for its cumulative effect and an application to feline viruses interactions}}, url = {https://www.sciencedirect.com/science/article/pii/S1755436515000092}, volume = {11}, year = {2015} } @article{Modolo2015, abstract = {Background: Quality control is a necessary step of any Next Generation Sequencing analysis. Although customary, this step still requires manual interventions to empirically choose tuning parameters according to various quality statistics. Moreover, current quality control procedures that provide a "good quality" data set, are not optimal and discard many informative nucleotides. To address these drawbacks, we present a new quality control method, implemented in UrQt software, for Unsupervised Quality trimming of Next Generation Sequencing reads. Results: Our trimming procedure relies on a well-defined probabilistic framework to detect the best segmentation between two segments of unreliable nucleotides, framing a segment of informative nucleotides. Our software only requires one user-friendly parameter to define the minimal quality threshold (phred score) to consider a nucleotide to be informative, which is independent of both the experiment and the quality of the data. This procedure is implemented in C++ in an efficient and parallelized software with a low memory footprint. We tested the performances of UrQt compared to the best-known trimming programs, on seven RNA and DNA sequencing experiments and demonstrated its optimality in the resulting tradeoff between the number of trimmed nucleotides and the quality objective. Conclusions: By finding the best segmentation to delimit a segment of good quality nucleotides, UrQt greatly increases the number of reads and of nucleotides that can be retained for a given quality objective. UrQt source files, binary executables for different operating systems and documentation are freely available (under the GPLv3) at the following address: https://lbbe.univ-lyon1.fr/-UrQt-.html.}, author = {Modolo, Laurent and Lerat, Emmanuelle}, doi = {10.1186/s12859-015-0546-8}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Modolo, Lerat/BMC Bioinformatics/BMC Bioinformatics{\_}Modolo, Lerat{\_}UrQt an efficient software for the Unsupervised Quality trimming of NGS data{\_}2015.pdf:pdf}, issn = {14712105}, journal = {BMC Bioinformatics}, keywords = {Next-generation sequencing,Parallel computing,Quality control,Trimming,Unsupervised segmentation}, month = {apr}, number = {1}, pmid = {25924884}, publisher = {BioMed Central Ltd.}, title = {{UrQt: an efficient software for the Unsupervised Quality trimming of NGS data}}, volume = {16}, year = {2015} } @techreport{Semeria2015, author = {Semeria, Magali}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Semeria/Unknown/Unknown{\_}Semeria{\_}{\'{E}}volution de l'architecture des g{\'{e}}nomes mod{\'{e}}lisation et reconstruction phylog{\'{e}}n{\'{e}}tique{\_}2015.pdf:pdf}, keywords = {2015 Fran{\c{c}}ais {\"{i}}¿¿NNT,2015LYO10280{\"{i}}¿¿ {\"{i}}¿¿tel-01298034{\"{i}}¿¿,{\'{E}}volution de l'architecture des g{\'{e}}nomes}, title = {{{\'{E}}volution de l'architecture des g{\'{e}}nomes : mod{\'{e}}lisation et reconstruction phylog{\'{e}}n{\'{e}}tique}}, url = {https://tel.archives-ouvertes.fr/tel-01298034}, year = {2015} } @article{Martinez2015, author = {Martinez, Julien and Lepetit, David and Fleury, Frederic and Bernard, Claude and Lyon, University and Varaldi, Julien}, doi = {10.1099/jgv.0.000360}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Martinez et al/Article in Journal of General Virology/Article in Journal of General Virology{\_}Martinez et al.{\_}Additional heritable virus in the parasitic wasp Leptopilina boulardi prevalence.pdf:pdf}, isbn = {201507:57:55}, journal = {Article in Journal of General Virology}, title = {{Additional heritable virus in the parasitic wasp Leptopilina boulardi : prevalence, transmission and phenotypic effects}}, url = {http://www.ncbi.nlm.nih.gov/sra;}, year = {2015} } @article{Fischer2015, abstract = {Background: Terpenes represent one of the largest and most diversified families of natural compounds and are used in numerous industrial applications. Terpene synthase (TPS) genes originated in bacteria as diterpene synthase (di-TPS) genes. They are also found in plant and fungal genomes. The recent availability of a large number of fungal genomes represents an opportunity to investigate how genes involved in diterpene synthesis were acquired by fungi, and to assess the consequences of this process on the fungal metabolism. Results: In order to investigate the origin of fungal di-TPS, we implemented a search for potential fungal di-TPS genes and identified their presence in several unrelated Ascomycota and Basidiomycota species. The fungal di-TPS phylogenetic tree is function-related but is not associated with the phylogeny based on housekeeping genes. The lack of agreement between fungal and di-TPS-based phylogenies suggests the presence of Horizontal Gene Transfer (HGTs) events. Further evidence for HGT was provided by conservation of synteny of di-TPS and neighbouring genes in distantly related fungi. Conclusions: The results obtained here suggest that fungal di-TPSs originated from an ancient HGT event of a single di-TPS gene from a plant to a fungus in Ascomycota. In fungi, these di-TPSs allowed for the formation of clusters consisting in di-TPS, GGPPS and P450 genes to create functional clusters that were transferred between fungal species, producing diterpenes acting as hormones or toxins, thus affecting fungal development and pathogenicity.}, author = {Fischer, Marc J.C. and Rustenhloz, Camille and Leh-Louis, V{\'{e}}ronique and Perri{\`{e}}re, Guy}, doi = {10.1186/s12866-015-0564-8}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Fischer et al/BMC Microbiology/BMC Microbiology{\_}Fischer et al.{\_}Molecular and functional evolution of the fungal diterpene synthase genes{\_}2015.pdf:pdf}, issn = {14712180}, journal = {BMC Microbiology}, keywords = {Diterpene synthase,Fungi,Geranylgeranyl diphosphate synthase,Horizontal gene transfer}, month = {dec}, number = {1}, pmid = {26483054}, publisher = {BioMed Central}, title = {{Molecular and functional evolution of the fungal diterpene synthase genes}}, volume = {15}, year = {2015} } @article{Philippon2015, abstract = {Background: Phosphatidylinositol-3-kinases (PI3Ks) are a family of eukaryotic enzymes modifying phosphoinositides in phosphatidylinositols-3-phosphate. Located upstream of the AKT/mTOR signalling pathway, PI3Ks activate secondary messengers of extracellular signals. They are involved in many critical cellular processes such as cell survival, angiogenesis and autophagy. PI3K family is divided into three classes, including 14 human homologs. While class II enzymes are composed of a single catalytic subunit, class I and III also contain regulatory subunits. Here we present an in-depth phylogenetic analysis of all PI3K proteins. Results: We confirmed that PI3K catalytic subunits form a monophyletic group, whereas regulatory subunits form three distinct groups. The phylogeny of the catalytic subunits indicates that they underwent two major duplications during their evolutionary history: the most ancient arose in the Last Eukaryotic Common Ancestor (LECA) and led to the emergence of class III and class I/II, while the second - that led to the separation between class I and II - occurred later, in the ancestor of Unikonta (i.e., the clade grouping Amoebozoa, Fungi, and Metazoa). These two major events were followed by many lineage specific duplications in particular in vertebrates, but also in various protist lineages. Major loss events were also detected in Vidiriplantae and Fungi. For the regulatory subunits, we identified homologs of class III in all eukaryotic groups indicating that, for this class, both the catalytic and the regulatory subunits were presents in LECA. In contrast, homologs of the regulatory class I have a more recent origin. Conclusions: The phylogenetic analysis of the PI3K shed a new light on the evolutionary history of these enzymes. We found that LECA already contained a PI3K class III composed of a catalytic and a regulatory subunit. Absence of class II regulatory subunits and the recent origin of class I regulatory subunits is puzzling given that the class I/II catalytic subunit was present in LECA and has been conserved in most present-day eukaryotic lineages. We also found surprising major loss and duplication events in various eukaryotic lineages. Given the functional specificity of PI3K proteins, this suggests dynamic adaptation during the diversification of eukaryotes.}, author = {Philippon, H{\'{e}}lo{\"{i}}se and Brochier-Armanet, C{\'{e}}line and Perri{\`{e}}re, Guy}, doi = {10.1186/s12862-015-0498-7}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Philippon, Brochier-Armanet, Perri{\`{e}}re/BMC Evolutionary Biology/BMC Evolutionary Biology{\_}Philippon, Brochier-Armanet, Perri{\`{e}}re{\_}Evolutionary history of phosphatidylinositol- 3-kinases ancestral origin.pdf:pdf}, issn = {14712148}, journal = {BMC Evolutionary Biology}, keywords = {LECA,Phosphatidylinositol-3-kinases,phylogeny,signalling pathway}, month = {dec}, number = {1}, pmid = {26482564}, publisher = {BioMed Central}, title = {{Evolutionary history of phosphatidylinositol- 3-kinases: ancestral origin in eukaryotes and complex duplication patterns}}, volume = {15}, year = {2015} } @article{Semeria2015a, abstract = {Background: Most models of genome evolution concern either genetic sequences, gene content or gene order. They sometimes integrate two of the three levels, but rarely the three of them. Probabilistic models of gene order evolution usually have to assume constant gene content or adopt a presence/absence coding of gene neighborhoods which is blind to complex events modifying gene content. Results: We propose a probabilistic evolutionary model for gene neighborhoods, allowing genes to be inserted, duplicated or lost. It uses reconciled phylogenies, which integrate sequence and gene content evolution. We are then able to optimize parameters such as phylogeny branch lengths, or probabilistic laws depicting the diversity of susceptibility of syntenic regions to rearrangements. We reconstruct a structure for ancestral genomes by optimizing a likelihood, keeping track of all evolutionary events at the level of gene content and gene synteny. Ancestral syntenies are associated with a probability of presence. We implemented the model with the restriction that at most one gene duplication separates two gene speciations in reconciled gene trees. We reconstruct ancestral syntenies on a set of 12 drosophila genomes, and compare the evolutionary rates along the branches and along the sites. We compare with a parsimony method and find a significant number of results not supported by the posterior probability. The model is implemented in the Bio++ library. It thus benefits from and enriches the classical models and methods for molecular evolution.}, author = {Semeria, Magali and Tannier, Eric and Gu{\'{e}}guen, Laurent}, doi = {10.1186/1471-2105-16-S14-S5}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Semeria, Tannier, Gu{\'{e}}guen/BMC Bioinformatics/BMC Bioinformatics{\_}Semeria, Tannier, Gu{\'{e}}guen{\_}Probabilistic modeling of the evolution of gene synteny within reconciled phylogenies{\_}2015.pdf:pdf}, issn = {14712105}, journal = {BMC Bioinformatics}, keywords = {Bio++,Gene order,Gene tree reconciliation,Genome rearrangements}, month = {oct}, number = {14}, pmid = {26452018}, publisher = {BioMed Central Ltd.}, title = {{Probabilistic modeling of the evolution of gene synteny within reconciled phylogenies}}, volume = {16}, year = {2015} } @article{Galia2015, abstract = {Volume 3, no. 1, e01568-14, 2015. Page 1: The byline and affiliation line should read as given above.}, author = {Galia, Wessam and Mariani-Kurkdjian, Patricia and Bastien, Sylvere and Loukiadis, Estelle and Blanquet-Diot, St{\'{e}}phanie and Leriche, Fran{\c{c}}oise and Brug{\`{e}}re, Hubert and Shima, Ayaka and Oswald, Eric and Cournoyer, Benoit and Thevenot-Sergentet, Delphine}, doi = {10.1128/genomeA.00880-15}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Galia et al/Genome announcements/Genome announcements{\_}Galia et al.{\_}Correction for Galia et al., Genome Sequence and Annotation of a Human Infection Isolate of Escherichi.pdf:pdf}, issn = {2169-8287}, journal = {Genome announcements}, number = {4}, pmid = {26227612}, publisher = {American Society for Microbiology}, title = {{Correction for Galia et al., Genome Sequence and Annotation of a Human Infection Isolate of Escherichia coli O26:H11 Involved in a Raw Milk Cheese Outbreak.}}, url = {http://www.ncbi.nlm.nih.gov/pubmed/26227612 http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC4520910}, volume = {3}, year = {2015} } @article{Faucon2015a, abstract = {The capacity of mosquitoes to resist insecticides threatens the control of diseases such as dengue and malaria. Until alternative control tools are implemented, characterizing resistance mechanisms is crucial for managing resistance in natural populations. Insecticide biodegradation by detoxification enzymes is a common resistance mechanism; however, the genomic changes underlying this mechanism have rarely been identified, precluding individual resistance genotyping. In particular, the role of copy number variations (CNVs) and polymorphisms of detoxification enzymes have never been investigated at the genome level, although they can represent robust markers of metabolic resistance. In this context, we combined target enrichment with high-throughput sequencing for conducting the first comprehensive screening of gene amplifications and polymorphisms associated with insecticide resistance in mosquitoes. More than 760 candidate genes were captured and deep sequenced in several populations of the dengue mosquito Ae. aegypti displaying distinct genetic backgrounds and contrasted resistance levels to the insecticide deltamethrin. CNV analysis identified 41 gene amplifications associated with resistance, most affecting cytochrome P450s overtranscribed in resistant populations. Polymorphism analysis detected more than 30,000 variants and strong selection footprints in specific genomic regions. Combining Bayesian and allele frequency filtering approaches identified 55 nonsynonymous variants strongly associated with resistance. Both CNVs and polymorphisms were conserved within regions but differed across continents, confirming that genomic changes underlying metabolic resistance to insecticides are not universal. By identifying novel DNA markers of insecticide resistance, this study opens the way for tracking down metabolic changes developed by mosquitoes to resist insecticides within and among populations.}, author = {Faucon, Frederic and Dusfour, Isabelle and Gaude, Thierry and Navratil, Vincent and Boyer, Frederic and Chandre, Fabrice and Sirisopa, Patcharawan and Thanispong, Kanutcharee and Juntarajumnong, Waraporn and Poupardin, Rodolphe and Chareonviriyaphap, Theeraphap and Girod, Romain and Corbel, Vincent and Reynaud, Stephane and David, Jean Philippe}, doi = {10.1101/gr.189225.115}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Faucon et al/Genome Research/Genome Research{\_}Faucon et al.{\_}Identifying genomic changes associated with insecticide resistance in the dengue mosquito Aedes aegypti(2).pdf:pdf}, issn = {15495469}, journal = {Genome Research}, month = {sep}, number = {9}, pages = {1347--1359}, pmid = {26206155}, publisher = {Cold Spring Harbor Laboratory Press}, title = {{Identifying genomic changes associated with insecticide resistance in the dengue mosquito Aedes aegypti by deep targeted sequencing}}, url = {http://www.genome.org/cgi/doi/10.1101/gr.189225.115.}, volume = {25}, year = {2015} } @article{Guirimand2015, abstract = {VirHostNet release 2.0 (http://virhostnet.prabi.fr) is a knowledgebase dedicated to the network-based exploration of virus-host protein-protein interactions. Since the previous VirhostNet release (2009), a second run of manual curation was performed to annotate the new torrent of high-throughput protein-protein interactions data from the literature. This resource is shared publicly, in PSI-MI TAB 2.5 format, using a PSICQUIC web service. The new interface of VirHostNet 2.0 is based on Cytoscape web library and provides a user-friendly access to the most complete and accurate resource of virus-virus and virus-host protein-protein interactions as well as their projection onto their corresponding host cell protein interaction networks. We hope that the VirHostNet 2.0 system will facilitate systems biology and gene-centered analysis of infectious diseases and will help to identify new molecular targets for antiviral drugs design. This resource will also continue to help worldwide scientists to improve our knowledge on molecular mechanisms involved in the antiviral response mediated by the cell and in the viral strategies selected by viruses to hijack the host immune system.}, author = {Guirimand, Thibaut and Delmotte, St{\'{e}}phane and Navratil, Vincent}, doi = {10.1093/nar/gku1121}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Guirimand, Delmotte, Navratil/Nucleic Acids Research/Nucleic Acids Research{\_}Guirimand, Delmotte, Navratil{\_}VirHostNet 2.0 Surfing on the web of virushost molecular interactions data{\_}2015.pdf:pdf}, issn = {13624962}, journal = {Nucleic Acids Research}, month = {jan}, number = {D1}, pages = {D583--D587}, pmid = {25392406}, publisher = {Oxford University Press}, title = {{VirHostNet 2.0: Surfing on the web of virus/host molecular interactions data}}, volume = {43}, year = {2015} } @article{Mitchell2015, abstract = {The InterPro database (http://www.ebi.ac.uk/interpro/) is a freely available resource that can be used to classify sequences into protein families and to predict the presence of important domains and sites. Central to the InterPro database are predictive models, known as signatures, from a range of different protein family databases that have different biological focuses and use different methodological approaches to classify protein families and domains. InterPro integrates these signatures, capitalizing on the respective strengths of the individual databases, to produce a powerful protein classification resource. Here, we report on the status of InterPro as it enters its 15th year of operation, and give an overview of new developments with the database and its associated Web interfaces and software. In particular, the new domain architecture search tool is described and the process of mapping of Gene Ontology terms to InterPro is outlined. We also discuss the challenges faced by the resource given the explosive growth in sequence data in recent years. InterPro (version 48.0) contains 36 766 member database signatures integrated into 26 238 InterPro entries, an increase of over 3993 entries (5081 signatures), since 2012.}, author = {Mitchell, Alex and Chang, Hsin Yu and Daugherty, Louise and Fraser, Matthew and Hunter, Sarah and Lopez, Rodrigo and McAnulla, Craig and McMenamin, Conor and Nuka, Gift and Pesseat, Sebastien and Sangrador-Vegas, Amaia and Scheremetjew, Maxim and Rato, Claudia and Yong, Siew Yit and Bateman, Alex and Punta, Marco and Attwood, Teresa K. and Sigrist, Christian J.A. and Redaschi, Nicole and Rivoire, Catherine and Xenarios, Ioannis and Kahn, Daniel and Guyot, Dominique and Bork, Peer and Letunic, Ivica and Gough, Julian and Oates, Matt and Haft, Daniel and Huang, Hongzhan and Natale, Darren A. and Wu, Cathy H. and Orengo, Christine and Sillitoe, Ian and Mi, Huaiyu and Thomas, Paul D. and Finn, Robert D.}, doi = {10.1093/nar/gku1243}, file = {:Users/navratil/Documents/Mendeley Desktop/2015/Mitchell et al/Nucleic Acids Research/Nucleic Acids Research{\_}Mitchell et al.{\_}The InterPro protein families database The classification resource after 15 years{\_}2015.pdf:pdf}, issn = {13624962}, journal = {Nucleic Acids Research}, month = {jan}, number = {D1}, pages = {D213--D221}, pmid = {25428371}, publisher = {Oxford University Press}, title = {{The InterPro protein families database: The classification resource after 15 years}}, volume = {43}, year = {2015} } @article{Lyon2014, author = {Lyon, Bernard and Claude, L Universite and Lyon, Bernard}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Bouffaud/Unknown/Unknown{\_}Bouffaud{\_}Marie-Lara BOUFFAUD Histoire {\'{e}}volutive des Poaceae et relations avec la communaut{\'{e}} bact{\'{e}}rienne rhizosph{\'{e}}rique{\_}2011.pdf:pdf}, keywords = {16S rDNA taxonomic microarra,Evolutionary history}, title = {{Marie-Lara BOUFFAUD Histoire {\'{e}}volutive des Poaceae et relations avec la communaut{\'{e}} bact{\'{e}}rienne rhizosph{\'{e}}rique}}, url = {https://tel.archives-ouvertes.fr/tel-01002644}, year = {2014} } @article{Regnault2014, abstract = {Background: Despite numerous studies suggesting that amphibians are highly sensitive to cumulative anthropogenic stresses, the role pollutants play in the decline of amphibian populations remains unclear. Amongst the most common aquatic contaminants, polycyclic aromatic hydrocarbons (PAHs) have been shown to induce several adverse effects on amphibian species in the larval stages. Conversely, adults exposed to high concentrations of the ubiquitous PAH, benzo[a]pyrene (BaP), tolerate the compound thanks to their highly efficient hepatic detoxification mechanisms. Due to this apparent lack of toxic effect on adults, no studies have examined in depth the potential toxicological impact of PAH on the physiology of adult amphibian livers. This study sheds light on the hepatic responses of Xenopus tropicalis when exposed to high environmentally relevant concentrations of BaP, by combining a high throughput transcriptomic approach (mRNA deep sequencing) and a characterization of cellular and physiological modifications to the amphibian liver.Results: Transcriptomic changes observed in BaP-exposed Xenopus were further characterized using a time-dependent enrichment analysis, which revealed the pollutant-dependent gene regulation of important biochemical pathways, such as cholesterol biosynthesis, insulin signaling, adipocytokines signaling, glycolysis/gluconeogenesis and MAPK signaling. These results were substantiated at the physiological level with the detection of a pronounced metabolic disorder resulting in a possible insulin resistance-like syndrome phenotype. Hepatotoxicity induced by lipid and cholesterol metabolism impairments was clearly identified in BaP-exposed individuals.Conclusions: Our data suggested that BaP may disrupt overall liver physiology, and carbohydrate and cholesterol metabolism in particular, even after short-term exposure. These results are further discussed in terms of how this deregulation of liver physiology can lead to general metabolic impairment in amphibians chronically exposed to contaminants, thereby illustrating the role xenobiotics might play in the global decline in amphibian populations.}, author = {Regnault, Christophe and Worms, Isabelle A.M. and Oger-Desfeux, Christine and MelodeLima, Christelle and Veyrenc, Sylvie and Bayle, Marie Laure and Combourieu, Bruno and Bonin, Aur{\'{e}}lie and Renaud, Julien and Raveton, Muriel and Reynaud, St{\'{e}}phane}, doi = {10.1186/1471-2164-15-666}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Regnault et al/BMC Genomics/BMC Genomics{\_}Regnault et al.{\_}Impaired liver function in Xenopus tropicalis exposed to benzoapyrene Transcriptomic and metabolic evide(2).pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Benzo[a]pyrene,Insulin resistance-like syndrome,Liver,Metabolic disorders,RNA sequencing,Xenopus}, month = {aug}, number = {1}, pmid = {25103525}, publisher = {BioMed Central Ltd.}, title = {{Impaired liver function in Xenopus tropicalis exposed to benzo[a]pyrene: Transcriptomic and metabolic evidence}}, volume = {15}, year = {2014} } @article{Chevret2014, abstract = {The African pygmy mice (Mus, subgenus Nannomys) are a group of small-sized rodents that occur widely throughout sub- Saharan Africa. Chromosomal diversity within this group is extensive and numerous studies have shown the karyotype to be a useful taxonomic marker. This is pertinent to Mus minutoides populations in South Africa where two different cytotypes (2n = 34, 2n = 18) and a modification of the sex determination system (due to the presence of a Y chromosome in some females) have been recorded. This chromosomal diversity is mirrored by mitochondrial DNA sequences that unambiguously discriminate among the various pygmy mouse species and, importantly, the different M. minutoides cytotypes. However, the geographic delimitation and taxonomy of pygmy mice populations in South Africa is poorly understood. To address this, tissue samples of M. minutoides were taken and analysed from specimens housed in six South African museum collections. Partial cytochrome b sequences (400 pb) were successfully amplified from 44{\%} of the 154 samples processed. Two species were identified: M. indutus and M. minutoides. The sequences of the M. indutus samples provided two unexpected features: i) nuclear copies of the cytochrome b gene were detected in many specimens, and ii) the range of this species was found to extend considerably further south than is presently understood. The phylogenetic analysis of the M. minutoides samples revealed two well-supported clades: a Southern clade which included the two chromosomal groups previously identified in South Africa, and an Eastern clade that extended from Eastern Africa into South Africa. Congruent molecular phylogenetic and chromosomal datasets permitted the tentative chromosomal assignments of museum specimens within the different clades as well as the correction of misidentified museum specimens. {\textcopyright} 2014 Chevret et al.}, author = {Chevret, Pascale and Robinson, Terence J. and Perez, Julie and Veyrunes, Fr{\'{e}}d{\'{e}}ric and Britton-Davidian, Janice}, doi = {10.1371/journal.pone.0098499}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Chevret et al/PLoS ONE/PLoS ONE{\_}Chevret et al.{\_}A phylogeographic survey of the pygmy mouse Mus minutoides in South Africa Taxonomic and karyotypic inference fr.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, month = {jun}, number = {6}, publisher = {Public Library of Science}, title = {{A phylogeographic survey of the pygmy mouse Mus minutoides in South Africa: Taxonomic and karyotypic inference from cytochrome b sequences of museum specimens}}, volume = {9}, year = {2014} } @article{Billoir2014, abstract = {The number of samples needed to identify significant effects is a key question in biomedical studies, with consequences on experimental designs, costs and potential discoveries. In metabolic phenotyping studies, sample size determination remains a complex step. This is due particularly to the multiple hypothesis-testing framework and the top-down hypothesis-free approach, with no a priori known metabolic target. Until now, there was no standard procedure available to address this purpose. In this review, we discuss sample size estimation procedures for metabolic phenotyping studies. We release an automated implementation of the Data-driven Sample size Determination (DSD) algorithm for MATLAB and GNU Octave. Original research concerning DSD was published elsewhere. DSD allows the determination of an optimized sample size in metabolic phenotyping studies. The procedure uses analytical data only from a small pilot cohort to generate an expanded data set. The statistical recoupling of variables procedure is used to identify metabolic variables, and their intensity distributions are estimated by Kernel smoothing or log-normal density fitting. Statistically significant metabolic variations are evaluated using the Benjamini-Yekutieli correction and processed for data sets of various sizes. Optimal sample size determination is achieved in a context of biomarker discovery (at least one statistically significant variation) or metabolic exploration (a maximum of statistically significant variations). DSD toolbox is encoded in MATLAB R2008A (Mathworks, Natick, MA) for Kernel and log-normal estimates, and in GNU Octave for log-normal estimates (Kernel density estimates are not robust enough in GNU octave). It is available at http://www.prabi.fr/redmine/projects/dsd/repository, with a tutorial at http://www.prabi.fr/redmine/projects/dsd/wiki.}, author = {Billoir, Elise and Navratil, Vincent and Blaise, Benjamin J.}, doi = {10.1093/bib/bbu052}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Billoir, Navratil, Blaise/Briefings in Bioinformatics/Briefings in Bioinformatics{\_}Billoir, Navratil, Blaise{\_}Sample size calculation in metabolic phenotyping studies{\_}2014.pdf:pdf}, issn = {14774054}, journal = {Briefings in Bioinformatics}, keywords = {Chemometrics,Metabolic phenotyping,Sample size determination}, month = {nov}, number = {5}, pages = {813--819}, pmid = {25600654}, publisher = {Oxford University Press}, title = {{Sample size calculation in metabolic phenotyping studies}}, volume = {16}, year = {2014} } @article{David2014, abstract = {Background:Mosquito control programmes using chemical insecticides are increasingly threatened by the development of resistance. Such resistance can be the consequence of changes in proteins targeted by insecticides (target site mediated resistance), increased insecticide biodegradation (metabolic resistance), altered transport, sequestration or other mechanisms. As opposed to target site resistance, other mechanisms are far from being fully understood. Indeed, insecticide selection often affects a large number of genes and various biological processes can hypothetically confer resistance. In this context, the aim of the present study was to use RNA sequencing (RNA-seq) for comparing transcription level and polymorphism variations associated with adaptation to chemical insecticides in the mosquito Aedes aegypti. Biological materials consisted of a parental susceptible strain together with three child strains selected across multiple generations with three insecticides from different classes:the pyrethroid permethrin, the neonicotinoid imidacloprid and the carbamate propoxur.Results:After ten generations, insecticide-selected strains showed elevated resistance levels to the insecticides used for selection. RNA-seq data allowed detecting over 13,000 transcripts, of which 413 were differentially transcribed in insecticide-selected strains as compared to the susceptible strain. Among them, a significant enrichment of transcripts encoding cuticle proteins, transporters and enzymes was observed. Polymorphism analysis revealed over 2500 SNPs showing {\textgreater} 50{\%} allele frequency variations in insecticide-selected strains as compared to the susceptible strain, affecting over 1000 transcripts. Comparing gene transcription and polymorphism patterns revealed marked differences among strains. While imidacloprid selection was linked to the over transcription of many genes, permethrin selection was rather linked to polymorphism variations. Focusing on detoxification enzymes revealed that permethrin selection strongly affected the polymorphism of several transcripts encoding cytochrome P450 monooxygenases likely involved in insecticide biodegradation.Conclusions:The present study confirmed the power of RNA-seq for identifying concomitantly quantitative and qualitative transcriptome changes associated with insecticide resistance in mosquitoes. Our results suggest that transcriptome modifications can be selected rapidly by insecticides and affect multiple biological functions. Previously neglected by molecular screenings, polymorphism variations of detoxification enzymes may play an important role in the adaptive response of mosquitoes to insecticides. {\textcopyright} 2014 David et al.; licensee BioMed Central Ltd.}, author = {David, Jean Philippe and Faucon, Fr{\'{e}}d{\'{e}}ric and Chandor-Proust, Alexia and Poupardin, Rodolphe and Riaz, Muhammad A. and Bonin, Aur{\'{e}}lie and Navratil, Vincent and Reynaud, St{\'{e}}phane}, doi = {10.1186/1471-2164-15-174}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/David et al/BMC Genomics/BMC Genomics{\_}David et al.{\_}Comparative analysis of response to selection with three insecticides in the dengue mosquito Aedes aegypti (2).pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {CYP,Cuticle,Cytochrome P450 monooxygenase,Dengue,Detoxification enzymes,Insecticide resistance,Mosquito,RNA sequencing,RNA-seq,Transporters}, month = {mar}, number = {1}, pmid = {24593293}, publisher = {BioMed Central Ltd.}, title = {{Comparative analysis of response to selection with three insecticides in the dengue mosquito Aedes aegypti using mRNA sequencing}}, volume = {15}, year = {2014} } @article{Despres2014, abstract = {Background: Despite the intensive use of Bacillus thuringiensis israelensis (Bti) toxins for mosquito control, little is known about the long term effect of exposure to this cocktail of toxins on target mosquito populations. In contrast to the many cases of resistance to Bacillus thuringiensis Cry toxins observed in other insects, there is no evidence so far for Bti resistance evolution in field mosquito populations. High fitness costs measured in a Bti selected mosquito laboratory strain suggest that evolving resistance to Bti is costly. The aim of the present study was to identify transcription level and polymorphism variations associated with resistance to Bti toxins in the dengue vector Aedes aegypti. We used RNA sequencing (RNA-seq) for comparing a laboratory-selected strain showing elevated resistance to Bti toxins and its parental non-selected susceptible strain. As the resistant strain displayed two marked larval development phenotypes (slow and normal), each phenotype was analyzed separately in order to evidence potential links between resistance mechanisms and mosquito life-history traits. Results: A total of 12,458 genes were detected of which 844 were differentially transcribed between the resistant and susceptible strains. Polymorphism analysis revealed a total of 68,541 SNPs of which 12,571 SNPs exhibited more than 40{\%} frequency difference between the resistant and susceptible strains, affecting 2,953 genes. Bti resistance is associated with changes in the transcription level of enzymes involved in detoxification and chitin metabolism. Among previously described Bti-toxin receptors, four alkaline phosphatases (ALPs) were differentially transcribed between resistant and susceptible larvae, and non-synonymous changes affected the protein sequence of one cadherin, six aminopeptidases (APNs) and four a-amylases. Other putative Cry receptors located in lipid rafts, such as flotillin and glycoside hydrolases, were under-transcribed and/or contained non-synonymous substitutions. Finally, immunity-related genes showed contrasted transcription and polymorphisms patterns between the two developmental resistant phenotypes, suggesting the existence of trade-offs between Bti-resistance, life-history traits and immunity. Conclusions: The present study is the first to analyze the whole transcriptome of Bti-resistant mosquitoes by RNA-seq, shedding light on the importance of studying both transcription levels and sequence polymorphism variations to get a comprehensive view of insecticide resistance.}, author = {Despr{\'{e}}s, Laurence and Stalinski, Renaud and Tetreau, Guillaume and Paris, Margot and Bonin, Aur{\'{e}}lie and Navratil, Vincent and Reynaud, St{\'{e}}phane and David, Jean Philippe}, doi = {10.1186/1471-2164-15-926}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Despr{\'{e}}s et al/BMC Genomics/BMC Genomics{\_}Despr{\'{e}}s et al.{\_}Gene expression patterns and sequence polymorphisms associated with mosquito resistance to Bacillus thur(2).pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Bacillus thuringiensis israelensis toxins,Bio-insecticide resistance,Evolutionary trade-offs,Lipid rafts,Mosquito,RNA-seq,Resistance costs,Toxin receptors}, number = {1}, pmid = {25341495}, publisher = {BioMed Central Ltd.}, title = {{Gene expression patterns and sequence polymorphisms associated with mosquito resistance to Bacillus thuringiensis israelensis toxins}}, volume = {15}, year = {2014} } @article{Despres2014a, abstract = {Worldwide evolution of mosquito resistance to chemical insecticides represents a major challenge for public health, and the future of vector control largely relies on the development of biological insecticides that can be used in combination with chemicals (integrated management), with the expectation that populations already resistant to chemicals will not become readily resistant to biological insecticides. However, little is known about the metabolic pathways affected by selection with chemical or biological insecticides. Here we show that Aedes aegypti, a laboratory mosquito strain selected with a biological insecticide (Bacillus thuringiensis israelensis, Bti) evolved increased transcription of many genes coding for endopeptidases while most genes coding for detoxification enzymes were under-expressed. By contrast, in strains selected with chemicals, genes encoding detoxification enzymes were mostly over-expressed. In all the resistant strains, genes involved in immune response were under-transcribed, suggesting that basal immunity might be a general adjustment variable to compensate metabolic costs caused by insecticide selection. Bioassays generally showed no evidence for an increased susceptibility of selected strains towards the other insecticide type, and all chemical-resistant strains were as susceptible to Bti as the unselected parent strain, which is a good premise for sustainable integrated management of mosquito populations resistant to chemicals.}, author = {Despr{\'{e}}s, Laurence and Stalinski, Renaud and Faucon, Fr{\'{e}}d{\'{e}}ric and Navratil, Vincent and Viari, Alain and Paris, Margot and Tetreau, Guillaume and Poupardin, Rodolphe and Riaz, Muhammad Asam and Bonin, Aur{\'{e}}lie and Reynaud, St{\'{e}}phane and David, Jean Philippe}, doi = {10.1098/rsbl.2014.0716}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Despr{\'{e}}s et al/Biology Letters/Biology Letters{\_}Despr{\'{e}}s et al.{\_}Chemical and biological insecticides select distinct gene expression patterns in Aedes aegypti mosquito{\_}.pdf:pdf}, issn = {1744957X}, journal = {Biology Letters}, keywords = {Cross resistance,Detoxification,Immunity,Transcriptomics}, month = {dec}, number = {12}, pmid = {25540155}, publisher = {Royal Society of London}, title = {{Chemical and biological insecticides select distinct gene expression patterns in Aedes aegypti mosquito}}, volume = {10}, year = {2014} } @misc{Sonnhammer2014, abstract = {Given the rapid increase of species with a sequenced genome, the need to identify orthologous genes between them has emerged as a central bioinformatics task. Many different methods exist for orthology detection, which makes it difficult to decide which one to choose for a particular application. Here, we review the latest developments and issues in the orthology field, and summarize the most recent results reported at the third 'Quest for Orthologs' meeting. We focus on community efforts such as the adoption of reference proteomes, standard file formats and benchmarking. Progress in these areas is good, and they are already beneficial to both orthology consumers and providers. However, a major current issue is that the massive increase in complete proteomes poses computational challenges to many of the ortholog database providers, as most orthology inference algorithms scale at least quadratically with the number of proteomes. The Quest for Orthologs consortium is an open community with a number of working groups that join efforts to enhance various aspects of orthology analysis, such as defining standard formats and datasets, documenting community resources and benchmarking.}, author = {Sonnhammer, Erik L.L. and Gabaldon, Toni and {Sousa Da Silva}, Alan W. and Martin, Maria and Robinson-Rechavi, Marc and Boeckmann, Brigitte and Thomas, Paul D. and Dessimoz, Christophe}, booktitle = {Bioinformatics}, doi = {10.1093/bioinformatics/btu492}, file = {:Users/navratil/Documents/Mendeley Desktop/2014/Sonnhammer et al/Bioinformatics/Bioinformatics{\_}Sonnhammer et al.{\_}Big data and other challenges in the quest for orthologs{\_}2014.pdf:pdf}, issn = {14602059}, month = {may}, number = {21}, pages = {2993--2998}, pmid = {25064571}, publisher = {Oxford University Press}, title = {{Big data and other challenges in the quest for orthologs}}, volume = {30}, year = {2014} } @article{Navratil2013, abstract = {Supervised multivariate statistical analyses are often required to analyze the high-density spectral information in metabolic datasets acquired from complex mixtures in metabolic phenotyping studies. Here we present an implementation of the SRV-Statistical Recoupling of Variables-algorithm as an open-source Matlab and GNU Octave toolbox. SRV allows the identification of similarity between consecutive variables resulting from the high-resolution bucketing. Similar variables are gathered to restore the spectral dependency within the datasets and identify metabolic NMR signals. The correlation and significance of these new NMR variables for a given effect under study can then be measured and represented on a loading plot to allow a visual and efficient identification of candidate biomarkers. Further on, correlations between these candidate biomarkers can be visualized on a two-dimensional pseudospectrum, representing a correlation map, helping to understand the modifications of the underlying metabolic network. {\textcopyright} 2013 The Author. Published by Oxford University Press. All rights reserved.}, author = {Navratil, Vincent and Pontoizeau, Cl{\'{e}}ment and Billoir, Elise and Blaise, Benjamin J.}, doi = {10.1093/bioinformatics/btt136}, file = {:Users/navratil/Documents/Mendeley Desktop/2013/Navratil et al/Bioinformatics/Bioinformatics{\_}Navratil et al.{\_}SRV An open-source toolbox to accelerate the recovery of metabolic biomarkers and correlations from metab.pdf:pdf}, issn = {13674803}, journal = {Bioinformatics}, month = {may}, number = {10}, pages = {1348--1349}, pmid = {23508967}, title = {{SRV: An open-source toolbox to accelerate the recovery of metabolic biomarkers and correlations from metabolic phenotyping datasets}}, volume = {29}, year = {2013} } @article{DeChassey2013, abstract = {Virus-host interactomes are instrumental to understand global perturbations of cellular functions induced by infection and discover new therapies. The construction of such interactomes is, however, technically challenging and time consuming. Here we describe an original method for the prediction of high-confidence interactions between viral and human proteins through a combination of structure and high-quality interactome data. Validation was performed for the NS1 protein of the influenza virus, which led to the identification of new host factors that control viral replication. {\textcopyright} 2013 European Molecular Biology Organization.}, author = {{De Chassey}, Beno{\^{i}}t and Meyniel-Schicklin, Laur{\`{e}}ne and Aublin-Gex, Anne and Navratil, Vincent and Chantier, Thibaut and Andr{\'{e}}, Patrice and Lotteau, Vincent}, doi = {10.1038/embor.2013.130}, file = {:Users/navratil/Documents/Mendeley Desktop/2013/De Chassey et al/EMBO Reports/EMBO Reports{\_}De Chassey et al.{\_}Structure homology and interaction redundancy for discovering virus-host protein interactions{\_}2013.pdf:pdf}, issn = {1469221X}, journal = {EMBO Reports}, keywords = {interactome,prediction,protein interaction,structure,virus}, month = {oct}, number = {10}, pages = {938--944}, pmid = {24008843}, title = {{Structure homology and interaction redundancy for discovering virus-host protein interactions}}, volume = {14}, year = {2013} } @article{Lehembre2013, abstract = {Heavy metals are pollutants which affect all organisms. Since a small number of eukaryotes have been investigated with respect to metal resistance, we hypothesize that many genes that control this phenomenon remain to be identified. This was tested by screening soil eukaryotic metatranscriptomes which encompass RNA from organisms belonging to the main eukaryotic phyla. Soil-extracted polyadenylated mRNAs were converted into cDNAs and 35 of them were selected for their ability to rescue the metal (Cd or Zn) sensitive phenotype of yeast mutants. Few of the genes belonged to families known to confer metal resistance when overexpressed in yeast. Several of them were homologous to genes that had not been studied in the context of metal resistance. For instance, the BOLA ones, which conferred cross metal (Zn, Co, Cd, Mn) resistance may act by interfering with Fe homeostasis. Other genes, such as those encoding 110- to 130-amino-acid-long, cysteine-rich polypeptides, had no homologues in databases. This study confirms that functional metatranscriptomics represents a powerful approach to address basic biological processes in eukaryotes. The selected genes can be used to probe new pathways involved in metal homeostasis and to manipulate the resistance level of selected organisms. {\textcopyright} 2013 John Wiley {\&} Sons Ltd and Society for Applied Microbiology.}, author = {Lehembre, Fr{\'{e}}d{\'{e}}ric and Doillon, Didier and David, Elise and Perrotto, Sandrine and Baude, Jessica and Foulon, Julie and Harfouche, Lamia and Vallon, Laurent and Poulain, Julie and {Da Silva}, Corinne and Wincker, Patrick and Oger-Desfeux, Christine and Richaud, Pierre and Colpaert, Jan V. and Chalot, Michel and Fraissinet-Tachet, Laurence and Blaudez, Damien and Marmeisse, Roland}, doi = {10.1111/1462-2920.12143}, issn = {14622912}, journal = {Environmental Microbiology}, month = {oct}, number = {10}, pages = {2829--2840}, pmid = {23663419}, title = {{Soil metatranscriptomics for mining eukaryotic heavy metal resistance genes}}, volume = {15}, year = {2013} } @misc{Bouffaud2012, abstract = {A wide range of plant lines has been propagated by farmers during crop selection and dissemination, but consequences of this crop diversification on plant-microbe interactions have been neglected. Our hypothesis was that crop evolutionary history shaped the way the resulting lines interact with soil bacteria in their rhizospheres. Here, the significance of maize diversification as a factor influencing selection of soil bacteria by seedling roots was assessed by comparing rhizobacterial community composition of inbred lines representing the five main genetic groups of maize, cultivated in a same European soil. Rhizobacterial community composition of 21-day-old seedlings was analysed using a 16S rRNA taxonomic microarray targeting 19 bacterial phyla. Rhizobacterial community composition of inbred lines depended on the maize genetic group. Differences were largely due to the prevalence of certain Betaproteobacteria and especially Burkholderia, as confirmed by quantitative PCR and cloning/sequencing. However, these differences in bacterial root colonization did not correlate with plant microsatellite genetic distances between maize genetic groups or individual lines. Therefore, the genetic structure of maize that arose during crop diversification (resulting in five main groups), but not the extent of maize diversification itself (as determined by maize genetic distances), was a significant factor shaping rhizobacterial community composition of seedlings. {\textcopyright} 2011 Blackwell Publishing Ltd.}, author = {Bouffaud, Marie Lara and Kyselkov{\'{a}}, Martina and Gouesnard, Brigitte and Grundmann, Genevieve and Muller, Daniel and Mo{\"{e}}nne-Loccoz, Yvan}, booktitle = {Molecular Ecology}, doi = {10.1111/j.1365-294X.2011.05359.x}, issn = {09621083}, keywords = {Zea mays,bacterial community,plant diversity,rhizosphere,taxonomic microarray}, month = {jan}, number = {1}, pages = {195--206}, pmid = {22126532}, title = {{Is diversification history of maize influencing selection of soil bacteria by roots?}}, volume = {21}, year = {2012} } @techreport{Dray2012, abstract = {Species spatial distributions are the result of population demography, behavioral traits, and species interactions in spatially heterogeneous environmental conditions. Hence the composition of species assemblages is an integrative response variable, and its variability can be explained by the complex interplay among several structuring factors. The thorough analysis of spatial variation in species assemblages may help infer processes shaping ecological communities. We suggest that ecological studies would benefit from the combined use of the classical statistical models of community composition data, such as constrained or unconstrained multivariate analyses of site-by-species abundance tables, with rapidly emerging and diversifying methods of spatial pattern analysis. Doing so allows one to deal with spatially explicit ecological models of beta diversity in a biogeographic context through the multiscale analysis of spatial patterns in original species data tables, including spatial characterization of fitted or residual variation from environmental models. We summarize here the recent progress for specifying spatial features through spatial weighting matrices and spatial eigenfunctions in order to define spatially constrained or scale-explicit multivariate analyses. Through a worked example on tropical tree communities, we also show the potential of the overall approach to identify significant residual spatial patterns that could arise from the omission of important unmeasured explanatory variables or processes.}, author = {Dray, S and {P{\'{e}} Lissier}, R and Couteron, P and Fortin, M.-J and Legendre, P and Peres-Neto, P R and Bellier, E and Bivand, R and Blanchet, F G and {De Ca´ceres}, M and Ca´ceres, Ca´ and Dufour, A.-B and Heegaard, E and Jombart, T and Munoz, F and Oksanen, J and Thioulouse, J and Wagner, H H}, booktitle = {Ecological Monographs}, file = {:Users/navratil/Documents/Mendeley Desktop/2012/Dray et al/Ecological Monographs/Ecological Monographs{\_}Dray et al.{\_}Community ecology in the age of multivariate multiscale spatial analysis{\_}2012.pdf:pdf}, keywords = {ecological community,multivariate spatial data,ordination,spatial autocorrelation,spatial connectivity,spatial eigenfunction,spatial structure,spatial weight}, number = {3}, pages = {257--275}, title = {{Community ecology in the age of multivariate multiscale spatial analysis}}, url = {https://esajournals.onlinelibrary.wiley.com/doi/abs/10.1890/11-1183.1}, volume = {82}, year = {2012} } @article{Teulier2012, abstract = {The passage from shore to marine life of juvenile penguins represents a major energetic challenge to fuel intense and prolonged demands for thermoregulation and locomotion. Some functional changes developed at this crucial step were investigated by comparing pre-fledging king penguins with sea-acclimatized (SA) juveniles (Aptenodytes patagonicus). Transcriptomic analysis of pectoralis muscle biopsies revealed that most genes encoding proteins involved in lipid transport or catabolism were up-regulated, while genes involved in carbohydrate metabolism were mostly downregulated in SA birds. Determination of muscle enzymatic activities showed no changes in enzymes involved in the glycolytic pathway, but increased 3-hydroxyacyl-CoA dehydrogenase, an enzyme of the b-oxidation pathway. The respiratory rates of isolated muscle mitochondria were much higher with a substrate arising from lipid metabolism (palmitoyl-L-carnitine) in SA juveniles than in terrestrial controls, while no difference emerged with a substrate arising from carbohydrate metabolism (pyruvate). In vivo, perfusion of a lipid emulsion induced a fourfold larger thermogenic effect in SA than in control juveniles. The present integrative study shows that fuel selection towards lipid oxidation characterizes penguin acclimatization to marine life. Such acclimatization may involve thyroid hormones through their nuclear beta receptor and nuclear coactivators.}, author = {Teulier, Loic and D{\'{e}}gletagne, Cyril and Rey, Benjamin and Tornos, J{\'{e}}r{\'{e}}my and Keime, C{\'{e}}line and de Dinechin, Marc and Raccurt, Mireille and Rouanet, Jean Louis and Roussel, Damien and Duchamp, Claude}, doi = {10.1098/rspb.2011.2664}, file = {:Users/navratil/Documents/Mendeley Desktop/2012/Teulier et al/Proceedings of the Royal Society B Biological Sciences/Proceedings of the Royal Society B Biological Sciences{\_}Teulier et al.{\_}Selective upregulation of lipid metabolism in skeletal muscle of f.pdf:pdf}, issn = {14712954}, journal = {Proceedings of the Royal Society B: Biological Sciences}, keywords = {Energy substrates,In vivo,Mitochondria,Transcriptomic analysis}, month = {jun}, number = {1737}, pages = {2464--2472}, pmid = {22357259}, publisher = {Royal Society Publishing}, title = {{Selective upregulation of lipid metabolism in skeletal muscle of foraging juvenile king penguins: An integrative study}}, url = {https://pubmed.ncbi.nlm.nih.gov/22357259/}, volume = {279}, year = {2012} } @article{Simonis2012, abstract = {Background: Human T-cell leukemia virus type 1 (HTLV-1) and type 2 both target T lymphocytes, yet induce radically different phenotypic outcomes. HTLV-1 is a causative agent of Adult T-cell leukemia (ATL), whereas HTLV-2, highly similar to HTLV-1, causes no known overt disease. HTLV gene products are engaged in a dynamic struggle of activating and antagonistic interactions with host cells. Investigations focused on one or a few genes have identified several human factors interacting with HTLV viral proteins. Most of the available interaction data concern the highly investigated HTLV-1 Tax protein. Identifying shared and distinct host-pathogen protein interaction profiles for these two viruses would enlighten how they exploit distinctive or common strategies to subvert cellular pathways toward disease progression.Results: We employ a scalable methodology for the systematic mapping and comparison of pathogen-host protein interactions that includes stringent yeast two-hybrid screening and systematic retest, as well as two independent validations through an additional protein interaction detection method and a functional transactivation assay. The final data set contained 166 interactions between 10 viral proteins and 122 human proteins. Among the 166 interactions identified, 87 and 79 involved HTLV-1 and HTLV-2 -encoded proteins, respectively. Targets for HTLV-1 and HTLV-2 proteins implicate a diverse set of cellular processes including the ubiquitin-proteasome system, the apoptosis, different cancer pathways and the Notch signaling pathway.Conclusions: This study constitutes a first pass, with homogeneous data, at comparative analysis of host targets for HTLV-1 and -2 retroviruses, complements currently existing data for formulation of systems biology models of retroviral induced diseases and presents new insights on biological pathways involved in retroviral infection. {\textcopyright} 2012 Simonis et al; licensee BioMed Central Ltd.}, author = {Simonis, Nicolas and Rual, Jean Fran{\c{c}}ois and Lemmens, Irma and Boxus, Mathieu and Hirozane-Kishikawa, Tomoko and Gatot, Jean St{\'{e}}phane and Dricot, Am{\'{e}}lie and Hao, Tong and Vertommen, Didier and Legros, S{\'{e}}bastien and Daakour, Sarah and Klitgord, Niels and Martin, Maud and Willaert, Jean Fran{\c{c}}ois and Dequiedt, Franck and Navratil, Vincent and Cusick, Michael E. and Burny, Ars{\`{e}}ne and {Van Lint}, Carine and Hill, David E. and Tavernier, Jan and Kettmann, Richard and Vidal, Marc and Twizere, Jean Claude}, doi = {10.1186/1742-4690-9-26}, file = {:Users/navratil/Documents/Mendeley Desktop/2012/Simonis et al/Retrovirology/Retrovirology{\_}Simonis et al.{\_}Host-pathogen interactome mapping for HTLV-1 and -2 retroviruses{\_}2012.pdf:pdf}, issn = {17424690}, journal = {Retrovirology}, keywords = {HBZ,HTLV,Interactome,ORFeome,Retrovirus,Tax}, month = {mar}, pmid = {22458338}, title = {{Host-pathogen interactome mapping for HTLV-1 and -2 retroviruses}}, volume = {9}, year = {2012} } @article{Shintu2012, abstract = {The world faces complex challenges for chemical hazard assessment. Microfluidic bioartificial organs enable the spatial and temporal control of cell growth and biochemistry, critical for organ-specific metabolic functions and particularly relevant to testing the metabolic dose- response signatures associated with both pharmaceutical and environmental toxicity. Here we present an approach combining a microfluidic system with 1H NMR-based metabolomic footprinting, as a high-throughput small-molecule screening approach. We characterized the toxicity of several molecules: ammonia (NH 3), an environmental pollutant leading to metabolic acidosis and liver and kidney toxicity; dimethylsulfoxide (DMSO), a free radical-scavenging solvent; and N-acetyl-para-aminophenol (APAP, or paracetamol), a hepatotoxic analgesic drug. We report organ-specific NH 3 dose-dependent metabolic responses in several microfluidic bioartificial organs (liver, kidney, and cocultures), as well as predictive (99{\%} accuracy for NH 3 and 94{\%} for APAP) compound-specific signatures. Our integration of microtechnology, cell culture in microfluidic biochips, and metabolic profiling opens the development of so-called "metabolomics-on-a-chip" assays in pharmaceutical and environmental toxicology. {\textcopyright} 2012 American Chemical Society.}, author = {Shintu, Laetitia and Baudoin, R{\'{e}}gis and Navratil, Vincent and Prot, Jean Matthieu and Pontoizeau, Cl{\'{e}}ment and Defernez, Marianne and Blaise, Benjamin J. and Domange, C{\'{e}}line and P{\'{e}}ry, Alexandre R. and Toulhoat, Pierre and Legallais, C{\'{e}}cile and Brochot, C{\'{e}}line and Leclerc, Eric and Dumas, Marc Emmanuel}, doi = {10.1021/ac2011075}, issn = {00032700}, journal = {Analytical Chemistry}, month = {feb}, number = {4}, pages = {1840--1848}, pmid = {22242722}, title = {{Metabolomics-on-a-chip and predictive systems toxicology in microfluidic bioartificial organs}}, volume = {84}, year = {2012} } @article{Muyle2012, abstract = {Silene latifolia is a dioecious plant with heteromorphic sex chromosomes that have originated only {\~{}}10 million years ago and is a promising model organism to study sex chromosome evolution in plants. Previous work suggests that S. latifolia XY chromosomes have gradually stopped recombining and the Y chromosome is undergoing degeneration as in animal sex chromosomes. However, this work has been limited by the paucity of sex-linked genes available. Here, we used 35 Gb of RNA-seq data from multiple males (XY) and females (XX) of an S. latifolia inbred line to detect sex-linked SNPs and identified more than 1,700 sex-linked contigs (with X-linked and Y-linked alleles). Analyses using known sex-linked and autosomal genes, together with simulations indicate that these newly identified sex-linked contigs are reliable. Using read numbers, we then estimated expression levels of X-linked and Y-linked alleles in males and found an overall trend of reduced expression of Y-linked alleles, consistent with a widespread ongoing degeneration of the S. latifolia Y chromosome. By comparing expression intensities of X-linked alleles in males and females, we found that X-linked allele expression increases as Y-linked allele expression decreases in males, which makes expression of sex-linked contigs similar in both sexes. This phenomenon is known as dosage compensation and has so far only been observed in evolutionary old animal sex chromosome systems. Our results suggest that dosage compensation has evolved in plants and that it can quickly evolve de novo after the origin of sex chromosomes. {\textcopyright} 2012 Muyle et al.}, author = {Muyle, Aline and Zemp, Niklaus and Deschamps, Clothilde and Mousset, Sylvain and Widmer, Alex and Marais, Gabriel A.B.}, doi = {10.1371/journal.pbio.1001308}, file = {:Users/navratil/Documents/Mendeley Desktop/2012/Muyle et al/PLoS Biology/PLoS Biology{\_}Muyle et al.{\_}Rapid de novo evolution of X chromosome dosage compensation in Silene latifolia, a plant with young sex chromo.pdf:pdf}, issn = {15449173}, journal = {PLoS Biology}, month = {apr}, number = {4}, pmid = {22529744}, title = {{Rapid de novo evolution of X chromosome dosage compensation in Silene latifolia, a plant with young sex chromosomes}}, volume = {10}, year = {2012} } @article{Damon2012, abstract = {Eukaryotic organisms play essential roles in the biology and fertility of soils. For example the micro and mesofauna contribute to the fragmentation and homogenization of plant organic matter, while its hydrolysis is primarily performed by the fungi. To get a global picture of the activities carried out by soil eukaryotes we sequenced 2×10,000 cDNAs synthesized from polyadenylated mRNA directly extracted from soils sampled in beech (Fagus sylvatica) and spruce (Picea abies) forests. Taxonomic affiliation of both cDNAs and 18S rRNA sequences showed a dominance of sequences from fungi (up to 60{\%}) and metazoans while protists represented less than 12{\%} of the 18S rRNA sequences. Sixty percent of cDNA sequences from beech forest soil and 52{\%} from spruce forest soil had no homologs in the GenBank/EMBL/DDJB protein database. A Gene Ontology term was attributed to 39{\%} and 31.5{\%} of the spruce and beech soil sequences respectively. Altogether 2076 sequences were putative homologs to different enzyme classes participating to 129 KEGG pathways among which several were implicated in the utilisation of soil nutrients such as nitrogen (ammonium, amino acids, oligopeptides), sugars, phosphates and sulfate. Specific annotation of plant cell wall degrading enzymes identified enzymes active on major polymers (cellulose, hemicelluloses, pectin, lignin) and glycoside hydrolases represented 0.5{\%} (beech soil)-0.8{\%} (spruce soil) of the cDNAs. Other sequences coding enzymes active on organic matter (extracellular proteases, lipases, a phytase, P450 monooxygenases) were identified, thus underlining the biotechnological potential of eukaryotic metatranscriptomes. The phylogenetic affiliation of 12 full-length carbohydrate active enzymes showed that most of them were distantly related to sequences from known fungi. For example, a putative GH45 endocellulase was closely associated to molluscan sequences, while a GH7 cellobiohydrolase was closest to crustacean sequences, thus suggesting a potentially significant contribution of non-fungal eukaryotes in the actual hydrolysis of soil organic matter. {\textcopyright} 2012 Damon et al.}, author = {Damon, Coralie and Lehembre, Fr{\'{e}}d{\'{e}}ric and Oger-Desfeux, Christine and Luis, Patricia and Ranger, Jacques and Fraissinet-Tachet, Laurence and Marmeisse, Roland}, doi = {10.1371/journal.pone.0028967}, file = {:Users/navratil/Documents/Mendeley Desktop/2012/Damon et al/PLoS ONE/PLoS ONE{\_}Damon et al.{\_}Metatranscriptomics reveals the diversity of genes expressed by eukaryotes in forest soils{\_}2012.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, month = {jan}, number = {1}, pmid = {22238585}, title = {{Metatranscriptomics reveals the diversity of genes expressed by eukaryotes in forest soils}}, volume = {7}, year = {2012} } @article{Miklos2011, abstract = {Solutions containing high macromolecule concentrations are predicted to affect a number of protein properties compared to those properties in dilute solution. In cells, these macromolecular crowders have a large range of sizes and can occupy 30{\%} or more of the available volume. We chose to study the stability and ps-ns internal dynamics of a globular protein whose radius is {\~{}}2 nm when crowded by a synthetic microgel composed of poly(N-isopropylacrylamide-co-acrylic acid) with particle radii of {\~{}}300 nm.Results: Our studies revealed no change in protein rotational or ps-ns backbone dynamics and only mild ({\~{}}0.5 kcal/mol at 37°C, pH 5.4) stabilization at a volume occupancy of 70{\%}, which approaches the occupancy of closely packing spheres. The lack of change in rotational dynamics indicates the absence of strong crowder-protein interactions.Conclusions: Our observations are explained by the large size discrepancy between the protein and crowders and by the internal structure of the microgels, which provide interstitial spaces and internal pores where the protein can exist in a dilute solution-like environment. In summary, microgels that interact weakly with proteins do not strongly influence protein dynamics or stability because these large microgels constitute an upper size limit on crowding effects. {\textcopyright} 2011 Miklos et al; licensee BioMed Central Ltd.}, author = {Miklos, Andrew C and Li, Conggang and Sorrell, Courtney D. and Lyon, L. Andrew and Pielak, Gary J.}, doi = {10.1186/2046-1682-4-13}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Miklos et al/BMC Biophysics/BMC Biophysics{\_}Miklos et al.{\_}An upper limit for macromolecular crowding effects{\_}2011.pdf:pdf}, issn = {20461682}, journal = {BMC Biophysics}, number = {1}, title = {{An upper limit for macromolecular crowding effects}}, url = {https://tel.archives-ouvertes.fr/tel-01400842}, volume = {4}, year = {2011} } @article{Ontpellier2011, author = {Ontpellier, U Niversit{\'{e}} M}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Domelevo/Unknown/Unknown{\_}Domelevo{\_}Combinaison de mod{\`{e}}les phylog{\'{e}}n{\'{e}}tiques et longitudinaux pour l'analyse des s{\'{e}}quences biologiques reconstruction.pdf:pdf}, keywords = {()}, title = {{Combinaison de mod{\`{e}}les phylog{\'{e}}n{\'{e}}tiques et longitudinaux pour l'analyse des s{\'{e}}quences biologiques : reconstruction de HMM profils ancestraux}}, url = {https://tel.archives-ouvertes.fr/tel-00842847}, year = {2011} } @article{Palmeira2011, abstract = {Fast viral adaptation and the implication of this rapid evolution in the emergence of several new infectious diseases have turned this issue into a major challenge for various research domains. Indeed, viruses are involved in the development of a wide range of pathologies and understanding how viruses and host cells interact in the context of adaptation remains an open question. In order to provide insights into the complex interactions between viruses and their host organisms and namely in the acquisition of novel functions through exchanges of genetic material, we developed the PhEVER database. This database aims at providing accurate evolutionary and phylogenetic information to analyse the nature of virus-virus and virus-host lateral gene transfers. PhEVER (http:// pbil.univ-lyon1.fr/databases/phever) is a unique database of homologous families both (i) between sequences from different viruses and (ii) between viral sequences and sequences from cellular organisms. PhEVER integrates extensive data from up-to-date completely sequenced genomes (2426 non-redundant viral genomes, 1007 non-redundant prokaryotic genomes, 43 eukaryotic genomes ranging from plants to vertebrates) and offers a clustering of proteins into homologous families containing at least one viral sequences, as well as alignments and phylogenies for each of these families. Public access to PhEVER is available through its webpage and through all dedicated ACNUC retrieval systems. {\textcopyright} The Author(s) 2010.}, author = {Palmeira, Leonor and Penel, Simon and Lotteau, Vincent and Rabourdin-Combe, Chantal and Gautier, Christian}, doi = {10.1093/nar/gkq1013}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Palmeira et al/Nucleic Acids Research/Nucleic Acids Research{\_}Palmeira et al.{\_}PhEVER A database for the global exploration of virus-host evolutionary relationships{\_}2011.pdf:pdf}, issn = {13624962}, journal = {Nucleic Acids Research}, keywords = {Christian Gautier,Cluster Analysis,Databases,Evolution,Gene Transfer,Genes,Genetic*,Genome,Genomics,Horizontal,Host-Pathogen Interactions / genetics*,Leonor Palmeira,MEDLINE,Molecular*,NCBI,NIH,NLM,National Center for Biotechnology Information,National Institutes of Health,National Library of Medicine,Non-U.S. Gov't,PMC3013642,Phylogeny,PubMed Abstract,Research Support,Sequence Homology,Simon Penel,User-Computer Interface,Viral,Viral Proteins / chemistry,Viral Proteins / classification,Viral Proteins / genetics,Viruses / classification,Viruses / genetics*,doi:10.1093/nar/gkq1013,pmid:21081560}, number = {SUPPL. 1}, publisher = {Oxford University Press}, title = {{PhEVER: A database for the global exploration of virus-host evolutionary relationships}}, url = {https://pubmed.ncbi.nlm.nih.gov/21081560/}, volume = {39}, year = {2011} } @article{Jordheim2011, abstract = {Purpose: The need for new treatment options for acute myeloid leukemia (AML) is increasing. AS602868 is a novel investigational drug with reported activity on AML cells. Methods: We studied gene expression profiles in AML blasts exposed to AS602868 in order to better understand its mechanism of action. We analyzed the in vitro cytotoxicity of AS602868 alone or in combination with daunorubicin, etoposide or cytarabine. To document AS602868-induced IKK2 inhibition in fresh AML cells, a flow cytometry analysis of I$\kappa$B was performed. Finally, the effect of AS602868 on gene expression in fresh AML cells was analyzed. Results: The results show that AML cells are globally as sensitive to AS602868 as they are to cytarabine, with large interindividual variations. Combinations with conventional antileukemic agents showed enhanced cytotoxic activity in subsets of patients. IKK2 appeared to be effectively inhibited by 100 $\mu$M AS602868 in fresh leukemic cells. Gene expression profiling and gene ontology analyses identified several groups of genes induced/inhibited by exposure to AS602868 and/or exhibiting a correlation with sensitivity to this agent in vitro. Of note, the expression of several genes related to immune function was found to be significantly altered after exposure to AS602868. Conclusion: These data suggest that AS602868 is cytotoxic against fresh human AML blasts and provide insights regarding the mechanisms of cytotoxicity. {\textcopyright} 2010 Springer-Verlag.}, author = {Jordheim, Lars Petter and Plesa, Adriana and Dreano, Michel and Cros-Perrial, Emeline and Keime, C{\'{e}}line and Herveau, St{\'{e}}phanie and Demangel, Delphine and Vendrell, Julie A. and Dumontet, Charles}, doi = {10.1007/s00280-010-1458-y}, issn = {03445704}, journal = {Cancer Chemotherapy and Pharmacology}, keywords = {AS602868,Acute myeloid leukemia,Gene expression,Microarray,Sensitivity}, month = {jul}, number = {1}, pages = {97--105}, pmid = {20844879}, title = {{Sensitivity and gene expression profile of fresh human acute myeloid leukemia cells exposed ex vivo to AS602868}}, volume = {68}, year = {2011} } @article{Royer2011, abstract = {Serial analysis of gene expression (SAGE) profiles, from posterior and median cells of the silk gland of Bombyx mori, were analyzed and compared, so as to identify their respective distinguishing functions. The annotation of the SAGE libraries was performed with a B. mori reference tag collection, which was extracted from a novel set of Bombyx ESTs, sequenced from the 3' side. Most of the tags appeared at similar relative concentration within the two libraries, and corresponded with region-specific and highly abundant silk proteins. Strikingly, in addition to tags from silk protein mRNAs, 19 abundant tags were found (≥ 0.1{\%}), in the median cell library, which were absent in the posterior cell tag collection. With the exception of tags from SP1 mRNA, no PSG specific tags were found in this subset class. The analysis of some of the MSG-specific transcripts, suggested that middle silk gland cells have diversified functions, in addition to their well characterized role in silk sericins synthesis and secretion.}, author = {Royer, Corinne and Briolay, J{\'{e}}r{\^{o}}me and Garel, Annie and Brouilly, Patrick and Sasanuma, Shun-ichi and Sasanuma, Motoe and Shimomura, Michihiko and Keime, C{\'{e}}line and Gandrillon, Olivier and Huang, Yongping and Chavancy, G{\'{e}}rard and Mita, Kazuei and Couble, Pierre}, doi = {10.1016/j.ibmb.2010.11.003}, issn = {1879-0240}, journal = {Insect biochemistry and molecular biology}, keywords = {Bombyx,SAGE,Silk gland,Transcriptome}, month = {feb}, number = {2}, pages = {118--24}, pmid = {21078388}, publisher = {Elsevier Ltd}, title = {{Novel genes differentially expressed between posterior and median silk gland identified by SAGE-aided transcriptome analysis.}}, url = {http://www.ncbi.nlm.nih.gov/pubmed/21078388}, volume = {41}, year = {2011} } @article{Davidovic2011, abstract = {Fragile X syndrome (FXS) is the first cause of inherited intellectual disability, due to the silencing of the X-linked Fragile X Mental Retardation 1 gene encoding the RNA-binding protein FMRP. While extensive studies have focused on the cellular and molecular basis of FXS, neither human Fragile X patients nor the mouse model of FXS-the Fmr1-null mouse-have been profiled systematically at the metabolic and neurochemical level to provide a complementary perspective on the current, yet scattered, knowledge of FXS. Using proton high-resolution magic angle spinning nuclear magnetic resonance (1H HR-MAS NMR)-based metabolic profiling, we have identified a metabolic signature and biomarkers associated with FXS in various brain regions of Fmr1-deficient mice. Our study highlights for the first time that Fmr1 gene inactivation has profound, albeit coordinated consequences in brain metabolism leading to alterations in: (1) neurotransmitter levels, (2) osmoregulation, (3) energy metabolism, and (4) oxidative stress response. To functionally connect Fmr1-deficiency to its metabolic biomarkers, we derived a functional interaction network based on the existing knowledge (literature and databases) and show that the FXS metabolic response is initiated by distinct mRNAtargets and proteins interacting with FMRP, and then relayed by numerous regulatory proteins. This novel "integrated metabolome and interactome mapping" (iMIM) approach advantageously unifies novel metabolic findings with previously unrelated knowledge and highlights the contribution of novel cellular pathways to the pathophysiology of FXS. These metabolomic and integrative systems biology strategies will contribute to the development of potential drug targets and novel therapeutic interventions, which will eventually benefit FXS patients. {\textcopyright} 2011 by Cold Spring Harbor Laboratory Press.}, author = {Davidovic, Laetitia and Navratil, Vincent and Bonaccorso, Carmela M. and Catania, Maria Vincenza and Bardoni, Barbara and Dumas, Arc Emmanuel}, doi = {10.1101/gr.116764.110}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Davidovic et al/Genome Research/Genome Research{\_}Davidovic et al.{\_}A metabolomic and systems biology perspective on the brain of the Fragile X syndrome mouse model{\_}2011.pdf:pdf}, issn = {10889051}, journal = {Genome Research}, month = {dec}, number = {12}, pages = {2190--2202}, pmid = {21900387}, title = {{A metabolomic and systems biology perspective on the brain of the Fragile X syndrome mouse model}}, volume = {21}, year = {2011} } @article{Gregoire2011, abstract = {Autophagy is a conserved degradative pathway used as a host defense mechanism against intracellular pathogens. However, several viruses can evade or subvert autophagy to insure their own replication. Nevertheless, the molecular details of viral interaction with autophagy remain largely unknown. We have determined the ability of 83 proteins of several families of RNA viruses (Paramyxoviridae, Flaviviridae, Orthomyxoviridae, Retroviridae and Togaviridae), to interact with 44 human autophagy-associated proteins using yeast two-hybrid and bioinformatic analysis. We found that the autophagy network is highly targeted by RNA viruses. Although central to autophagy, targeted proteins have also a high number of connections with proteins of other cellular functions. Interestingly, immunity-associated GTPase family M (IRGM), the most targeted protein, was found to interact with the autophagy-associated proteins ATG5, ATG10, MAP1CL3C and SH3GLB1. Strikingly, reduction of IRGM expression using small interfering RNA impairs both Measles virus (MeV), Hepatitis C virus (HCV) and human immunodeficiency virus-1 (HIV-1)-induced autophagy and viral particle production. Moreover we found that the expression of IRGM-interacting MeV-C, HCV-NS3 or HIV-NEF proteins per se is sufficient to induce autophagy, through an IRGM dependent pathway. Our work reveals an unexpected role of IRGM in virus-induced autophagy and suggests that several different families of RNA viruses may use common strategies to manipulate autophagy to improve viral infectivity. {\textcopyright} 2011 Gr{\'{e}}goire et al.}, author = {Gr{\'{e}}goire, Isabel Pombo and Richetta, Cl{\'{e}}mence and Meyniel-Schicklin, Laur{\`{e}}ne and Borel, Sophie and Pradezynski, Fabrine and Diaz, Olivier and Deloire, Alexandre and Azocar, Olga and Baguet, Jo{\"{e}}l and {Le Breton}, Marc and Mangeot, Philippe E. and Navratil, Vincent and Joubert, Pierre Emmanuel and Flacher, Monique and Vidalain, Pierre Olivier and Andr{\'{e}}, Patrice and Lotteau, Vincent and Biard-Piechaczyk, Martine and Rabourdin-Combe, Chantal and Faure, Mathias}, doi = {10.1371/journal.ppat.1002422}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Gr{\'{e}}goire et al/PLoS Pathogens/PLoS Pathogens{\_}Gr{\'{e}}goire et al.{\_}IRGM is a common target of RNA viruses that subvert the autophagy network{\_}2011(2).pdf:pdf}, issn = {15537366}, journal = {PLoS Pathogens}, month = {dec}, number = {12}, pmid = {22174682}, title = {{IRGM is a common target of RNA viruses that subvert the autophagy network}}, volume = {7}, year = {2011} } @article{Navratil2011, abstract = {Background: Comprehensive understanding of molecular mechanisms underlying viral infection is a major challenge towards the discovery of new antiviral drugs and susceptibility factors of human diseases. New advances in the field are expected from systems-level modelling and integration of the incessant torrent of high-throughput "-omics" data.Results: Here, we describe the Human Infectome protein interaction Network, a novel systems virology model of a virtual virus-infected human cell concerning 110 viruses. This in silico model was applied to comprehensively explore the molecular relationships between viruses and their associated diseases. This was done by merging virus-host and host-host physical protein-protein interactomes with the set of genes essential for viral replication and involved in human genetic diseases. This systems-level approach provides strong evidence that viral proteomes target a wide range of functional and inter-connected modules of proteins as well as highly central and bridging proteins within the human interactome. The high centrality of targeted proteins was correlated to their essentiality for viruses' lifecycle, using functional genomic RNAi data. A stealth-attack of viruses on proteins bridging cellular functions was demonstrated by simulation of cellular network perturbations, a property that could be essential in the molecular aetiology of some human diseases. Networking the Human Infectome and Diseasome unravels the connectivity of viruses to a wide range of diseases and profiled molecular basis of Hepatitis C Virus-induced diseases as well as 38 new candidate genetic predisposition factors involved in type 1 diabetes mellitus.Conclusions: The Human Infectome and Diseasome Networks described here provide a unique gateway towards the comprehensive modelling and analysis of the systems level properties associated to viral infection as well as candidate genes potentially involved in the molecular aetiology of human diseases. {\textcopyright} 2011 Navratil et al; licensee BioMed Central Ltd.}, author = {Navratil, Vincent and de Chassey, Benoit and Combe, Chantal R. and Lotteau, Vincent}, doi = {10.1186/1752-0509-5-13}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Navratil et al/BMC Systems Biology/BMC Systems Biology{\_}Navratil et al.{\_}When the human viral infectome and diseasome networks collide Towards a systems biology platform for.pdf:pdf}, issn = {17520509}, journal = {BMC Systems Biology}, month = {jan}, number = {SUPPL. 1}, pmid = {21255393}, publisher = {BioMed Central Ltd.}, title = {{When the human viral infectome and diseasome networks collide: Towards a systems biology platform for the aetiology of human diseases}}, volume = {5}, year = {2011} } @article{Blavet2011, abstract = {Background: The genus Silene is widely used as a model system for addressing ecological and evolutionary questions in plants, but advances in using the genus as a model system are impeded by the lack of available resources for studying its genome. Massively parallel sequencing cDNA has recently developed into an efficient method for characterizing the transcriptomes of non-model organisms, generating massive amounts of data that enable the study of multiple species in a comparative framework. The sequences generated provide an excellent resource for identifying expressed genes, characterizing functional variation and developing molecular markers, thereby laying the foundations for future studies on gene sequence and gene expression divergence. Here, we report the results of a comparative transcriptome sequencing study of eight individuals representing four Silene and one Dianthus species as outgroup. All sequences and annotations have been deposited in a newly developed and publicly available database called SiESTa, the Silene EST annotation database.Results: A total of 1,041,122 EST reads were generated in two runs on a Roche GS-FLX 454 pyrosequencing platform. EST reads were analyzed separately for all eight individuals sequenced and were assembled into contigs using TGICL. These were annotated with results from BLASTX searches and Gene Ontology (GO) terms, and thousands of single-nucleotide polymorphisms (SNPs) were characterized. Unassembled reads were kept as singletons and together with the contigs contributed to the unigenes characterized in each individual. The high quality of unigenes is evidenced by the proportion (49{\%}) that have significant hits in similarity searches with the A. thaliana proteome. The SiESTa database is accessible at http://www.siesta.ethz.ch.Conclusion: The sequence collections established in the present study provide an important genomic resource for four Silene and one Dianthus species and will help to further develop Silene as a plant model system. The genes characterized will be useful for future research not only in the species included in the present study, but also in related species for which no genomic resources are yet available. Our results demonstrate the efficiency of massively parallel transcriptome sequencing in a comparative framework as an approach for developing genomic resources in diverse groups of non-model organisms. {\textcopyright} 2011 Blavet et al; licensee BioMed Central Ltd.}, author = {Blavet, Nicolas and Charif, Delphine and Oger-Desfeux, Christine and Marais, Gabriel A.B. and Widmer, Alex}, doi = {10.1186/1471-2164-12-376}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Blavet et al/BMC Genomics/BMC Genomics{\_}Blavet et al.{\_}Comparative high-throughput transcriptome sequencing and development of SiESTa, the Silene EST annotation dat.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Database,ESTSNP,Silene,cDNA library}, month = {jul}, pmid = {21791039}, title = {{Comparative high-throughput transcriptome sequencing and development of SiESTa, the Silene EST annotation database}}, volume = {12}, year = {2011} } @article{Lassalle2011, abstract = {The definition of bacterial species is based on genomic similarities, giving rise to the operational concept of genomic species, but the reasons of the occurrence of differentiated genomic species remain largely unknown. We used the Agrobacterium tumefaciens species complex and particularly the genomic species presently called genomovar G8, which includes the sequenced strain C58, to test the hypothesis of genomic species having specific ecological adaptations possibly involved in the speciation process. We analyzed the gene repertoire specific to G8 to identify potential adaptive genes. By hybridizing 25 strains of A. tumefaciens on DNA microarrays spanning the C58 genome, we highlighted the presence and absence of genes homologous to C58 in the taxon. We found 196 genes specific to genomovar G8 that were mostly clustered into seven genomic islands on the C58 genome-one on the circular chromosome and six on the linear chromosome-suggesting higher plasticity and a major adaptive role of the latter. Clusters encoded putative functional units, four of which had been verified experimentally. The combination of G8-specific functions defines a hypothetical species primary niche for G8 related to commensal interaction with a host plant. This supports that the G8 ancestor was able to exploit a new ecological niche, maybe initiating ecological isolation and thus speciation. Searching genomic data for synapomorphic traits is a powerful way to describe bacterial species. This procedure allowed us to find such phenotypic traits specific to genomovar G8 and thus propose a Latin binomial, Agrobacterium fabrum, for this bona fide genomic species. {\textcopyright} The Author(s) 2010.}, author = {Lassalle, Florent and Campillo, Tony and Vial, Ludovic and Baude, Jessica and Costechareyre, Denis and Chapulliot, David and Shams, Malek and Abrouk, Danis and Lavire, C{\'{e}}line and Oger-Desfeux, Christine and Hommais, Florence and Gu{\'{e}}guen, Laurent and Daubin, Vincent and Muller, Daniel and Nesme, Xavier}, doi = {10.1093/gbe/evr070}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Lassalle et al/Genome Biology and Evolution/Genome Biology and Evolution{\_}Lassalle et al.{\_}Genomic species are ecological species as revealed by comparative genomics in Agrobacterium.pdf:pdf}, issn = {17596653}, journal = {Genome Biology and Evolution}, keywords = {Agrobacterium,Bacterial evolution,Bacterial species,Ecological niche,Linear chromosome}, number = {1}, pages = {762--781}, pmid = {21795751}, title = {{Genomic species are ecological species as revealed by comparative genomics in Agrobacterium tumefaciens}}, volume = {3}, year = {2011} } @article{Hommais2011, abstract = {Background: Quantitative RT-PCR is the method of choice for studying, with both sensitivity and accuracy, the expression of genes. A reliable normalization of the data, using several reference genes, is critical for an accurate quantification of gene expression. Here, we propose a set of reference genes, of the phytopathogenic bacteria Dickeya dadantii and Pectobacterium atrosepticum, which are stable in a wide range of growth conditions. Results: We extracted, from a D. dadantii micro-array transcript profile dataset comprising thirty-two different growth conditions, an initial set of 49 expressed genes with very low variation in gene expression. Out of these, we retained 10 genes representing different functional categories, different levels of expression (low, medium, and high) and with no systematic variation in expression correlating with growth conditions. We measured the expression of these reference gene candidates using quantitative RT-PCR in 50 different experimental conditions, mimicking the environment encountered by the bacteria in their host and directly during the infection process in planta. The two most stable genes (ABF-0017965 (lpxC) and ABF-0020529 (yafS) were successfully used for normalization of RT-qPCR data. Finally, we demonstrated that the ortholog of lpxC and yafS in Pectobacterium atrosepticum also showed stable expression in diverse growth conditions. Conclusions: We have identified at least two genes, lpxC (ABF-0017965) and yafS (ABF-0020509), whose expressions are stable in a wide range of growth conditions and during infection. Thus, these genes are considered suitable for use as reference genes for the normalization of real-time RT-qPCR data of the two main pectinolytic phytopathogenic bacteria D. dadantii and P. atrosepticum and, probably, of other Enterobacteriaceae. Moreover, we defined general criteria to select good reference genes in bacteria. {\textcopyright} 2011 Hommais et al.}, author = {Hommais, Florence and Zghidi-Abouzid, Ouafa and Oger-Desfeux, Christine and Pineau-Chapelle, Emilie and van Gijsegem, Frederique and Nasser, William and Reverchon, Sylvie}, doi = {10.1371/journal.pone.0020269}, file = {:Users/navratil/Documents/Mendeley Desktop/2011/Hommais et al/PLoS ONE/PLoS ONE{\_}Hommais et al.{\_}LpxC and yafS are the most suitable internal controls to normalize real time RT-qPCR expression in the phytopath.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, number = {5}, pmid = {21637857}, publisher = {Public Library of Science}, title = {{LpxC and yafS are the most suitable internal controls to normalize real time RT-qPCR expression in the phytopathogenic bacteria dickeya dadantii}}, volume = {6}, year = {2011} } @article{Degletagne2010, abstract = {Background: Recent developments in high-throughput methods of analyzing transcriptomic profiles are promising for many areas of biology, including ecophysiology. However, although commercial microarrays are available for most common laboratory models, transcriptome analysis in non-traditional model species still remains a challenge. Indeed, the signal resulting from heterologous hybridization is low and difficult to interpret because of the weak complementarity between probe and target sequences, especially when no microarray dedicated to a genetically close species is available.Results: We show here that transcriptome analysis in a species genetically distant from laboratory models is made possible by using MAXRS, a new method of analyzing heterologous hybridization on microarrays. This method takes advantage of the design of several commercial microarrays, with different probes targeting the same transcript. To illustrate and test this method, we analyzed the transcriptome of king penguin pectoralis muscle hybridized to Affymetrix chicken microarrays, two organisms separated by an evolutionary distance of approximately 100 million years. The differential gene expression observed between different physiological situations computed by MAXRS was confirmed by real-time PCR on 10 genes out of 11 tested.Conclusions: MAXRS appears to be an appropriate method for gene expression analysis under heterologous hybridization conditions. {\textcopyright} 2010 Degletagne et al; licensee BioMed Central Ltd.}, author = {Degletagne, Cyril and Keime, C{\'{e}}line and Rey, Benjamin and de Dinechin, Marc and Forcheron, Fabien and Chuchana, Paul and Jouventin, Pierre and Gautier, Christian and Duchamp, Claude}, doi = {10.1186/1471-2164-11-344}, file = {:Users/navratil/Documents/Mendeley Desktop/2010/Degletagne et al/BMC Genomics/BMC Genomics{\_}Degletagne et al.{\_}Transcriptome analysis in non-model species A new method for the analysis of heterologous hybridization o.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Animals,Claude Duchamp,Cyril Degletagne,C{\'{e}}line Keime,Developmental,Fluorescence,Gene Expression Profiling / methods*,Gene Expression Regulation,MEDLINE,NCBI,NIH,NLM,National Center for Biotechnology Information,National Institutes of Health,National Library of Medicine,Non-U.S. Gov't,Nucleic Acid Hybridization / methods*,Oceans and Seas,Oligonucleotide Array Sequence Analysis / methods*,PMC2901317,Pectoralis Muscles / growth {\&} development,Pectoralis Muscles / metabolism,Polymerase Chain Reaction,PubMed Abstract,Reproducibility of Results,Research Support,Spectrometry,Spheniscidae / genetics,Spheniscidae / growth {\&} development,doi:10.1186/1471-2164-11-344,pmid:20509979}, month = {may}, number = {1}, pmid = {20509979}, publisher = {BMC Genomics}, title = {{Transcriptome analysis in non-model species: A new method for the analysis of heterologous hybridization on microarrays}}, url = {https://pubmed.ncbi.nlm.nih.gov/20509979/}, volume = {11}, year = {2010} } @article{Blaise2010, abstract = {The development of Statistical Total Correlation Spectroscopy (STOCSY), a representation of the autocorrelation matrix of a spectral data set as a 2D pseudospectrum, has allowed more reliable assignment of one- and two-dimensional NMR spectra acquired from the complex mixtures that are usually used in metabolomics/metabonomics studies, thus, improving precise identification of candidate biomarkers contained in metabolic signatures computed by multivariate statistical analysis. However, the correlations obtained cannot always be interpreted in terms of connectivities between metabolites. In this study, we combine statistical recoupling of variables (SRV) and STOCSY to identify perturbed metabolite systems. The resulting Recoupled-STOCSY (R-STOCSY) method provides a 2D correlation landscape based on the SRV clusters representing physical, chemical, and biological entities. This enables the identification of correlations between distant clusters and extends the recoupling scheme of SRV, which was previously limited to the association of neighboring clusters. This allows the recovery of only meaningful correlations between metabolic signals and significantly enhances the interpretation of STOCSY. The method is validated through the measurement of the distances between the metabolites involved in these correlations, within the whole metabolic network, which shows that the average shortest path length is significantly shorter for the correlations detected in this new way compared to metabolite couples randomly selected from within the entire KEGG metabolic network. This enables the identification without any a priori knowledge of the perturbed metabolic network. The R-STOCSY completes the recoupling procedure between distant clusters, further reducing the high dimensionality of metabolomics/metabonomics data set and finally allows the identification of composite biomarkers, highlighting disruption of particular metabolic pathways within a global metabolic network. This allows the perturbed metabolic network to be extracted through NMR based metabolomics/metabonomics in an automated, and statistical manner. {\textcopyright} 2010 American Chemical Society.}, author = {Blaise, Benjamin J. and Navratil, Vincent and Domange, C{\'{e}}line and Shintu, Laetitia and Dumas, Marc Emmanuel and Elena-Herrmann, B{\'{e}}n{\'{e}}dicte and Emsley, Lyndon and Toulhoat, Pierre}, doi = {10.1021/pr1002615}, issn = {15353893}, journal = {Journal of Proteome Research}, keywords = {NMR,STOCSY,metabolic profiling,network}, month = {sep}, number = {9}, pages = {4513--4520}, pmid = {20590164}, title = {{Two-dimensional statistical recoupling for the identification of perturbed metabolic networks from NMR spectroscopy}}, volume = {9}, year = {2010} } @article{Navratil2010, abstract = {Infection caused by pathogens kills millions of people every year. Comprehensive understanding of molecular pathogen-host interactions, i.e. the infectome, is one of the key steps towards the development of novel diagnostic, therapeutic and preventive strategies. In this quest, progress in high-throughput « omics » technologies applied to pathogens, i.e. infectomics, opens new perspectives toward systemic understanding of perturbations induced during infection. Deciphering the pathogen-host system also relies on the analytical and predictive power of molecular systems biology and by developing in silico models taking into account the whole picture of the molecules and their interactions. In this context, we have reconstructed a prototype of the human virtual infected cell based on 30 years of intensive research in the field of molecular virology. This model contains more than one hundred viral infectomes, including major human pathogens (HCV, HBV, HIV, HHV, HPV) and has led to the generation of novel systems-level hypotheses that could be suitable for the development of innovative antiviral strategies based on the control of cellular functions.}, author = {Navratil, Vincent and Lotteau, Vincent and Rabourdin-Combe, Chantal}, doi = {10.1051/medsci/2010266-7603}, file = {:Users/navratil/Documents/Mendeley Desktop/2010/Navratil, Lotteau, Rabourdin-Combe/MedecineSciences/MedecineSciences{\_}Navratil, Lotteau, Rabourdin-Combe{\_}The virtual infected cell A systems biology rational for antiviral drug discovery{\_}20.pdf:pdf}, issn = {07670974}, journal = {Medecine/Sciences}, number = {6-7}, pages = {603--609}, pmid = {20619162}, publisher = {Editions EDK}, title = {{The virtual infected cell: A systems biology rational for antiviral drug discovery}}, volume = {26}, year = {2010} } @article{Hunter2009, abstract = {The InterPro database (http://www.ebi.ac.uk/interpro/) integrates together predictive models or 'signatures' representing protein domains, families and functional sites from multiple, diverse source databases: Gene3D, PANTHER, Pfam, PIRSF, PRINTS, ProDom, PROSITE, SMART, SUPERFAMILY and TIGRFAMs. Integration is performed manually and approximately half of the total ∼ 58 000 signatures available in the source databases belong to an InterPro entry. Recently, we have started to also display the remaining un-integrated signatures via our web interface. Other developments include the provision of non-signature data, such as structural data, in new XML files on our FTP site, as well as the inclusion of matchless UniProtKB proteins in the existing match XML files. The web interface has been extended and now links out to the ADAN predicted protein-protein interaction database and the SPICE and Dasty viewers. The latest public release (v18.0) covers 79.8{\%} of UniProtKB (v14.1) and consists of 16 549 entries. InterPro data may be accessed either via the web address above, via web services, by downloading files by anonymous FTP or by using the InterProScan search software (http://www.ebi.ac.uk/Tools/InterProScan/). {\textcopyright} 2008 The Author(s).}, author = {Hunter, Sarah and Apweiler, Rolf and Attwood, Teresa K. and Bairoch, Amos and Bateman, Alex and Binns, David and Bork, Peer and Das, Ujjwal and Daugherty, Louise and Duquenne, Lauranne and Finn, Robert D. and Gough, Julian and Haft, Daniel and Hulo, Nicolas and Kahn, Daniel and Kelly, Elizabeth and Laugraud, Aur{\'{e}}lie and Letunic, Ivica and Lonsdale, David and Lopez, Rodrigo and Madera, Martin and Maslen, John and Mcanulla, Craig and McDowall, Jennifer and Mistry, Jaina and Mitchell, Alex and Mulder, Nicola and Natale, Darren and Orengo, Christine and Quinn, Antony F. and Selengut, Jeremy D. and Sigrist, Christian J.A. and Thimma, Manjula and Thomas, Paul D. and Valentin, Franck and Wilson, Derek and Wu, Cathy H. and Yeats, Corin}, doi = {10.1093/nar/gkn785}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Hunter et al/Nucleic Acids Research/Nucleic Acids Research{\_}Hunter et al.{\_}InterPro The integrative protein signature database{\_}2009(2).pdf:pdf}, issn = {03051048}, journal = {Nucleic Acids Research}, number = {SUPPL. 1}, pmid = {18940856}, title = {{InterPro: The integrative protein signature database}}, volume = {37}, year = {2009} } @article{Deniaud2009, abstract = {Background: The ubiquitous transcription factor Sp1 regulates the expression of a vast number of genes involved in many cellular functions ranging from differentiation to proliferation and apoptosis. Sp1 expression levels show a dramatic increase during transformation and this could play a critical role for tumour development or maintenance. Although Sp1 deregulation might be beneficial for tumour cells, its overexpression induces apoptosis of untransformed cells. Here we further characterised the functional and transcriptional responses of untransformed cells following Sp1 overexpression. Methodology and Principal Findings: We made use of wild-type and DNA-binding-deficient Sp1 to demonstrate that the induction of apoptosis by Sp1 is dependent on its capacity to bind DNA. Genome-wide expression profiling identified genes involved in cancer, cell death and cell cycle as being enriched among differentially expressed genes following Sp1 overexpression. In silico search to determine the presence of Sp1 binding sites in the promoter region of modulated genes was conducted. Genes that contained Sp1 binding sites in their promoters were enriched among down-regulated genes. The endogenous sp1 gene is one of the most down-regulated suggesting a negative feedback loop induced by overexpressed Sp1. In contrast, genes containing Sp1 binding sites in their promoters were not enriched among up-regulated genes. These results suggest that the transcriptional response involves both direct Sp1-driven transcription and indirect mechanisms. Finally, we show that Sp1 overexpression led to a modified expression of G1/S transition regulatory genes such as the down-regulation of cyclin D2 and the up-regulation of cyclin G2 and cdkn2c/p18 expression. The biological significance of these modifications was confirmed by showing that the cells accumulated in the G1 phase of the cell cycle before the onset of apoptosis. Conclusion: This study shows that the binding to DNA of overexpressed Sp1 induces an inhibition of cell cycle progression that precedes apoptosis and a transcriptional response targeting genes containing Sp1 binding sites in their promoter or not suggesting both direct Sp1-driven transcription and indirect mechanisms. {\textcopyright} 2009 Deniaud et al.}, author = {Deniaud, Emmanuelle and Baguet, Jo{\"{e}}l and Chalard, Roxane and Blanquier, Bariza and Brinza, Lilia and Meunier, Julien and Michallet, Marie C{\'{e}}cile and Laugraud, Aur{\'{e}}lie and Ah-Soon, Claudette and Wierinckx, Anne and Castellazzi, Marc and Lachuer, Jo{\"{e}}l and Gautier, Christian and Marvel, Jacqueline and Leverrier, Yann}, doi = {10.1371/journal.pone.0007035}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Deniaud et al/PLoS ONE/PLoS ONE{\_}Deniaud et al.{\_}Overexpression of transcription factor Sp1 leads to gene expression perturbations and cell cycle inhibition{\_}2009.pdf:pdf}, issn = {19326203}, journal = {PLoS ONE}, month = {sep}, number = {9}, pmid = {19753117}, title = {{Overexpression of transcription factor Sp1 leads to gene expression perturbations and cell cycle inhibition}}, volume = {4}, year = {2009} } @article{Horard2009, abstract = {Half of the human genome consists of repetitive DNA sequences. Recent studies in various organisms highlight the role of chromatin regulation of repetitive DNA in gene regulation as well as in maintainance of chromosomes and genome integrity. Hence, repetitive DNA sequences might be potential "sensors" for chromatin changes associated with pathogenesis. Therefore, we developed a new genomic tool called RepArray. RepArray is a repeat-specific microarray composed of a representative set of human repeated sequences including transposon-derived repeats, simple sequences repeats, tandemly repeated sequences such as centromeres and telomeres. We showed that combined to anti-methylcytosine immunoprecipitation assay, the RepArray can be used to generate repeat-specific methylation maps. Using cell lines impaired chemically or genetically for DNA methyltransferases activities, we were able to distinguish different epigenomes demonstrating that repeats can be used as markers of genome-wide methylation changes. Besides, using a well-documented system model, the thermal stress, we demonstrated that RepArray is also a fast and reliable tool to obtain an overview of overall transcriptional activity on whole repetitive compartment in a given cell type. Thus, the RepArray represents the first valuable tool for systematic and genome-wide analyses of the methylation and transcriptional status of the repetitive counterpart of the human genome. {\textcopyright} 2009 Landes Bioscience.}, author = {Horard, B{\'{e}}atrice and Eymery, Ang{\'{e}}line and Fourel, Genevi{\`{e}}ve and Vassetzky, Nikita and Puechberty, Jacques and Roizes, G{\'{e}}rard and Lebrigand, Kevin and Barbry, Pascal and Laugraud, Aur{\'{e}}lie and Gautier, Christian and Simon, Elisa Ben and Devaux, Fr{\'{e}}d{\'{e}}ric and Magdinier, Fr{\'{e}}d{\'{e}}rique and Vourc'h, Claire and Gilson, Eric}, doi = {10.4161/epi.4.5.9284}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Horard et al/Epigenetics/Epigenetics{\_}Horard et al.{\_}Global analysis of DNA methylation and transcription of human repetitive sequences{\_}2009.pdf:pdf}, issn = {15592308}, journal = {Epigenetics}, keywords = {DNA methylation,Epigenetic,Human repetitive DNA,Microarray,Non coding transcripts}, month = {jul}, number = {5}, pages = {66--77}, pmid = {19633427}, publisher = {Taylor and Francis Inc.}, title = {{Global analysis of DNA methylation and transcription of human repetitive sequences}}, volume = {4}, year = {2009} } @article{Navratil2009, abstract = {Infectious diseases caused by viral agents kill millions of people every year. The improvement of prevention and treatment of viral infections and their associated diseases remains one of the main public health challenges. Towards this goal, deciphering virus-host molecular interactions opens new perspectives to understand the biology of infection and for the design of new antiviral strategies. Indeed, modelling of an infection network between viral and cellular proteins will provide a conceptual and analytic framework to efficiently formulate new biological hypothesis at the proteome scale and to rationalize drug discovery. Therefore, we present the first release of VirHostNet (Virus-Host Network), a public knowledge base specialized in the management and analysis of integrated virus-virus, virus-host and host-host interaction networks coupled to their functional annotations. VirHostNet integrates an extensive and original literature-curated dataset of virus-virus and virus-host interactions (2671 non-redundant interactions) representing more than 180 distinct viral species and one of the largest human interactome (10 672 proteins and 68 252 non-redundant interactions) reconstructed from publicly available data. The VirHostNet Web interface provides appropriate tools that allow efficient query and visualization of this infected cellular network. Public access to the VirHostNet knowledge-based system is available at http://pbildb1.univ-lyon1.fr/virhostnet. {\textcopyright} 2008 The Author(s).}, author = {Navratil, Vincent and De chassey, Beno{\^{i}}t and Meyniel, Laur{\`{e}}ne and Delmotte, St{\'{e}}phane and Gautier, Christian and Andr{\'{e}}, Patrice and Lotteau, Vincent and Rabourdin-Combe, Chantal}, doi = {10.1093/nar/gkn794}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Navratil et al/Nucleic Acids Research/Nucleic Acids Research{\_}Navratil et al.{\_}VirHostNet A knowledge base for the management and the analysis of proteome-wide virus-host inter.pdf:pdf}, issn = {03051048}, journal = {Nucleic Acids Research}, number = {SUPPL. 1}, pmid = {18984613}, title = {{VirHostNet: A knowledge base for the management and the analysis of proteome-wide virus-host interaction networks}}, volume = {37}, year = {2009} } @article{Pellet2009, abstract = {Abstract. Background. High-throughput screening of protein-protein interactions opens new systems biology perspectives for the comprehensive understanding of cell physiology in normal and pathological conditions. In this context, yeast two-hybrid system appears as a promising approach to efficiently reconstruct protein interaction networks at the proteome-wide scale. This protein interaction screening method generates a large amount of raw sequence data, i.e. the ISTs (Interaction Sequence Tags), which urgently need appropriate tools for their systematic and standardised analysis. Findings. We develop pISTil, a bioinformatics pipeline combined with a user-friendly web-interface: (i) to establish a standardised system to analyse and to annotate ISTs generated by two-hybrid technologies with high performance and flexibility and (ii) to provide high-quality protein-protein interaction datasets for systems-level approach. This pipeline has been validated on a large dataset comprising more than 11.000 ISTs. As a case study, a detailed analysis of ISTs obtained from yeast two-hybrid screens of Hepatitis C Virus proteins against human cDNA libraries is also provided. Conclusion. We have developed pISTil, an open source pipeline made of a collection of several applications governed by a Perl script. The pISTil pipeline is intended to laboratories, with IT-expertise in system administration, scripting and database management, willing to automatically process large amount of ISTs data for accurate reconstruction of protein interaction networks in a systems biology perspective. pISTil is publicly available for download at http://sourceforge.net/projects/pistil. {\textcopyright} 2009 Navratil et al; licensee BioMed Central Ltd.}, author = {Pellet, Johann and Meyniel, Laur{\`{e}}ne and Vidalain, Pierre Olivier and {De Chassey}, Benot and Tafforeau, Lionel and Lotteau, Vincent and Rabourdin-Combe, Chantal and Navratil, Vincent}, doi = {10.1186/1756-0500-2-220}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Pellet et al/BMC Research Notes/BMC Research Notes{\_}Pellet et al.{\_}PISTil A pipeline for yeast two-hybrid Interaction Sequence Tags identification and analysis{\_}2009.pdf:pdf}, issn = {17560500}, journal = {BMC Research Notes}, title = {{PISTil: A pipeline for yeast two-hybrid Interaction Sequence Tags identification and analysis}}, volume = {2}, year = {2009} } @article{Moccia2009, abstract = {Background: Expressed sequence tag (EST) databases represent a valuable resource for the identification of genes in organisms with uncharacterized genomes and for development of molecular markers. One class of markers derived from EST sequences are simple sequence repeat (SSR) markers, also known as EST-SSRs. These are useful in plant genetic and evolutionary studies because they are located in transcribed genes and a putative function can often be inferred from homology searches. Another important feature of EST-SSR markers is their expected high level of transferability to related species that makes them very promising for comparative mapping. In the present study we constructed a normalized EST library from floral tissue of Silene latifolia with the aim to identify expressed genes and to develop polymorphic molecular markers. Results: We obtained a total of 3662 high quality sequences from a normalized Silene cDNA library. These represent 3105 unigenes, with 73{\%} of unigenes matching genes in other species. We found 255 sequences containing one or more SSR motifs. More than 60{\%} of these SSRs were trinucleotides. A total of 30 microsatellite loci were identified from 106 ESTs having sufficient flanking sequences for primer design. The inheritance of these loci was tested via segregation analyses and their usefulness for linkage mapping was assessed in an interspecific cross. Tests for crossamplification of the EST-SSR loci in other Silene species established their applicability to related species. Conclusion: The newly characterized genes and gene-derived markers from our Silene EST library represent a valuable genetic resource for future studies on Silene latifolia and related species. The polymorphism and transferability of EST-SSR markers facilitate comparative linkage mapping and analyses of genetic diversity in the genus Silene. {\textcopyright} 2009 Moccia et al; licensee BioMed Central Ltd.}, author = {Moccia, Maria Domenica and Oger-Desfeux, Christine and Marais, Gabriel A.B. and Widmer, Alex}, doi = {10.1186/1471-2164-10-243}, file = {:Users/navratil/Documents/Mendeley Desktop/2009/Moccia et al/BMC Genomics/BMC Genomics{\_}Moccia et al.{\_}A white campion (Silene latifolia) floral expressed sequence tag (EST) library Annotation, EST-SSR characteri.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, month = {may}, pmid = {19467153}, title = {{A white campion (Silene latifolia) floral expressed sequence tag (EST) library: Annotation, EST-SSR characterization, transferability, and utility for comparative mapping}}, volume = {10}, year = {2009} } @article{Hanriot2008, abstract = {Background: "Open" transcriptome analysis methods allow to study gene expression without a priori knowledge of the transcript sequences. As of now, SAGE (Serial Analysis of Gene Expression), LongSAGE and MPSS (Massively Parallel Signature Sequencing) are the mostly used methods for "open" transcriptome analysis. Both LongSAGE and MPSS rely on the isolation of 21 pb tag sequences from each transcript. In contrast to LongSAGE, the high throughput sequencing method used in MPSS enables the rapid sequencing of very large libraries containing several millions of tags, allowing deep transcriptome analysis. However, a bias in the complexity of the transcriptome representation obtained by MPSS was recently uncovered. Results: In order to make a deep analysis of mouse hypothalamus transcriptome avoiding the limitation introduced by MPSS, we combined LongSAGE with the Solexa sequencing technology and obtained a library of more than 11 millions of tags. We then compared it to a LongSAGE library of mouse hypothalamus sequenced with the Sanger method. Conclusion: We found that Solexa sequencing technology combined with LongSAGE is perfectly suited for deep transcriptome analysis. In contrast to MPSS, it gives a complex representation of transcriptome as reliable as a LongSAGE library sequenced by the Sanger method. {\textcopyright} 2008 Hanriot et al; licensee BioMed Central Ltd.}, author = {Hanriot, Lucie and Keime, C{\'{e}}line and Gay, Nadine and Faure, Claudine and Dossat, Carole and Wincker, Patrick and Scot{\'{e}}-Blachon, C{\'{e}}line and Peyron, Christelle and Gandrillon, Olivier}, doi = {10.1186/1471-2164-9-418}, file = {:Users/navratil/Documents/Mendeley Desktop/2008/Hanriot et al/BMC Genomics/BMC Genomics{\_}Hanriot et al.{\_}A combination of LongSAGE with Solexa sequencing is well suited to explore the depth and the complexity of t.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, keywords = {Animals,C{\'{e}}line Keime,DNA / methods*,Evaluation Study,Gene Expression Profiling / methods*,Gene Library,Hypothalamus / metabolism,Inbred Strains,Lucie Hanriot,MEDLINE,Male,Mice,NCBI,NIH,NLM,National Center for Biotechnology Information,National Institutes of Health,National Library of Medicine,Olivier Gandrillon,PMC2562395,PubMed Abstract,Sequence Analysis,doi:10.1186/1471-2164-9-418,pmid:18796152}, month = {sep}, pmid = {18796152}, publisher = {BioMed Central Ltd.}, title = {{A combination of LongSAGE with Solexa sequencing is well suited to explore the depth and the complexity of transcriptome}}, url = {https://pubmed.ncbi.nlm.nih.gov/18796152/}, volume = {9}, year = {2008} } @article{Stockinger2008, abstract = {Programmatic access to data and tools through the web using so-called web services has an important role to play in bioinformatics. In this article, we discuss the most popular approaches based on SOAP/WS-I and REST and describe our, a cross section of the community, experiences with providing and using web services in the context of biological sequence analysis. We briefly review main technological approaches as well as best practice hints that are useful for both users and developers. Finally, syntactic and semantic data integration issues with multiple web services are discussed. {\textcopyright} The Author 2008. Published by Oxford University Press.}, author = {Stockinger, Heinz and Attwood, Teresa and Chohan, Shahid Nadeem and C{\^{o}}t{\'{e}}, Richard and Cudr{\'{e}}-Mauroux, Philippe and Falquet, Laurent and Fernandes, Pedro and Finn, Robert D. and Hupponen, Taavi and Korpelainen, Eija and Labarga, Alberto and Laugraud, Aurelie and Lima, Tania and Pafilis, Evangelos and Pagni, Marco and Pettifer, Steve and Phan, Isabelle and Rahman, Nazim}, doi = {10.1093/bib/bbn029}, file = {:Users/navratil/Documents/Mendeley Desktop/2008/Stockinger et al/Briefings in Bioinformatics/Briefings in Bioinformatics{\_}Stockinger et al.{\_}Experience using web services for biological sequence analysis{\_}2008.pdf:pdf}, issn = {14675463}, journal = {Briefings in Bioinformatics}, keywords = {Internet technologies,REST,SOAP,Sequence analysis,Web services}, number = {6}, pages = {493--505}, pmid = {18621748}, title = {{Experience using web services for biological sequence analysis}}, volume = {9}, year = {2008} } @article{Kojadinovic2008, abstract = {In the purple photosynthetic bacterium Rhodopseudomonas palustris, far-red illumination induces photosystem synthesis via the action of the bacteriophytochrome RpBphP1. This bacteriophytochrome antagonizes the repressive effect of the transcriptional regulator PpsR2 under aerobic condition. We show here that, in addition to photosystem synthesis, far-red light induces a significant growth rate limitation, compared to cells grown in the dark, linked to a decrease in the respiratory activity. The phenotypes of mutants inactivated in RpBphP1 and PpsR2 show their involvement in this regulation. Based on enzymatic and transcriptional studies, a 30{\%} decrease in the expression of the alpha-ketoglutarate dehydrogenase complex, a central enzyme of the Krebs cycle, is observed under far-red light. We propose that this decrease is responsible for the down-regulation of respiration in this condition. This regulation mechanism at the Krebs cycle level still allows the formation of the photosynthetic apparatus via the synthesis of key biosynthesis precursors but lowers the production of NADH, i.e. the respiratory activity. Overall, the dual action of RpBphP1 on the regulation of both the photosynthesis genes and the Krebs cycle allows a fine adaptation of bacteria to environmental conditions by enhancement of the most favorable bioenergetic process in the light, photosynthesis versus respiration. {\textcopyright} 2007 Elsevier B.V. All rights reserved.}, author = {Kojadinovic, Mila and Laugraud, Aur{\'{e}}lie and Vuillet, Laurie and Fardoux, Jo{\"{e}}l and Hannibal, Laure and Adriano, Jean Marc and Bouyer, Pierre and Giraud, Eric and Verm{\'{e}}glio, Andr{\'{e}}}, doi = {10.1016/j.bbabio.2007.09.003}, file = {:Users/navratil/Documents/Mendeley Desktop/2008/Kojadinovic et al/Biochimica et Biophysica Acta - Bioenergetics/Biochimica et Biophysica Acta - Bioenergetics{\_}Kojadinovic et al.{\_}Dual role for a bacteriophytochrome in the bioenergetic control of Rhod.pdf:pdf}, issn = {00052728}, journal = {Biochimica et Biophysica Acta - Bioenergetics}, keywords = {Alpha-ketoglutarate,Bacteriophytochrome,Photosynthesis,Regulation,Respiration,Rhodopseudomonas palustris}, month = {feb}, number = {2}, pages = {163--172}, pmid = {17988648}, title = {{Dual role for a bacteriophytochrome in the bioenergetic control of Rhodopsdeudomonas palustris: Enhancement of photosystem synthesis and limitation of respiration}}, volume = {1777}, year = {2008} } @article{Ghayad2008, abstract = {Activation of the Akt/mammalian target of rapamycin (mTOR) pathway has been shown to be associated with resistance to endocrine therapy in estrogen receptor alpha (ER$\alpha$)-positive breast cancer patients. Utmost importance is attached to strategies aimed at overcoming treatment resistance. In this context, this work aimed to investigate whether, in breast cancer cells, the use of an mTOR inhibitor would be sufficient to reverse the resistance acquired after exposure to endocrine therapy. The ER$\alpha$-positive human breast adenocarcinoma derived-MCF-7 cells used in this study have acquired both cross-resistance to hydroxy-tamoxifen (OH-Tam) and to fulvestrant and strong activation of the Akt/mTOR pathway. Cell proliferation tests in control cells demonstrated that the mTOR inhibitor rapamycin enhanced cell sensitivity to endocrine therapy when combined to OH-Tam or to fulvestrant. In resistant cells, rapamycin used alone greatly inhibited cell proliferation and reversed resistance to endocrine therapy by blocking the agonist-like activity of OH-Tam on cell proliferation and bypassing fulvestrant resistance. Reversion of resistance by rapamycin was associated with increased ER$\alpha$ protein expression levels and modification of the balance of phospho-ser167 ER$\alpha$/total ER$\alpha$ ratio. Pangenomic DNA array experiments demonstrated that the cotreatment of resistant cells with fulvestrant and rapamycin allowed the restoration of 40{\%} of the fulvestrant gene-expression signature. Taken together, data presented herein strongly support the idea that mTOR inhibitor might be one of the promising therapeutic approaches for patients with ER$\alpha$-positive endocrine therapy-resistant breast cancers. {\textcopyright} 2008 Japanese Cancer Association.}, author = {Ghayad, Sandra E. and Bieche, Ivan and Vendrell, Julie A. and Keime, Celine and Lidereau, Rosette and Dumontet, Charles and Cohen, Pascale A.}, doi = {10.1111/j.1349-7006.2008.00955.x}, file = {:Users/navratil/Documents/Mendeley Desktop/2008/Ghayad et al/Cancer Science/Cancer Science{\_}Ghayad et al.{\_}mTOR inhibition reverses acquired endocrine therapy resistance of breast cancer cells at the cell prolifera.pdf:pdf}, issn = {13497006}, journal = {Cancer Science}, number = {10}, pages = {1992--2003}, pmid = {19016759}, publisher = {Blackwell Publishing Ltd}, title = {{mTOR inhibition reverses acquired endocrine therapy resistance of breast cancer cells at the cell proliferation and gene-expression levels}}, volume = {99}, year = {2008} } @article{Navratil2008, abstract = {Single nucleotide polymorphisms (SNPs), which are the most abundant form of genetic variations in numerous organisms, have emerged as important tools for the study of complex genetic traits and deciphering of genome evolution. High-throughput genome sequencing projects worldwide provide an unprecedented opportunity for whole-genome SNP analysis in a variety of species. To facilitate SNP discovery in vertebrates, we have developed a web-based, user-friendly, and fully automated application, DigiPINS, for genome-wide identification of exonic SNPs from EST data. Currently, the database can be used to the mining of exonic SNPs in six complete genomes (Homo sapiens, Mus musculus, Rattus norvegicus, Canis familiaris, Gallus gallus and Danio rerio). In addition to providing information on sequence conservation, DigiPINS allows compilation of comprehensive sets of polymorphisms within cancer candidate genes or identification of novel cancer markers, making it potentially useful for cancer association studies. The DigiPINS server is available via the internet at http://pbil.univ-lyon1.fr/gem/DigiPINS/query{\_}DigiPINS.php. {\textcopyright} 2007 Elsevier Masson SAS. All rights reserved.}, author = {Navratil, Vincent and Penel, Simon and Delmotte, St{\'{e}}phane and Mouchiroud, Dominique and Gautier, Christian and Aouacheria, Abdel}, doi = {10.1016/j.biochi.2007.09.017}, issn = {03009084}, journal = {Biochimie}, keywords = {Cancer association,Comparative genomics,Expressed sequenced tag,Single nucleotide polymorphism,Web server}, month = {apr}, number = {4}, pages = {563--569}, pmid = {17988782}, title = {{DigiPINS: A database for vertebrate exonic single nucleotide polymorphisms and its application to cancer association studies}}, volume = {90}, year = {2008} } @article{Hommais2008, abstract = {Pathogenicity of the enterobacterium Erwinia chrysanthemi (Dickeya dadantii), the causative agent of soft-rot disease in many plants, is a complex process involving several factors whose production is subject to temporal regulation during infection. PecS is a transcriptional regulator that controls production of various virulence factors. Here, we used microarray analysis to define the PecS regulon and demonstrated that PecS notably regulates a wide range of genes that could be linked to pathogenicity and to a group of genes concerned with evading host defenses. Among the targets are the genes encoding plant cell wall-degrading enzymes and secretion systems and the genes involved in flagellar biosynthesis, biosurfactant production, and the oxidative stress response, as well as genes encoding toxin-like factors such as NipE and hemolysin-coregulated proteins. In vitro experiments demonstrated that PecS interacts with the regulatory regions of five new targets: an oxidative stress response gene (ahpC), a biosurfactant synthesis gene (rhlA), and genes encoding exported proteins related to other plant-associated bacterial proteins (nipE, virK, and avrL). The pecS mutant provokes symptoms more rapidly and with more efficiency than the wild-type strain, indicating that PecS plays a critical role in the switch from the asymptomatic phase to the symptomatic phase. Based on this, we propose that the temporal regulation of the different groups of genes required for the asymptomatic phase and the symptomatic phase is, in part, the result of a gradual modulation of PecS activity triggered during infection in response to changes in environmental conditions emerging from the interaction between both partners. Copyright {\textcopyright} 2008, American Society for Microbiology. All Rights Reserved.}, author = {Hommais, Florence and Oger-Desfeux, Christine and {Van Gijsegem}, Fr{\'{e}}d{\'{e}}rique and Castang, Sandra and Ligori, Sandrine and Expert, Dominique and Nasser, William and Reverchon, Sylvie}, doi = {10.1128/JB.00553-08}, file = {:Users/navratil/Documents/Mendeley Desktop/2008/Hommais et al/Journal of Bacteriology/Journal of Bacteriology{\_}Hommais et al.{\_}PecS is a global regulator of the symptomatic phase in the phytopathogenic bacterium Erwinia chry.pdf:pdf}, issn = {00219193}, journal = {Journal of Bacteriology}, number = {22}, pages = {7508--7522}, pmid = {18790868}, publisher = {American Society for Microbiology}, title = {{PecS is a global regulator of the symptomatic phase in the phytopathogenic bacterium Erwinia chrysanthemi 3937}}, volume = {190}, year = {2008} } @article{Aouacheria2007, abstract = {Background: A promising application of the huge amounts of genetic data currently available lies in developing a better understanding of complex diseases, such as cancer. Analysis of publicly available databases can help identify potential candidates for genes or mutations specifically related to the cancer phenotype. In spite of their huge potential to affect gene function, no systematic attention has been paid so far to the changes that occur in untranslated regions of mRNA. Results: In this study, we used Expressed Sequence Tag (EST) databases as a source for cancer-related sequence polymorphism discovery at the whole-genome level. Using a novel computational procedure, we focused on the identification of untranslated region (UTR)-localized non-coding Single Nucleotide Polymorphisms (UTR-SNPs) significantly associated with the tumoral state. To explore possible relationships between genetic mutation and phenotypic variation, bioinformatic tools were used to predict the potential impact of cancer-associated UTR-SNPs on mRNA secondary structure and UTR regulatory elements. We provide a comprehensive and unbiased description of cancer-associated UTR-SNPs that may be useful to define genotypic markers or to propose polymorphisms that can act to alter gene expression levels. Our results suggest that a fraction of cancer-associated UTR-SNPs may have functional consequences on mRNA stability and/or expression. Conclusion: We have ndertaken a comprehensive effort to identify cancer-associated polymorphisms in untranslated regions of mRNA and to characterize putative functional UTR-SNPs. Alteration of translational control can change the expression of genes in tumor cells, causing an increase or decrease in the concentration of specific proteins. Through the description of testable candidates and the experimental validation of a number of UTR-SNPs discovered on the secreted protein acidic and rich in cysteine (SPARC) gene, this report illustrates the utility of a cross-talk between in silico transcriptomics and cancer genetics. {\textcopyright} 2007 Aouacheria et al; licensee BioMed Central Ltd.}, author = {Aouacheria, Abdel and Navratil, Vincent and L{\'{o}}pez-P{\'{e}}rez, Ricardo and Guti{\'{e}}rrez, Norma C. and Churkin, Alexander and Barash, Danny and Mouchiroud, Dominique and Gautier, Christian}, doi = {10.1186/1471-2164-8-2}, file = {:Users/navratil/Documents/Mendeley Desktop/2007/Aouacheria et al/BMC Genomics/BMC Genomics{\_}Aouacheria et al.{\_}In silico whole-genome screening for cancer-related single-nucleotide polymorphisms located in human mRNA.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, pmid = {17201911}, title = {{In silico whole-genome screening for cancer-related single-nucleotide polymorphisms located in human mRNA untranslated regions}}, volume = {8}, year = {2007} } @article{Gautier2007, abstract = {To evaluate and compare the extent of LD in cattle, 1536 SNPs, mostly localized on BTA03, were detected in silico from available sequence data using two different methods and genotyped on samples from 14 distinct breeds originating from Europe and Africa. Only 696 SNPs could be validated, confirming the importance of trace-quality information for the in silico detection. Most of the validated SNPs were informative in several breeds and were used for a detailed description of their genetic structure and relationships. Results obtained were in agreement with previous studies performed on microsatellite markers and using larger samples. In addition, the majority of the validated SNPs could be mapped precisely, reaching an average density of one marker every 311 kb. This allowed us to analyze the extent of LD in the different breeds. Decrease of LD with physical distance across breeds revealed footprints of ancestral LD at short distances ({\textless}10 kb). As suggested by the haplotype block structure, these ancestral blocks are organized, within a breed, into larger blocks of a few hundred kilobases. In practice, such a structure similar to that already reported in dogs makes it possible to develop a chip of ,300,000 SNPs, which should be efficient for mapping purposes in most cattle breeds. Copyright {\textcopyright} 2007 by the Genetics Society of America.}, author = {Gautier, Mathieu and Faraut, Thomas and Moazami-Goudarzi, Katayoun and Navratil, Vincent and Foglio, Mario and Grohs, C{\'{e}}cile and Boland, Anne and Garnier, Jean Guillaume and Boichard, Didier and Lathrop, G. Mark and Gut, Ivo G. and Eggen, Andr{\'{e}}}, doi = {10.1534/genetics.107.075804}, file = {:Users/navratil/Documents/Mendeley Desktop/2007/Gautier et al/Genetics/Genetics{\_}Gautier et al.{\_}Genetic and haplotypic structure in 14 European and African cattle breeds{\_}2007.pdf:pdf}, issn = {00166731}, journal = {Genetics}, month = {oct}, number = {2}, pages = {1059--1070}, pmid = {17720924}, title = {{Genetic and haplotypic structure in 14 European and African cattle breeds}}, volume = {177}, year = {2007} } @article{Aouacheria2006a, abstract = {Background: Owing to the explosion of information generated by human genomics, analysis of publicly available databases can help identify potential candidate genes relevant to the cancerous phenotype. The aim of this study was to scan for such genes by whole-genome in silico subtraction using Expressed Sequence Tag (EST) data. Methods: Genes differentially expressed in normal versus tumor tissues were identified using a computer-based differential display strategy. Bcl-xL, an anti-apoptotic member of the Bcl-2 family, was selected for confirmation by western blot analysis. Results: Our genome-wide express ion analysis identified a set of genes whose differential expression may be attributed to the genetic alterations associated with tumor formation and malignant growth. We propose complete lists of genes that may serve as targets for projects seeking novel candidates for cancer diagnosis and therapy. Our validation result showed increased protein levels of Bcl-xL in two different liver cancer specimens compared to normal liver. Notably, our EST-based data mining procedure indicated that most of the changes in gene expression observed in cancer cells corresponded to gene inactivation patterns. Chromosomes and chromosomal regions most frequently associated with aberrant expression changes in cancer libraries were also determined. Conclusion: Through the description of several candidates (including genes encoding extracellular matrix and ribosomal components, cytoskeletal proteins, apoptotic regulators, and novel tissue-specific biomarkers), our study illustrates the utility of in silico transcriptomics to identify tumor cell signatures, tumor-related genes and chromosomal regions frequently associated with aberrant expression in cancer. {\textcopyright} 2006 Aouacheria et al; licensee BioMed Central Ltd.}, author = {Aouacheria, Abdel and Navratil, Vincent and Barthelaix, Audrey and Mouchiroud, Dominique and Gautier, Christian}, doi = {10.1186/1471-2164-7-94}, file = {:Users/navratil/Documents/Mendeley Desktop/2006/Aouacheria et al/BMC Genomics/BMC Genomics{\_}Aouacheria et al.{\_}Bioinformatic screening of human ESTs for differentially expressed genes in normal and tumor tissues{\_}2006.pdf:pdf}, issn = {14712164}, journal = {BMC Genomics}, month = {apr}, pmid = {16640784}, title = {{Bioinformatic screening of human ESTs for differentially expressed genes in normal and tumor tissues}}, volume = {7}, year = {2006} } @article{Sanguin2006, abstract = {The microarray approach has been proposed for high throughput analysis of the microbial community by providing snapshots of the microbial diversity under different environmental conditions. For this purpose, a prototype of a 16S rRNA-based taxonomic microarray was developed and evaluated for assessing bacterial community diversity. The prototype microarray is composed of 122 probes that target bacteria at various taxonomic levels from phyla to species (mostly Alphaproteobacteria). The prototype microarray was first validated using bacteria in pure culture. Differences in the sequences of probes and potential target DNAs were quantified as weighted mismatches (WMM) in order to evaluate hybridization reliability. As a general feature, probes having a WMM {\textgreater} 2 with target DNA displayed only 2.8{\%} false positives. The prototype microarray was subsequently tested with an environmental sample, which consisted of an Agrobacterium-related polymerase chain reaction amplicon from a maize rhizosphere bacterial community. Microarray results were compared to results obtained by cloning-sequencing with the same DNA. Microarray analysis enabled the detection of all 16S rRNA gene sequences found by cloning-sequencing. Sequences representing only 1.7{\%} of the clone library were detected. In conclusion, this prototype 16S rRNA-based taxonomic microarray appears to be a promising tool for the analysis of Alphaproteobacteria in complex ecosystems. {\textcopyright} 2005 Society for Applied Microbiology and Blackwell Publishing Ltd.}, author = {Sanguin, Herv{\'{e}} and Herrera, Aude and Oger-Desfeux, Christine and Dechesne, Arnaud and Simonet, Pascal and Navarro, Elisabeth and Vogel, Timothy M. and Mo{\"{e}}nne-Loccoz, Yvan and Nesme, Xavier and Grundmann, Genevi{\`{e}}ve L.}, doi = {10.1111/j.1462-2920.2005.00895.x}, issn = {14622920}, journal = {Environmental Microbiology}, number = {2}, pages = {289--307}, pmid = {16423016}, publisher = {Blackwell Publishing Ltd}, title = {{Development and validation of a prototype 16S rRNA-based taxonomic microarray for Alphaproteobacteria}}, volume = {8}, year = {2006} } @techreport{ArticoBanho2020, author = {{Artico Banho}, Cecilia}, file = {:Users/navratil/Documents/Mendeley Desktop/2020/Artico Banho/Unknown/Unknown{\_}Artico Banho{\_}Deregulation of genes and transposable elements and hybrid incompatibility among Drosophila mojavensis subspecies a.pdf:pdf}, title = {{Deregulation of genes and transposable elements and hybrid incompatibility among Drosophila mojavensis subspecies and D. arizonae}}, url = {https://tel.archives-ouvertes.fr/tel-03303079}, year = {2020} }
.
.
,
. doi:
powered by
Partenaires
×